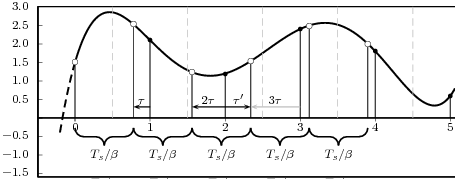
|
|
| © Presses polytechniques et universitaires romandes, 2008 All rights reserved |
The present text evolved from course notes developed over a period of a
dozen years teaching undergraduates the basics of signal processing for
communications. The students had mostly a background in electrical
engineering, computer science or mathematics, and were typically
in their third year of studies at Ecole Polytechnique Fédérale de
Lausanne (EPFL), with an interest in communication systems. Thus, they
had been exposed to signals and systems, linear algebra, elements of
analysis (e.g. Fourier series) and some complex analysis, all of this
being fairly standard in an undergraduate program in engineering
sciences.
The notes having reached a certain maturity, including examples, solved
problems and exercises, we decided to turn them into an easy-to-use text on
signal processing, with a look at communications as an application. But
rather than writing one more book on signal processing, of which
many good ones already exist, we deployed the following variations,
which we think will make the book appealing as an undergraduate
text.
While mathematical rigor is not the emphasis, we made sure
to be precise, and thus the text is not approximate in its use
of mathematics. Remember, we think signal processing to be
mathematics applied to a fun topic, and not mathematics for its
own sake, nor a set of applications without foundations.
Certainly, the masterpiece in this regard is C. Shannon’s
1948 foundational paper on “The Mathematical Theory
of Communication”. It completely revolutionized the way
communication systems are designed and built, and, still today,
we mostly live in its legacy. Not surprisingly, one of the key
results of signal processing is the sampling theorem for bandlimited
functions (often attributed to Shannon, since it appears in
the above-mentioned paper), the theorem which single-handedly
enabled the digital revolution. To a mathematician, this is a simple
corollary to Fourier series, and he/she might suggest many other
ways to represent such particular functions. However, the strength
of the sampling theorem and its variations (e.g. oversampling
or quantization) is that it is an operational theorem, robust,
and applicable to actual signal acquisition and reconstruction
problems.
In order to showcase such powerful applications, the last chapter
is entirely devoted to developing an end-to-end communication
system, namely a modem for communicating digital information
(or bits) over an analog channel. This real-world application
(which is present in all modern communication devices, from
mobile phones to ADSL boxes) nicely brings together many of the
concepts and designs studied in the previous chapters. Being less formal, more abstract and application-driven seems almost like
moving simultaneously in several and possibly opposite directions, but we
believe we came up with the right balancing act. Ultimately, of course, the
readers and students are the judges!
A last and very important issue is the online access to the text
and supplementary material. A full html version together with the
unavoidable errata and other complementary material is available at
www.sp4comm.org. A solution manual is available to teachers upon
request.
As a closing word, we hope you will enjoy the text, and we welcome your
feedback. Let signal processing begin, and be fun!
Martin Vetterli and Paolo Prandoni
The current book is the result of several iterations of a yearly signal
processing undergraduate class and the authors would like to thank the
students in Communication Systems at EPFL who survived the early
versions of the manuscript and who greatly contributed with their feedback
to improve and refine the text along the years. Invaluable help was also
provided by the numerous teaching assistants who not only volunteered
constructive criticism but came up with a lot of the exercices which appear
at the end of each chapter (and their relative solutions). In no particular
order: Andrea Ridolfi provided insightful mathematical remarks and also
introduced us to the wonders of PsTricks while designing figures. Olivier Roy
and Guillermo Barrenetxea have been indefatigable ambassadors between
teaching and student bodies, helping shape exercices in a (hopefully) more
user-friendly form. Ivana Jovanovic, Florence Bénézit and Patrick
Vandewalle gave us a set of beautiful ideas and pointers thanks to their
recitations on choice signal processing topics. Luciano Sbaiz always lent an
indulgent ear and an insightful answer to all the doubts and worries
which plague scientific writers. We would also like to express our
personal gratitude to our families and friends for their patience and their
constant support; unfortunately, to do so in a proper manner, we
should resort to a lyricism which is sternly frowned upon in technical
textbooks and therefore we must confine ourselves to a simple “thank
you”.
Contents
Preface
1 What Is Digital Signal Processing?
1.1 Some History and Philosophy
1.1.1 Digital Signal Processing under the Pyramids
1.1.2 The Hellenic Shift to Analog Processing
1.1.3 “Gentlemen: calculemus!”
1.2 Discrete Time
1.3 Discrete Amplitude
1.4 Communication Systems
1.5 How to Read this Book
1.6 Further Reading
2 Discrete-Time Signals
2.1 Basic Definitions
2.1.1 The Discrete-Time Abstraction
2.1.2 Basic Signals
2.1.3 Digital Frequency
2.1.4 Elementary Operators
2.1.5 The Reproducing Formula
2.1.6 Energy and Power
2.2 Classes of Discrete-Time Signals
2.2.1 Finite-Length Signals
2.2.2 Infinite-Length Signals
2.3 Examples
2.4 Further Reading
2.5 Exercises
3 Signals and Hilbert Spaces
3.1 Euclidean Geometry: a Review
3.2 From Vector Spaces to Hilbert Spaces
3.2.1 The Recipe for Hilbert Space
3.2.2 Examples of Hilbert Spaces
3.2.3 Inner Products and Distances
3.3 Subspaces, Bases, Projections
3.3.1 Definitions
3.3.2 Properties of Orthonormal Bases
3.3.3 Examples of Bases
3.4 Signal Spaces Revisited
3.4.1 Finite-Length Signals
3.4.2 Periodic Signals
3.4.3 Infinite Sequences
3.5 Further Reading
3.6 Exercises
4 Fourier Analysis
4.1 Preliminaries
4.1.1 Complex Exponentials
4.1.2 Complex Oscillations? Negative Frequencies?
4.2 The DFT (Discrete Fourier Transform)
4.2.1 Matrix Form
4.2.2 Explicit Form
4.2.3 Physical Interpretation
4.3 The DFS (Discrete Fourier Series)
4.4 2
4.4.1 The DTFT as the Limit of a DFS
4.4.2 The DTFT as a Formal Change of Basis
4.5 Relationships between Transforms
4.6 Fourier Transform Properties
4.6.1 DTFT Properties
4.6.2 DFS Properties
4.6.3 DFT Properties
4.7 Fourier Analysis in Practice
4.7.1 Plotting Spectral Data
4.7.2 Computing the Transform: the FFT
4.7.3 Cosmetics: Zero-Padding
4.7.4 Spectral Analysis
4.8 Time-Frequency Analysis
4.8.1 The Spectrogram
4.8.2 The Uncertainty Principle
4.9 Digital Frequency vs. Real Frequency
4.10 Examples
4.11 Further Reading
4.12 Exercises
5 Discrete-Time Filters
5.1 Linear Time-Invariant Systems
5.2 Filtering in the Time Domain
5.2.1 The Convolution Operator
5.2.2 Properties of the Impulse Response
5.3 Filtering by Example – Time Domain
5.3.1 FIR Filtering
5.3.2 IIR Filtering
5.4 Filtering in the Frequency Domain
5.4.1 LTI “Eigenfunctions”
5.4.2 The Convolution and Modulation Theorems
5.4.3 Properties of the Frequency Response
5.5 Filtering by Example – Frequency Domain
5.6 Ideal Filters
5.7 Realizable Filters
5.7.1 Constant-Coefficient Difference Equations
5.7.2 The Algorithmic Nature of CCDEs
5.7.3 Filter Analysis and Design
5.8 Examples
5.9 Further Reading
5.10 Exercises
6 The Z-Transform
6.1 Filter Analysis
6.1.1 Solving CCDEs
6.1.2 Causality
6.1.3 Region of Convergence
6.1.4 ROC and System Stability
6.1.5 ROC of Rational Transfer Functions
and Filter Stability
6.2 The Pole-Zero Plot
6.2.1 Pole-Zero Patterns
6.2.2 Pole-Zero Cancellation
6.2.3 Sketching the Transfer Function
from the Pole-Zero Plot
6.3 Filtering by Example – Z-Transform
6.4 Examples
6.5 Further Reading
6.6 Exercises
7 Filter Design
7.1 Design Fundamentals
7.1.1 FIR versus IIR
7.1.2 Filter Specifications and Tradeoffs
7.2 FIR Filter Design
7.2.1 FIR Filter Design by Windowing
7.2.2 Minimax FIR Filter Design
7.3 IIR Filter Design
7.3.1 All-Time Classics
7.4 Filter Structures
7.4.1 FIR Filter Structures
7.4.2 IIR Filter Structures
7.4.3 Some Remarks on Numerical Stability
7.5 Filtering and Signal Classes
7.5.1 Filtering of Finite-Length Signals
7.5.2 Filtering of Periodic Sequences
7.6 Examples
7.7 Further Reading
7.8 Exercises
8 Stochastic Signal Processing
8.1 Random Variables
8.2 Random Vectors
8.3 Random Processes
8.4 Spectral Representation
of Stationary Random Processes
8.4.1 Power Spectral Density
8.4.2 PSD of a Stationary Process
8.4.3 White Noise
8.5 Stochastic Signal Processing
8.6 Examples
8.7 Further Reading
8.8 Exercises
9 Interpolation and Sampling
9.1 Preliminaries and Notation
9.2 Continuous-Time Signals
9.3 Bandlimited Signals
9.4 Interpolation
9.4.1 Local Interpolation
9.4.2 Polynomial Interpolation
9.4.3 Sinc Interpolation
9.5 The Sampling Theorem
9.6 Aliasing
9.6.1 Non-Bandlimited Signals
9.6.2 Aliasing: Intuition
9.6.3 Aliasing: Proof
9.6.4 Aliasing: Examples
9.7 Examples
9.8 Appendix
9.9 Further Reading
9.10 Exercises
10 A/D and D/A Conversions
10.1 Quantization
10.1.1 Uniform Scalar Quantization
10.1.2 Advanced Quantizers
10.2 A/D Conversion
10.3 D/A Conversion
10.4 Examples
10.5 Further Reading
10.6 Exercises
11 Multirate Signal Processing
11.1 Downsampling
11.1.1 Properties of the Downsampling Operator
11.1.2 Frequency-Domain Representation
11.1.3 Examples
11.1.4 Downsampling and Filtering
11.2 Upsampling
11.2.1 Upsampling and Interpolation
11.3 Rational Sampling Rate Changes
11.4 Oversampling
11.4.1 Oversampled A/D Conversion
11.4.2 Oversampled D/A Conversion
11.5 Examples
11.6 Further Reading
11.7 Exercises
12 Design of a Digital Communication System
12.1 The Communication Channel
12.1.1 The AM Radio Channel
12.1.2 The Telephone Channel
12.2 Modem Design: The Transmitter
12.2.1 Digital Modulation and the Bandwidth Constraint
12.2.2 Signaling Alphabets and the Power Constraint
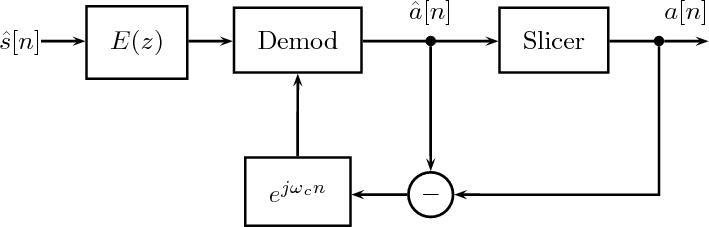
12.3 Modem Design: the Receiver
12.3.1 Hilbert Demodulation
12.3.2 The Effects of the Channel
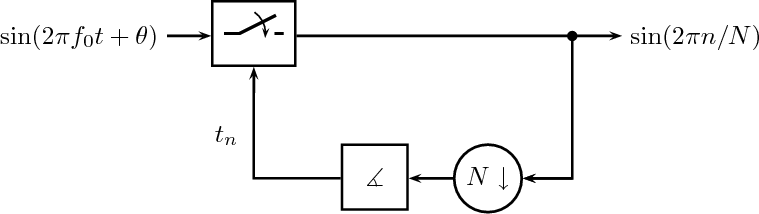
12.4 Adaptive Synchronization
12.4.1 Carrier Recovery
12.4.2 Timing Recovery
12.5 Further Reading
12.6 Exercises
© Presses polytechniques et universitaires romandes, 2008
All rights reservedPreface
Spring 2008, Paris and GrandvauxAcknowledgements
© Presses polytechniques et universitaires romandes, 2008
All rights reserved
A signal, technically yet generally speaking, is a a formal description of a phenomenon evolving over time or space; by signal processing we denote any manual or “mechanical” operation which modifies, analyzes or otherwise manipulates the information contained in a signal. Consider the simple example of ambient temperature: once we have agreed upon a formal model for this physical variable – Celsius degrees, for instance – we can record the evolution of temperature over time in a variety of ways and the resulting data set represents a temperature “signal”. Simple processing operations can then be carried out even just by hand: for example, we can plot the signal on graph paper as in Figure 1.1, or we can compute derived parameters such as the average temperature in a month.
Conceptually, it is important to note that signal processing operates on an abstract representation of a physical quantity and not on the quantity itself. At the same time, the type of abstract representation we choose for the physical phenomenon of interest determines the nature of a signal processing unit. A temperature regulation device, for instance, is not a signal processing system as a whole. The device does however contain a signal processing core in the feedback control unit which converts the instantaneous measure of the temperature into an ON/OFF trigger for the heating element. The physical nature of this unit depends on the temperature model: a simple design is that of a mechanical device based on the dilation of a metal sensor; more likely, the temperature signal is a voltage generated by a thermocouple and in this case the matched signal processing unit is an operational amplifier.
Finally, the adjective “digital” derives from digitus, the Latin word for finger: it concisely describes a world view where everything can be ultimately represented as an integer number. Counting, first on one’s fingers and then in one’s head, is the earliest and most fundamental form of abstraction; as children we quickly learn that counting does indeed bring disparate objects (the proverbial “apples and oranges”) into a common modeling paradigm, i.e. their cardinality. Digital signal processing is a flavor of signal processing in which everything including time is described in terms of integer numbers; in other words, the abstract representation of choice is a one-size-fit-all countability. Note that our earlier “thought experiment” about ambient temperature fits this paradigm very naturally: the measuring instants form a countable set (the days in a month) and so do the measures themselves (imagine a finite number of ticks on the thermometer’s scale). In digital signal processing the underlying abstract representation is always the set of natural numbers regardless of the signal’s origins; as a consequence, the physical nature of the processing device will also always remain the same, that is, a general digital (micro)processor. The extraordinary power and success of digital signal processing derives from the inherent universality of its associated “world view”.
Probably the earliest recorded example of digital signal processing dates back to the 25th century BC. At the time, Egypt was a powerful kingdom reaching over a thousand kilometers south of the Nile’s delta. For all its latitude, the kingdom’s populated area did not extend for more than a few kilometers on either side of the Nile; indeed, the only inhabitable areas in an otherwise desert expanse were the river banks, which were made fertile by the yearly flood of the river. After a flood, the banks would be left covered with a thin layer of nutrient-rich silt capable of supporting a full agricultural cycle. The floods of the Nile, however, were(1) a rather capricious meteorological phenomenon, with scant or absent floods resulting in little or no yield from the land. The pharaohs quickly understood that, in order to preserve stability, they would have to set up a grain buffer with which to compensate for the unreliability of the Nile’s floods and prevent potential unrest in a famished population during “dry” years. As a consequence, studying and predicting the trend of the floods (and therefore the expected agricultural yield) was of paramount importance in order to determine the operating point of a very dynamic taxation and redistribution mechanism. The floods of the Nile were meticulously recorded by an array of measuring stations called “nilometers” and the resulting data set can indeed be considered a full-fledged digital signal defined on a time base of twelve months. The Palermo Stone, shown in the left panel of Figure 1.2, is a faithful record of the data in the form of a table listing the name of the current pharaoh alongside the yearly flood level; a more modern representation of an flood data set is shown on the left of the figure: bar the references to the pharaohs, the two representations are perfectly equivalent. The Nile’s behavior is still an active area of hydrological research today and it would be surprising if the signal processing operated by the ancient Egyptians on their data had been of much help in anticipating for droughts. Yet, the Palermo Stone is arguably the first recorded digital signal which is still of relevance today.
|
|
“Digital” representations of the world such as those depicted by the Palermo
Stone are adequate for an environment in which quantitative problems are
simple: counting cattle, counting bushels of wheat, counting days and so on.
As soon as the interaction with the world becomes more complex, so
necessarily do the models used to interpret the world itself. Geometry, for
instance, is born of the necessity of measuring and subdividing land
property. In the act of splitting a certain quantity into parts we can
already see the initial difficulties with an integer-based world view
;(2)
yet, until the Hellenic period, western civilization considered natural
numbers and their ratios all that was needed to describe nature in an
operational fashion. In the 6th century BC, however, a devastated
Pythagoras realized that the the side and the diagonal of a square are
incommensurable, i.e. that 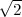 is not a simple fraction. The discovery of
what we now call irrational numbers “sealed the deal” on an abstract model
of the world that had already appeared in early geometric treatises and
which today is called the continuum. Heavily steeped in its geometric roots
(i.e. in the infinity of points in a segment), the continuum model postulates
that time and space are an uninterrupted flow which can be divided
arbitrarily many times into arbitrarily (and infinitely) small pieces. In signal
processing parlance, this is known as the “analog” world model and,
in this model, integer numbers are considered primitive entities, as
rough and awkward as a set of sledgehammers in a watchmaker’s
shop.
is not a simple fraction. The discovery of
what we now call irrational numbers “sealed the deal” on an abstract model
of the world that had already appeared in early geometric treatises and
which today is called the continuum. Heavily steeped in its geometric roots
(i.e. in the infinity of points in a segment), the continuum model postulates
that time and space are an uninterrupted flow which can be divided
arbitrarily many times into arbitrarily (and infinitely) small pieces. In signal
processing parlance, this is known as the “analog” world model and,
in this model, integer numbers are considered primitive entities, as
rough and awkward as a set of sledgehammers in a watchmaker’s
shop.
In the continuum, the infinitely big and the infinitely small dance together in complex patterns which often defy our intuition and which required almost two thousand years to be properly mastered. This is of course not the place to delve deeper into this extremely fascinating epistemological domain; suffice it to say that the apparent incompatibility between the digital and the analog world views appeared right from the start (i.e. from the 5th century BC) in Zeno’s works; we will appreciate later the immense import that this has on signal processing in the context of the sampling theorem.
Zeno’s paradoxes are well known and they underscore this unbridgeable gap between our intuitive, integer-based grasp of the world and a model of the world based on the continuum. Consider for instance the dichotomy paradox; Zeno states that if you try to move along a line from point A to point B you will never in fact be able to reach your destination. The reasoning goes as follows: in order to reach B, you will have to first go through point C, which is located mid-way between A and B; but, even before you reach C, you will have to reach D, which is the midpoint between A and C; and so on ad infinitum. Since there is an infinity of such intermediate points, Zeno argues, moving from A to B requires you to complete an infinite number of tasks, which is humanly impossible. Zeno of course was well aware of the empirical evidence to the contrary but he was brilliantly pointing out the extreme trickery of a model of the world which had not yet formally defined the concept of infinity. The complexity of the intellectual machinery needed to solidly counter Zeno’s argument is such that even today the paradox is food for thought. A first-year calculus student may be tempted to offhandedly dismiss the problem by stating
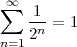 | (1.1) |
but this is just a void formalism begging the initial question if the underlying notion of the continuum is not explicitly worked out.(3) In reality Zeno’s paradoxes cannot be “solved”, since they cease to be paradoxes once the continuum model is fully understood.
The two competing models for the world, digital and analog, coexisted quite peacefully for quite a few centuries, one as the tool of the trade for farmers, merchants, bankers, the other as an intellectual pursuit for mathematicians and astronomers. Slowly but surely, however, the increasing complexity of an expanding world spurred the more practically-oriented minds to pursue science as a means to solve very tangible problems besides describing the motion of the planets. Calculus, brought to its full glory by Newton and Leibnitz in the 17th century, proved to be an incredibly powerful tool when applied to eminently practical concerns such as ballistics, ship routing, mechanical design and so on; such was the faith in the power of the new science that Leibnitz envisioned a not-too-distant future in which all human disputes, including problems of morals and politics, could be worked out with pen and paper: “gentlemen, calculemus”. If only.
As Cauchy unsurpassably explained later, everything in calculus is a limit and therefore everything in calculus is a celebration of the power of the continuum. Still, in order to apply the calculus machinery to the real world, the real world has to be modeled as something calculus understands, namely a function of a real (i.e. continuous) variable. As mentioned before, there are vast domains of research well behaved enough to admit such an analytical representation; astronomy is the first one to come to mind, but so is ballistics, for instance. If we go back to our temperature measurement example, however, we run into the first difficulty of the analytical paradigm: we now need to model our measured temperature as a function of continuous time, which means that the value of the temperature should be available at any given instant and not just once per day. A “temperature function” as in Figure 1.3 is quite puzzling to define if all we have (and if all we can have, in fact) is just a set of empirical measurements reasonably spaced in time. Even in the rare cases in which an analytical model of the phenomenon is available, a second difficulty arises when the practical application of calculus involves the use of functions which are only available in tabulated form. The trigonometric and logarithmic tables are a typical example of how a continuous model needs to be made countable again in order to be put to real use. Algorithmic procedures such as series expansions and numerical integration methods are other ways to bring the analytic results within the realm of the practically computable. These parallel tracks of scientific development, the “Platonic” ideal of analytical results and the slide rule reality of practitioners, have coexisted for centuries and they have found their most durable mutual peace in digital signal processing, as will appear shortly.
One of the fundamental problems in signal processing is to obtain a permanent record of the signal itself. Think back of the ambient temperature example, or of the floods of the Nile: in both cases a description of the phenomenon was gathered by a naive sampling operation, i.e. by measuring the quantity of interest at regular intervals. This is a very intuitive process and it reflects the very natural act of “looking up the current value and writing it down”. Manually this operation is clearly quite slow but it is conceivable to speed it up mechanically so as to obtain a much larger number of measurements per unit of time. Our measuring machine, however fast, still will never be able to take an infinite amount of samples in a finite time interval: we are back in the clutches of Zeno’s paradoxes and one would be tempted to conclude that a true analytical representation of the signal is impossible to obtain.
At the same time, the history of applied science provides us with many examples of recording machines capable of providing an “analog” image of a physical phenomenon. Consider for instance a thermograph: this is a mechanical device in which temperature deflects an ink-tipped metal stylus in contact with a slowly rolling paper-covered cylinder. Thermographs like the one sketched in Figure 1.4 are still currently in use in some simple weather stations and they provide a chart in which a temperature function as in Figure 1.3 is duly plotted. Incidentally, the principle is the same in early sound recording devices: Edison’s phonograph used the deflection of a steel pin connected to a membrane to impress a “continuous-time” sound wave as a groove on a wax cylinder. The problem with these analog recordings is that they are not abstract signals but a conversion of a physical phenomenon into another physical phenomenon: the temperature, for instance, is converted into the amount of ink on paper while the sound pressure wave is converted into the physical depth of the groove. The advent of electronics did not change the concept: an audio tape, for instance, is obtained by converting a pressure wave into an electrical current and then into a magnetic deflection. The fundamental consequence is that, for analog signals, a different signal processing system needs to be designed explicitly for each specific form of recording.
Consider for instance the problem of computing the average temperature
over a certain time interval. Calculus provides us with the exact answer 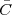 if
we know the elusive “temperature function” f(t) over an interval [T0,T1]
(see Figure 1.5, top panel):
if
we know the elusive “temperature function” f(t) over an interval [T0,T1]
(see Figure 1.5, top panel):
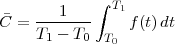 | (1.2) |
We can try to reproduce the integration with a “machine” adapted to the particular representation of temperature we have at hand: in the case of the thermograph, for instance, we can use a planimeter as in Figure 1.6, a manual device which computes the area of a drawn surface; in a more modern incarnation in which the temperature signal is given by a thermocouple, we can integrate the voltage with the RC network in Figure 1.7. In both cases, in spite of the simplicity of the problem, we can instantly see the practical complications and the degree of specialization needed to achieve something as simple as an average for an analog signal.
Now consider the case in which all we have is a set of daily measurements c1,c2,…,cD as in Figure 1.1; the “average” temperature of our measurements over D days is simply:
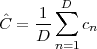 | (1.3) |
(as shown in the bottom panel of Figure 1.5) and this is an elementary sum
of D terms which anyone can carry out by hand and which does not depend
on how the measurements have been obtained: wickedly simple! So,
obviously, the question is: “How different (if at all) is Ĉ from 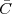 ?” In order to
find out we can remark that if we accept the existence of a temperature
function f(t) then the measured values cn are samples of the function taken
one day apart:
?” In order to
find out we can remark that if we accept the existence of a temperature
function f(t) then the measured values cn are samples of the function taken
one day apart:
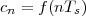 |
(where Ts is the duration of a day). In this light, the sum (1.3) is just the Riemann approximation to the integral in (1.2) and the question becomes an assessment on how good an approximation that is. Another way to look at the problem is to ask ourselves how much information we are discarding by only keeping samples of a continuous-time function.
The answer, which we will study in detail in Chapter 9, is that in fact the continuous-time function and the set of samples are perfectly equivalent representations – provided that the underlying physical phenomenon “doesn’t change too fast”. Let us put the proviso aside for the time being and concentrate instead on the good news: first, the analog and the digital world can perfectly coexist; second, we actually possess a constructive way to move between worlds: the sampling theorem, discovered and rediscovered by many at the beginning of the 20th century(4) , tells us that the continuous-time function can be obtained from the samples as
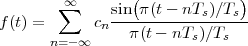 | (1.4) |
So, in theory, once we have a set of measured values, we can build the continuous-time representation and use the tools of calculus. In reality things are even simpler: if we plug (1.4) into our analytic formula for the average (1.2) we can show that the result is a simple sum like (1.3). So we don’t need to explicitly go “through the looking glass” back to continuous-time: the tools of calculus have a discrete-time equivalent which we can use directly.
The equivalence between the discrete and continuous representations only holds for signals which are sufficiently “slow” with respect to how fast we sample them. This makes a lot of sense: we need to make sure that the signal does not do “crazy” things between successive samples; only if it is smooth and well behaved can we afford to have such sampling gaps. Quantitatively, the sampling theorem links the speed at which we need to repeatedly measure the signal to the maximum frequency contained in its spectrum. Spectra are calculated using the Fourier transform which, interestingly enough, was originally devised as a tool to break periodic functions into a countable set of building blocks. Everything comes together.
While it appears that the time continuum has been tamed by the sampling theorem, we are nevertheless left with another pesky problem: the precision of our measurements. If we model a phenomenon as an analytical function, not only is the argument (the time domain) a continuous variable but so is the function’s value (the codomain); a practical measurement, however, will never achieve an infinite precision and we have another paradox on our hands. Consider our temperature example once more: we can use a mercury thermometer and decide to write down just the number of degrees; maybe we can be more precise and note the half-degrees as well; with a magnifying glass we could try to record the tenths of a degree – but we would most likely have to stop there. With a more sophisticated thermocouple we could reach a precision of one hundredth of a degree and possibly more but, still, we would have to settle on a maximum number of decimal places. Now, if we know that our measures have a fixed number of digits, the set of all possible measures is actually countable and we have effectively mapped the codomain of our temperature function onto the set of integer numbers. This process is called quantization and it is the method, together with sampling, to obtain a fully digital signal.
In a way, quantization deals with the problem of the continuum in a much “rougher” way than in the case of time: we simply accept a loss of precision with respect to the ideal model. There is a very good reason for that and it goes under the name of noise. The mechanical recording devices we just saw, such as the thermograph or the phonograph, give the illusion of analytical precision but are in practice subject to severe mechanical limitations. Any analog recording device suffers from the same fate and even if electronic circuits can achieve an excellent performance, in the limit the unavoidable thermal agitation in the components constitutes a noise floor which limits the “equivalent number of digits”. Noise is a fact of nature that cannot be eliminated, hence our acceptance of a finite (i.e. countable) precision.
Noise is not just a problem in measurement but also in processing. Figure 1.8 shows the two archetypal types of analog and digital computing devices; while technological progress may have significantly improved the speed of each, the underlying principles remain the same for both. An analog signal processing system, much like the slide rule, uses the displacement of physical quantities (gears or electric charge) to perform its task; each element in the system, however, acts as a source of noise so that complex or, more importantly, cheap designs introduce imprecisions in the final result (good slide rules used to be very expensive). On the other hand the abacus, working only with integer arithmetic, is a perfectly precise machine(5) even if it’s made with rocks and sticks. Digital signal processing works with countable sequences of integers so that in a digital architecture no processing noise is introduced. A classic example is the problem of reproducing a signal. Before mp3 existed and file sharing became the bootlegging method of choice, people would “make tapes”. When someone bought a vinyl record he would allow his friends to record it on a cassette; however, a “peer-to-peer” dissemination of illegally taped music never really took off because of the “second generation noise”, i.e. because of the ever increasing hiss that would appear in a tape made from another tape. Basically only first generation copies of the purchased vinyl were acceptable quality on home equipment. With digital formats, on the other hand, duplication is really equivalent to copying down a (very long) list of integers and even very cheap equipment can do that without error.
Finally, a short remark on terminology. The amplitude accuracy of a set of samples is entirely dependent on the processing hardware; in current parlance this is indicated by the number of bits per sample of a given representation: compact disks, for instance, use 16 bits per sample while DVDs use 24. Because of its “contingent” nature, quantization is almost always ignored in the core theory of signal processing and all derivations are carried out as if the samples were real numbers; therefore, in order to be precise, we will almost always use the term discrete-time signal processing and leave the label “digital signal processing” (DSP) to the world of actual devices. Neglecting quantization will allow us to obtain very general results but care must be exercised: in the practice, actual implementations will have to deal with the effects of finite precision, sometimes with very disruptive consequences.
Signals in digital form provide us with a very convenient abstract representation which is both simple and powerful; yet this does not shield us from the need to deal with an “outside” world which is probably best modeled by the analog paradigm. Consider a mundane act such as placing a call on a cell phone, as in Figure 1.9: humans are analog devices after all and they produce analog sound waves; the phone converts these into digital format, does some digital processing and then outputs an analog electromagnetic wave on its antenna. The radio wave travels to the base station in which it is demodulated, converted to digital format to recover the voice signal. The call, as a digital signal, continues through a switch and then is injected into an optical fiber as an analog light wave. The wave travels along the network and then the process is inverted until an analog sound wave is generated by the loudspeaker at the receiver’s end.
Communication systems are in general a prime example of sophisticated interplay between the digital and the analog world: while all the processing is undoubtedly best done digitally, signal propagation in a medium (be it the the air, the electromagnetic spectrum or an optical fiber) is the domain of differential (rather than difference) equations. And yet, even when digital processing must necessarily hand over control to an analog interface, it does so in a way that leaves no doubt as to who’s boss, so to speak: for, instead of transmitting an analog signal which is the reconstructed “real” function as per (1.4), we always transmit an analog signal which encodes the digital representation of the data. This concept is really at the heart of the “digital revolution” and, just like in the cassette tape example, it has to do with noise.
Imagine an analog voice signal s(t) which is transmitted over a (long) telephone line; a simplified description of the received signal is
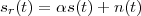 |
where the parameter α, with α < 1, is the attenuation that the signal incurs and where n(t) is the noise introduced by the system. The noise function is of obviously unknown (it is often modeled as a Gaussian process, as we will see) and so, once it’s added to the signal, it’s impossible to eliminate it. Because of attenuation, the receiver will include an amplifier with gain G to restore the voice signal to its original level; with G = 1∕α we will have
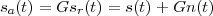 |
Unfortunately, as it appears, in order to regenerate the analog signal we also have amplified the noise G times; clearly, if G is large (i.e. if there is a lot of attenuation to compensate for) the voice signal end up buried in noise. The problem is exacerbated if many intermediate amplifiers have to be used in cascade, as is the case in long submarine cables.
Consider now a digital voice signal, that is, a discrete-time signal whose samples have been quantized over, say, 256 levels: each sample can therefore be represented by an 8-bit word and the whole speech signal can be represented as a very long sequence of binary digits. We now build an analog signal as a two-level signal which switches for a few instants between, say, -1 V and +1 V for every “0” and “1” bit in the sequence respectively. The received signal will still be
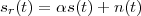 |
but, to regenerate it, instead of linear amplification we can use nonlinear thresholding:
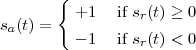 |
Figure 1.10 clearly shows that as long as the magnitude of the noise is less than α the two-level signal can be regenerated perfectly; furthermore, the regeneration process can be repeated as many times as necessary with no overall degradation.
|
|
In reality of course things are a little more complicated and, because of the nature of noise, it is impossible to guarantee that some of the bits won’t be corrupted. The answer is to use error correcting codes which, by introducing redundancy in the signal, make the sequence of ones and zeros robust to the presence of errors; a scratched CD can still play flawlessly because of the Reed-Solomon error correcting codes used for the data. Data coding is the core subject of Information Theory and it is behind the stellar performance of modern communication systems; interestingly enough, the most successful codes have emerged from group theory, a branch of mathematics dealing with the properties of closed sets of integer numbers. Integers again! Digital signal processing and information theory have been able to join forces so successfully because they share a common data model (the integer) and therefore they share the same architecture (the processor). Computer code written to implement a digital filter can dovetail seamlessly with code written to implement error correction; linear processing and nonlinear flow control coexist naturally.
A simple example of the power unleashed by digital signal processing is the performance of transatlantic cables. The first operational telegraph cable from Europe to North America was laid in 1858 (see Fig. 1.11); it worked for about a month before being irrecoverably damaged.(6) From then on, new materials and rapid progress in electrotechnics boosted the performance of each subsequent cable; the key events in the timeline of transatlantic communications are shown in Table 1.1. The first transatlantic telephone cable was laid in 1956 and more followed in the next two decades with increasing capacity due to multicore cables and better repeaters; the invention of the echo canceler further improved the number of voice channels for already deployed cables. In 1968 the first experiments in PCM digital telephony were successfully completed and the quantum leap was around the corner: by the end of the 70’s cables were carrying over one order of magnitude more voice channels than in the 60’s. Finally, the deployment of the first fiber optic cable in 1988 opened the door to staggering capacities (and enabled the dramatic growth of the Internet).
Finally, it’s impossible not to mention the advent of data compression in this brief review of communication landmarks. Again, digital processing allows the coexistence of standard processing with sophisticated decision logic; this enables the implementation of complex data-dependent compression techniques and the inclusion of psychoperceptual models in order to match the compression strategy to the characteristics of the human visual or auditory system. A music format such as mp3 is perhaps the first example to come to mind but, as shown in Table 1.2, all communication domains have been greatly enhanced by the gains in throughput enabled by data compression.
|
|
This book tries to build a largely self-contained development of digital signal processing theory from within discrete time, while the relationship to the analog model of the world is tackled only after all the fundamental “pieces of the puzzle” are already in place. Historically, modern discrete-time processing started to consolidate in the 50’s when mainframe computers became powerful enough to handle the effective simulations of analog electronic networks. By the end of the 70’s the discipline had by all standards reached maturity; so much so, in fact, that the major textbooks on the subject still in use today had basically already appeared by 1975. Because of its ancillary origin with respect to the problems of that day, however, discrete-time signal processing has long been presented as a tributary to much more established disciplines such as Signals and Systems. While historically justifiable, that approach is no longer tenable today for three fundamental reasons: first, the pervasiveness of digital storage for data (from CDs to DVDs to flash drives) implies that most devices today are designed for discrete-time signals to start with; second, the trend in signal processing devices is to move the analog-to-digital and digital-to-analog converters at the very beginning and the very end of the processing chain so that even “classically analog” operations such as modulation and demodulation are now done in discrete-time; third, the availability of numerical packages like Matlab provides a testbed for signal processing experiments (both academically and just for fun) which is far more accessible and widespread than an electronics lab (not to mention affordable).
The idea therefore is to introduce discrete-time signals as a self-standing entity (Chap. 2), much in the natural way of a temperature sequence or a series of flood measurements, and then to remark that the mathematical structures used to describe discrete-time signals are one and the same with the structures used to describe vector spaces (Chap. 3). Equipped with the geometrical intuition afforded to us by the concept of vector space, we can proceed to “dissect” discrete-time signals with the Fourier transform, which turns out to be just a change of basis (Chap. 4). The Fourier transform opens the passage between the time domain and the frequency domain and, thanks to this dual understanding, we are ready to tackle the concept of processing as performed by discrete-time linear systems, also known as filters (Chap. 5). Next comes the very practical task of designing a filter to order, with an eye to the subtleties involved in filter implementation; we will mostly consider FIR filters, which are unique to discrete time (Chaps 6 and 7). After a brief excursion in the realm of stochastic sequences (Chap. 8) we will finally build a bridge between our discrete-time world and the continuous-time models of physics and electronics with the concepts of sampling and interpolation (Chap. 9); and digital signals will be completely accounted for after a study of quantization (Chap. 10). We will finally go back to purely discrete time for the final topic, multirate signal processing (Chap. 11), before putting it all together in the final chapter: the analysis of a commercial voiceband modem (Chap. 12).
The Bible of digital signal processing was and remains Discrete-Time Signal Processing, by A. V. Oppenheim and R. W. Schafer (Prentice-Hall, last edition in 1999); exceedingly exhaustive, it is a must-have reference. For background in signals and systems, the eponimous Signals and Systems, by Oppenheim, Willsky and Nawab (Prentice Hall, 1997) is a good start.
Most of the historical references mentioned in this introduction can be integrated by simple web searches. Other comprehensive books on digital signal processing include S. K. Mitra’s Digital Signal Processing (McGraw Hill, 2006) and Digital Signal Processing, by J. G. Proakis and D. K. Manolakis (Prentis Hall 2006). For a fascinating excursus on the origin of calculus, see D. Hairer and G. Wanner, Analysis by its History (Springer-Verlag, 1996). A more than compelling epistemological essay on the continuum is Everything and More, by David Foster Wallace (Norton, 2003), which manages to be both profound and hilarious in an unprecedented way.
Finally, the very prolific literature on current signal processing research is published mainly by the Institute of Electronics and Electrical Engineers (IEEE) in several of its transactions such as IEEE Transactions on Signal Processing, IEEE Transactions on Image Processing and IEEE Transactions on Speech and Audio Processing.
| © Presses polytechniques et universitaires romandes, 2008 All rights reserved |
In this Chapter we define more formally the concept of the discrete-time signal and establish an associated basic taxonomy used in the remainder of the book. Historically, discrete-time signals have often been introduced as the discretized version of continuous-time signals, i.e. as the sampled values of analog quantities, such as the voltage at the output of an analog circuit; accordingly, many of the derivations proceeded within the framework of an underlying continuous-time reality. In truth, the discretization of analog signals is only part of the story, and a rather minor one nowadays. Digital signal processing, especially in the context of communication systems, is much more concerned with the synthesis of discrete-time signals rather than with sampling. That is why we choose to introduce discrete-time signals from an abstract and self-contained point of view.
A discrete-time signal is a complex-valued sequence. Remember that a
sequence is defined as a complex-valued function of an integer index n, with
n  Z; as such, it is a two-sided, infinite collection of values. A sequence can
be defined analytically in closed form, as for example:
Z; as such, it is a two-sided, infinite collection of values. A sequence can
be defined analytically in closed form, as for example:
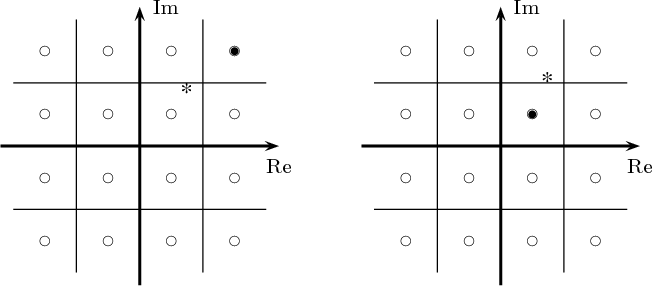
![x[n] = (n mod 11) - 5](livre24x.png) | (2.1) |
shown as the “triangular” waveform plotted in Figure 2.1; or
![j πn
x [n] = e 20](livre25x.png) | (2.2) |
which is a complex exponential of period 40 samples, plotted in Figure 2.2. An example of a sequence drawn from the real world is
![x[n ] = The average Dow -Jones index in year n](livre26x.png) | (2.3) |
plotted in Figure 2.3 from year 1900 to 2002. Another example, this time of a random sequence, is
![x[n] = the n-th output of a random source U(- 1,1)](livre27x.png) | (2.4) |
a realization of which is plotted in Figure 2.4.
A few notes are in order:
While analytical forms of discrete-time signals such as the ones above are useful to illustrate the key points of signal processing and are absolutely necessary in the mathematical abstractions which follow, they are non-etheless just that, abstract examples. How does the notion of a discrete-time signal relate to the world around us? A discrete-time signal, in fact, captures our necessarily limited ability to take repeated accurate measurements of a physical quantity. We might be keeping track of the stock market index at the end of each day to draw a pencil and paper chart; or we might be measuring the voltage level at the output of a microphone 44,100 times per second (obviously not by hand!) to record some music via the computer’s soundcard. In both cases we need “time to write down the value” and are therefore forced to neglect everything that happens between measuring times. This “look and write down” operation is what is normally referred to as sampling. There are real-world phenomena which lend themselves very naturally and very intuitively to a discrete-time representation: the daily Dow-Jones index, for example, solar spots, yearly floods of the Nile, etc. There seems to be no irrecoverable loss in this neglect of intermediate values. But what about music, or radio waves? At this point it is not altogether clear from an intuitive point of view how a sampled measurement of these phenomena entail no loss of information. The mathematical proof of this will be shown in detail when we study the sampling theorem; for the time being let us say that “the proof of the cake is in the eating”: just listen to your favorite CD!
The important point to make here is that, once a real-world signal is converted to a discrete-time representation, the underlying notion of “time between measurements” becomes completely abstract. All we are left with is a sequence of numbers, and all signal processing manipulations, with their intended results, are independent of the way the discrete-time signal is obtained. The power and the beauty of digital signal processing lies in part with its invariance with respect to the underlying physical reality. This is in stark contrast with the world of analog circuits and systems, which have to be realized in a version specific to the physical nature of the input signals.
The following sequences are fundamental building blocks for the theory of signal processing.
Impulse. The discrete-time impulse (or discrete-time delta function) is potentially the simplest discrete-time signal; it is shown in Figure 2.5(a) and is defined as
![{
δ[n ] = 1 n = 0
0 n ⁄= 0](livre34x.png) | (2.5) |
Unit Step. The discrete-time unit step is shown in Figure 2.5(b) and is defined by the following expression:
![{
1 n ≥ 0
u[n] = 0 n < 0](livre35x.png) | (2.6) |
The unit step can be obtained via a discrete-time integration of the impulse (see eq. (2.16)).
Exponential Decay. The discrete-time exponential decay is shown in Figure 2.5(c) and is defined as
![n
x[n] = a u [n], a ∈ C, |a| < 1](livre36x.png) | (2.7) |
The exponential decay is, as we will see, the free response of a discrete-time first order recursive filter. Exponential sequences are well-behaved only for values of a less than one in magnitude; sequences in which |a| > 1 are unbounded and represent an unstable behavior (their energy and power are both infinite).
Complex Exponential. The discrete-time complex exponential has already been shown in Figure 2.2 and is defined as
![j(ω n+φ)
x[n ] = e 0](livre37x.png) | (2.8) |
Special cases of the complex exponential are the real-valued discrete-time sinusoidal oscillations:
| x[n] | = sin(ω0n + φ) | (2.9) |
| x[n] | = cos(ω0n + φ) | (2.10) |
|
a)
|
With respect to the oscillatory behavior captured by the complex exponential, a note on the concept of “frequency” is in order. In the continuous-time world (the world of textbook physics, to be clear), where time is measured in seconds, the usual unit of measure for frequency is the Hertz which is equivalent to 1∕second. In the discrete-time world, where the index n represents a dimensionless time, “digital” frequency is expressed in radians which is itself a dimensionless quantity.(1) The best way to appreciate this is to consider an algorithm to generate successive samples of a discrete-time sinusoid at a digital frequency ω0:
|
At each iteration,(2) the argument of the trigonometric function is incremented by ω0 and a new output sample is produced. With this in mind, it is easy to see that the highest frequency manageable by a discrete-time system is ωmax = 2π; for any frequency larger than this, the inner 2π-periodicity of the trigonometric functions “maps back” the output values to a frequency between 0 and 2π. This can be expressed as an equation:
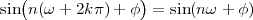 | (2.11) |
for all values of k Z. This 2π-equivalence of digital frequencies
is a pervasive concept in digital signal processing and it has many
important consequences which we will study in detail in the next
Chapters.
In this Section we present some elementary operations on sequences.
Shift. A sequence x[n], shifted by an integer k is simply:
![y[n] = x [n - k]](livre43x.png) | (2.12) |
If k is positive, the signal is shifted “to the left”, meaning that the signal has been delayed; if k is negative, the signal is shifted “to the right”, meaning that the signal has been advanced. The delay operator can be indicated by the following notation:
![{ }
Dk x [n] = x[n- k]](livre44x.png)
Scaling. A sequence x[n] scaled by a factor α C is
![y[n] = αx[n]](livre45x.png) | (2.13) |
If α is real, then the scaling represents a simple amplification or attenuation of the signal (when α > 1 and α < 1, respectively). If α is complex, amplification and attenuation are compounded with a phase shift.
Sum. The sum of two sequences x[n] and w[n] is their term-by-term sum:
![y[n ] = x[n]+ w [n ]](livre46x.png) | (2.14) |
Please note that sum and scaling are linear operators. Informally, this means scaling and sum behave “intuitively”:
![( )
α x[n ]+ w[n] = αx[n]+ αw [n]](livre47x.png)
or
![Dk {x[n]+ w [n ]} = x[n - k]+ w[n - k]](livre48x.png)
Product. The product of two sequences x[n] and w[n] is their term-by-term product
![y[n] = x[n]w[n]](livre49x.png) | (2.15) |
Integration. The discrete-time equivalent of integration is expressed by the following running sum:
![∑n
y[n] = x[k]
k= -∞](livre50x.png) | (2.16) |
Intuitively, integration computes a non-normalized running average of the discrete-time signal.
Differentiation. A discrete-time approximation to differentiation is the first-order difference:(3)
![y[n] = x [n]- x[n - 1]](livre51x.png) | (2.17) |
With respect to Section 2.1.2, note how the unit step can be obtained by applying the integration operator to the discrete-time impulse; conversely, the impulse can be obtained by applying the differentiation operator to the unit step.
The signal reproducing formula is a simple application of the basic signal and signal properties that we have just seen and it states that
![∑∞
x[n ] = x[k]δ[n- k]
k=-∞](livre52x.png) | (2.18) |
Any signal can be expressed as a linear combination of suitably weighed and shifted impulses. In this case, the weights are nothing but the signal values themselves. While self-evident, this formula will reappear in a variety of fundamental derivations since it captures the “inner structure” of a discrete-time signal.
We define the energy of a discrete-time signal as
![∞∑
Ex = ∥x∥2= ||x [n]||2
2 n=-∞](livre53x.png) | (2.19) |
(where the squared-norm notation will be clearer after the next Chapter). This definition is consistent with the idea that, if the values of the sequence represent a time-varying voltage, the above sum would express the total energy (in joules) dissipated over a 1Ω-resistor. Obviously, the energy is finite only if the above sum converges, i.e. if the sequence x[n] is square-summable. A signal with this property is sometimes referred to as a finite- energy signal. For a simple example of the converse, note that a periodic signal which is not identically zero is not square-summable.
We define the power of a signal as the usual ratio of energy over time, taking the limit over the number of samples considered:
![N -1
-1-∑ || ||2
Px = Nlim→∞ 2N x [n]
-N](livre54x.png) | (2.20) |
Clearly, signals whose energy is finite, have zero total power (i.e. their energy dilutes to zero over an infinite time duration). Exponential sequences which are not decaying (i.e. those for which |a| > 1 in (2.7)) possess infinite power (which is consistent with the fact that they describe an unstable behavior). Note, however, that many signals whose energy is infinite do have finite power and, in particular, periodic signals (such as sinusoids and combinations thereof). Due to their periodic nature, however, the above limit is undetermined; we therefore define their power to be simply the average energy over a period. Assuming that the period is N samples, we have
![N∑ -1| |
Px = 1- |x [n]|2
N n=0](livre55x.png) | (2.21) |
The examples of discrete-time signals in (2.1) and (2.2) are two-sided, infinite sequences. Of course, in the practice of signal processing, it is impossible to deal with infinite quantities of data: for a processing algorithm to execute in a finite amount of time and to use a finite amount of storage, the input must be of finite length; even for algorithms that operate on the fly, i.e. algorithms that produce an output sample for each new input sample, an implicit limitation on the input data size is imposed by the necessarily limited life span of the processing device.(4) This limitation was all too apparent in our attempts to plot infinite sequences as shown in Figure 2.1 or 2.2: what the diagrams show, in fact, is just a meaningful and representative portion of the signals; as for the rest, the analytical description remains the only reference. When a discrete-time signal admits no closed-form representation, as is basically always the case with real-world signals, its finite time support arises naturally because of the finite time spent recording the signal: every piece of music has a beginning and an end, and so did every phone conversation. In the case of the sequence representing the Dow Jones index, for instance, we basically cheated since the index did not even exist for years before 1884, and its value tomorrow is certainly not known – so that the signal is not really a sequence, although it can be arbitrarily extended to one. More importantly (and more often), the finiteness of a discrete-time signal is explicitly imposed by design since we are interested in concentrating our processing efforts on a small portion of an otherwise longer signal; in a speech recognition system, for instance, the practice is to cut up a speech signal into small segments and try to identify the phonemes associated to each one of them.(5) A special case is that of periodic signals; even though these are bona-fide infinite sequences, it is clear that all information about them is contained in just one period. By describing one period (graphically or otherwise), we are, in fact, providing a full description of the sequence. The complete taxonomy of the discrete-time signals used in the book is the subject of the next Sections ans is summarized in Table 2.1.
As we just mentioned, a finite-length discrete-time signal of length N are just a collection of N complex values. To introduce a point that will reappear throughout the book, a finite-length signal of length N is entirely equivalent to a vector in CN. This equivalence is of immense import since all the tools of linear algebra become readily available for describing and manipulating finite-length signals. We can represent an N-point finite-length signal using the standard vector notation
![x = [x x ... x ]T
0 1 N -1](livre56x.png)
Note the transpose operator, which declares x as a column vector; this is the customary practice in the case of complex-valued vectors. Alternatively, we can (and often will) use a notation that mimics the one used for proper sequences:
![x[n ], n = 0, ..., N - 1](livre57x.png)
Here we must remember that, although we use the notation x[n], x[n] is not defined for values outside its support, i.e. for n < 0 or for n ≥ N. Note that we can always obtain a finite-length signal from an infinite sequence by simply dropping the sequence values outside the indices of interest. Vector and sequence notations are equivalent and will be used interchangeably according to convenience; in general, the vector notation is useful when we want to stress the algorithmic or geometric nature of certain signal processing operations. The sequence notation is useful in stressing the algebraic structure of signal processing.
Finite-length signals are extremely convenient entities: their energy is always and, as a consequence, no stability issues arise in processing. From the computational point of view, they are not only a necessity but often the cornerstone of very efficient algorithmic design (as we will see, for instance, in the case of the FFT); one could say that all “practical” signal processing lives in CN. It would be extremely awkward, however, to develop the whole theory of signal processing only in terms of finite-length signals; the asymptotic behavior of algorithms and transformations for infinite sequences is also extremely valuable since a stability result proven for a general sequence will hold for all finite-length signals too. Furthermore, the notational flexibility which infinite sequences derive from their function-like definition is extremely practical from the point of view of the notation. We can immediately recognize and understand the expression x[n - k] as a k-point shift of a sequence x[n]; but, in the case of finite-support signals, how are we to define such a shift? We would have to explicitly take into account the finiteness of the signal and the associated “border effects”, i.e. the behavior of operations at the edges of the signal. For this reason, in most derivations which involve finite-length signal, these signals will be embedded into proper sequences, as we will see shortly.
Aperiodic Signals. The most general type of discrete-time signal is represented by a generic infinite complex sequence. Although, as previously mentioned, they lie beyond our processing and storage capabilities, they are invaluably useful as a generalization in the limit. As such, they must be handled with some care when it comes to their properties. We will see shortly that two of the most important properties of infinite sequences concern their summability: this can take the form of either absolute summability (stronger condition) or square summability (weaker condition, corresponding to finite energy).
|
|
Periodic Signals. A periodic sequence with period N is one for which
![˜x[n] = ˜x[n + kN ], k ∈ Z](livre62x.png) | (2.22) |
The tilde notation 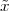 [n] will be used whenever we need to explicitly stress
a periodic behavior. Clearly an N-periodic sequence is completely
defined by its N values over a period; that is, a periodic sequence
“carries no more information” than a finite-length signal of length
N.
[n] will be used whenever we need to explicitly stress
a periodic behavior. Clearly an N-periodic sequence is completely
defined by its N values over a period; that is, a periodic sequence
“carries no more information” than a finite-length signal of length
N.
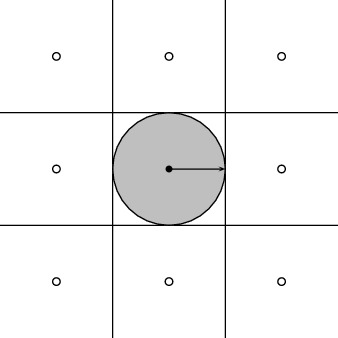
Periodic Extensions. Periodic sequences are infinite in length, and yet their information is contained within a finite number of samples. In this sense, periodic sequences represent a first bridge between finite-length signals and infinite sequences. In order to “embed” a finite-length signal x[n], n = 0,…,N - 1 into a sequence, we can take its periodized version:
![˜x[n] = x[n mod N ], n ∈ Z-](livre64x.png) | (2.23) |
this is called the periodic extension of the finite length signal x[n]. This
type of extension is the “natural” one in many contexts, for reasons
which will be apparent later when we study the frequency-domain
representation of discrete-time signals. Note that now an arbitrary
shift of the periodic sequence corresponds to the periodization of
a circular shift of the original finite-length signal. A circular shift
by k Z is easily visualized by imagining a shift register; if we are
shifting towards the right (k > 0), the values which pop out of the
rightmost end of the shift register are pushed back in at the other
end.(6)
The relationship between the circular shift of a finite-length signal and
the linear shift of its periodic extension is depicted in Figure 2.6.
Finally, the energy of a periodic extension becomes infinite, while its
power is simply the energy of the finite-length original signal scaled by
1∕N.
Finite-Support Signals. An infinite discrete-time sequence 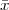 [n] is said to
have finite support if its values are zero for all indices outside of an interval;
that is, there exist N and M Z such that
[n] is said to
have finite support if its values are zero for all indices outside of an interval;
that is, there exist N and M Z such that
![¯x[n] = 0 for n < M and n > M + N - 1](livre66x.png)
Note that, although 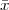 [n] is an infinite sequence, the knowledge of M and of
the N nonzero values of the sequence completely specifies the entire signal.
This suggests another approach to embedding a finite-length signal x[n],
n = 0,…,N - 1, into a sequence, i.e.
[n] is an infinite sequence, the knowledge of M and of
the N nonzero values of the sequence completely specifies the entire signal.
This suggests another approach to embedding a finite-length signal x[n],
n = 0,…,N - 1, into a sequence, i.e.
![{
x[n] if 0 ≤ n < N - 1
¯x[n] = n ∈ Z-
0 otherwise](livre68x.png) | (2.24) |
where we have chosen M = 0 (but any other choice of M could be
used). Note that, here, in contrast to the the periodic extension of
x[n], we are actually adding arbitrary information in the form of
the zero values outside of the support interval. This is not without
consequences, as we will see in the following Chapters. In general, we will
use the bar notation 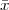 [n] for sequences defined as the finite support
extension of a finite-length signal. Note that, now, the shift of the
finite-support extension gives rise to a zero-padded shift of the signal
locations between M and M + N - 1; the dynamics of the shift are shown in
Figure 2.7.
[n] for sequences defined as the finite support
extension of a finite-length signal. Note that, now, the shift of the
finite-support extension gives rise to a zero-padded shift of the signal
locations between M and M + N - 1; the dynamics of the shift are shown in
Figure 2.7.
|
|
Example 2.1: Discrete-time in the Far West
The fact that the “fastest” digital frequency is 2π can be readily appreciated in old western movies. In classic scenarios there is always a sequence showing a stagecoach leaving town. We can see the spoked wagon wheels starting to turn forward faster and faster, then stop and then starting to turn backwards. In fact, each frame in the movie is a snapshot of a spinning disk with increasing angular velocity. The filming process therefore transforms the wheel’s movement into a sequence of discrete-time positions depicting a circular motion with increasing frequency. When the speed of the wheel is such that the time between frames covers a full revolution, the wheel appears to be stationary: this corresponds to the fact that the maximum digital frequency ω = 2π is undistinguishable from the slowest frequency ω = 0. As the speed of the real wheel increases further, the wheel on film starts to move backwards, which corresponds to a negative digital frequency. This is because a displacement of 2π + α between successive frames is interpreted by the brain as a negative displacement of α: our intuition always privileges the most economical explanation of natural phenomena.
Example 2.2: Building periodic signals
Given a discrete-time signal x[n] and an integer N > 0 we can always formally write
![∞∑
y˜[n] = x[n - kN ]
k=-∞](livre75x.png)
The signal ỹ[n], if it exists, is an N-periodic sequence. The periodic signal ỹ[n] is “manufactured” by superimposing infinite copies of the original signal x[n] spaced N samples apart. We can distinguish three cases:
|
|
The first two cases are illustrated in Figure 2.8. In practice, the periodization of short sequences is an effective method to synthesize the sound of string instruments such as a guitar or a piano; used in conjunction with simple filters, the technique is known as the Karplus-Strong algorithm.
As an example of the last type, take for instance the signal x[n] = α-n u[n]. The periodization formula leads to
| ỹ[n] | = ∑ k=-∞∞α-(n-kN)u[n - kN] = ∑ k=-∞⌊n∕N⌋α-(n-kN) |
| ỹ[n] | = ∑ k=-∞mα-(m-k)N-i = α-i ∑ h=0∞α-hN |
![-(n mod N)
˜y[n ] = α----------
1 - α-N](livre80x.png) | (2.25) |
which is indeed N-periodic. An example is shown in Figure 2.9.
|
|
For more discussion on discrete-time signals, see Discrete-Time Signal Processing, by A. V. Oppenheim and R. W. Schafer (Prentice-Hall, last edition in 1999), in particular Chapter 2.
Other books of interest include: B. Porat, A Course in Digital Signal Processing (Wiley, 1997) and R. L. Allen and D. W. Mills’ Signal Analysis (IEEE Press, 2004).
Exercise 2.1: Review of complex numbers.
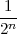 + j
+ j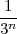 . Compute ∑
n=1∞s[n].
. Compute ∑
n=1∞s[n].
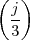 n.
n.
Exercise 2.2: Periodic signals. For each of the following discrete-time signals, state whether the signal is periodic and, if so, specify the period:
| © Presses polytechniques et universitaires romandes, 2008 All rights reserved |
In the 17th century, algebra and geometry started to interact in a fruitful synergy which continues to the present day. Descartes’s original idea of translating geometric constructs into algebraic form spurred a new line of attack in mathematics; soon, a series of astonishing results was produced for a number of problems which had long defied geometrical solutions (such as, famously, the trisection of the angle). It also spearheaded the notion of vector space, in which a geometrical point could be represented as an n-tuple of coordinates; this, in turn, readily evolved into the theory of linear algebra. Later, the concept proved useful in the opposite direction: many algebraic problems could benefit from our innate geometrical intuition once they were cast in vector form; from the easy three-dimensional visualization of concepts such as distance and orthogonality, more complex algebraic constructs could be brought within the realm of intuition. The final leap of imagination came with the realization that the concept of vector space could be applied to much more abstract entities such as infinite-dimensional objects and functions. In so doing, however, spatial intuition could be of limited help and for this reason, the notion of vector space had to be formalized in much more rigorous terms; we will see that the definition of Hilbert space is one such formalization.
Most of the signal processing theory which in this book can be usefully cast in terms of vector notation and the advantages of this approach are exactly what we have just delineated. Firstly of all, all the standard machinery of linear algebra becomes immediately available and applicable; this greatly simplifies the formalism used in the mathematical proofs which will follow and, at the same time, it fosters a good intuition with respect to the underlying principles which are being put in place. Furthermore, the vector notation creates a frame of thought which seamlessly links the more abstract results involving infinite sequences to the algorithmic reality involving finite-length signals. Finally, on the practical side, vector notation is the standard paradigm for numerical analysis packages such as Matlab; signal processing algorithms expressed in vector notation translate to working code with very little effort.
In the previous Chapter, we established the basic notation for the different classes of discrete-time signals which we will encounter time and again in the rest of the book and we hinted at the fact that a tight correspondence can be established between the concept of signal and that of vector space. In this Chapter, we pursue this link further, firstly by reviewing the familiar Euclidean space in finite dimensions and then by extending the concept of vector space to infinite-dimensional Hilbert spaces.
Euclidean geometry is a straightforward formalization of our spatial sensory experience; hence its cornerstone role in developing a basic intuition for vector spaces. Everybody is (or should be) familiar with Euclidean geometry and the natural “physical” spaces like R2 (the plane) and R3 (the three-dimensional space). The notion of distance is clear; orthogonality is intuitive and maps to the idea of a “right angle”. Even a more abstract concept such as that of basis is quite easy to contemplate (the standard coordinate concepts of latitude, longitude and height, which correspond to the three orthogonal axes in R3). Unfortunately, immediate spatial intuition fails us for higher dimensions (i.e. for RN with N > 3), yet the basic concepts introduced for R3 generalize easily to RN so that it is easier to state such concepts for the higher-dimensional case and specialize them with examples for N = 2 or N = 3. These notions, ultimately, will be generalized even further to more abstract types of vector spaces. For the moment, let us review the properties of RN, the N-dimensional Euclidean space.
Vectors and Notation. A point in RN is specified by an N-tuple of coordinates:(1)
![⌊ ⌋
| x0 |
|| x1 ||
x = | . | = [x0 x1 ... xN -1]T
|⌈ .. |⌉
xN -1](livre88x.png)
where xi R, i = 0,1,…,N - 1. We call this set of coordinates a
vector and the N-tuple will be denoted synthetically by the symbol x;
coordinates are usually expressed with respect to a “standard” orthonormal
basis.(2)
The vector
![0 = [ ]T
0 0 ... 0](livre89x.png)
i.e. the null vector, is considered the origin of the coordinate system.
The generic n-th element in vector x is indicated by the subscript xn. In
the following we will often consider a set of M arbitrarily chosen vectors in
RN and this set will be indicated by the notation  x(k)
x(k) k=0 …M-1.
Each vector in the set is indexed by the superscript ⋅(k). The n-th
element of the k-th vector in the set is indicated by the notation
xn(k)
k=0 …M-1.
Each vector in the set is indexed by the superscript ⋅(k). The n-th
element of the k-th vector in the set is indicated by the notation
xn(k)
Inner Product. The inner product between two vectors x,y RN is
defined as
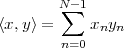 | (3.1) |
We say that x and y are orthogonal when their inner product is zero:
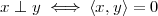 | (3.2) |
Norm. The norm of a vector is defined in terms of the inner product as
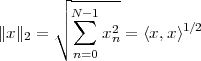 | (3.3) |
It is easy to visualize geometrically that the norm of a vector corresponds to
its length, i.e. to the distance between the origin and the point identified by
the vector’s coordinates. A remarkable property linking the inner product
and the norm is the Cauchy-Schwarz inequality (the proof of which is
nontrivial); given x,y RN we can state that
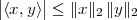
Distance. The concept of norm is used to introduce the notion of Euclidean distance between two vectors x and y:
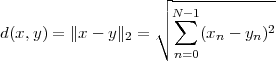 | (3.4) |
|
|
From this, we can easily derive the Pythagorean theorem for N dimensions: if two vectors are orthogonal, x ⊥ y, and we consider the sum vector z = x + y, we have
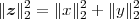 | (3.5) |
The above properties are graphically shown in Figure 3.1 for R2.
Bases. Consider a set of M arbitrarily chosen vectors in RN: {x(k)}k=0…M-1.
Given such a set, a key question is that of completeness: can any
vector in RN be written as a linear combination of vectors from the
set? In other words, we ask ourselves whether, for any z RN, we
can find a set of M coefficients αk R such that z can be expressed
as
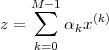 | (3.6) |
Clearly, M needs to be greater or equal to N, but what conditions does a set
of vectors {x(k)}k=0…M-1 need to satisfy so that (3.6) holds for any z RN?
There needs to be a set of M vectors that span RN, and it can be shown
that this is equivalent to saying that the set must contain at least N linearly
independent vectors. In turn, N vectors {y(k)}k=0…N-1 are linearly
independent if the equation
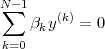 | (3.7) |
is satisfied only when all the βk’s are zero. A set of N linearly independent vectors for RN is called a basis and, amongst bases, the ones with mutually orthogonal vectors of norm equal to one are called orthonormal bases. For an orthonormal basis {y(k)} we therefore have
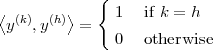 | (3.8) |
Figure 3.2 reviews the above concepts in low dimensions.
|
|
The standard orthonormal basis for RN is the canonical basis
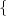 δ(k)
δ(k) k=0…N-1 with
k=0…N-1 with
![{
δ(k)= δ[n- k] = 1 if n = k
n 0 otherwise](livre105x.png)
The orthonormality of such a set is immediately apparent. Another important orthonormal basis for RN is the normalized Fourier basis {w(k)}k=0…N-1 for which
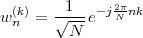
The orthonormality of the basis will be proved in the next Chapter.
The purpose of the previous Section was to briefly review the elementary notions and spatial intuitions of Euclidean geometry. A thorough study of vectors in RN and CN is the subject of linear algebra; yet, the idea of vectors, orthogonality and bases is much more general, the basic ingredients being an inner product and the use of a square norm as in (3.3).
While the analogy between vectors in CN and length-N signal is readily apparent, the question now hinges on how we are to proceed in order to generalize the above concepts to the class of infinite sequences. Intuitively, for instance, we can let N grow to infinity and obtain C∞ as the Euclidean space for infinite sequences; in this case, however, much care must be exercised with expressions such as (3.1) and (3.3) which can diverge for sequences as simple as x[n] = 1 for all n. In fact, the proper generalization of CN to an infinite number of dimensions is in the form of a particular vector space called Hilbert space; the structure of this kind of vector space imposes a set of constraints on its elements so that divergence problems, such as the one we just mentioned, no longer bother us. When we embed infinite sequences into a Hilbert space, these constraints translate to the condition that the corresponding signals have finite energy – which is a mild and reasonable requirement.
Finally, it is important to remember that the notion of Hilbert space is applicable to much more general vector spaces than CN; for instance, we can easily consider spaces of functions over an interval or over the real line. This generality is actually the cornerstone of a branch of mathematics called functional analysis. While we will not follow in great depth these kinds of generalizations, we will certainly point out a few of them along the way. The space of square integrable functions, for instance, will turn out to be a marvelous tool a few Chapters from now when, finally, the link between continuous—and discrete—time signals will be explored in detail.
A word of caution: we are now starting to operate in a world of complete abstraction. Here a vector is an entity per se and, while analogies and examples in terms of Euclidean geometry can be useful visually, they are, by no means, exhaustive. In other words: vectors are no longer just N-tuples of numbers; they can be anything. This said, a Hilbert space can be defined in incremental steps starting from a general notion of vector space and by supplementing this space with two additional features: the existence of an inner product and the property of completeness.
Vector Space. Consider a set of vectors V and a set of scalars S (which
can be either R or C for our purposes). A vector space H(V,S) is completely
defined by the existence of a vector addition operation and a scalar
multiplication operation which satisfy the following properties for any
x,y,z, V and any α,β S:
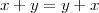 | (3.9) |
 | (3.10) |
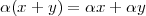 | (3.11) |
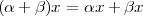 | (3.12) |
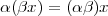 | (3.13) |
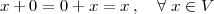 | (3.14) |
V there exists in V an additive inverse -x such
that
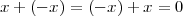 | (3.15) |
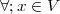 :
:
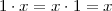 | (3.16) |
Inner Product Space. What we have so far is the simplest type of vector
space; the next ingredient which we consider is the inner product
which is essential to build a notion of distance between elements in
a vector space. A vector space with an inner product is called an
inner product space. An inner product for H(V,S) is a function from
V × V to S which satisfies the following properties for any x,y,z, V :
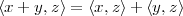 | (3.17) |
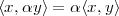 | (3.18) |
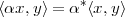 | (3.19) |
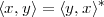 | (3.20) |
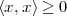 | (3.21) |
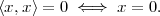 | (3.22) |
From this definition of the inner product, a series of additional definitions
and properties can be derived: first of all, orthogonality between two
vectors is defined with respect to the inner product, and we say that
the non-zero vectors x and y are orthogonal, or  , if and only
if
, if and only
if
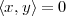 | (3.23) |
From the definition of an inner product, we can define the norm of a vector as (we will omit from now on the subscript 2 from the norme symbol):
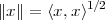 | (3.24) |
In turn, the norm satisfies the Cauchy-Schwartz inequality:
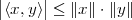 | (3.25) |
with strict equality if and only if x = αy. The norm also satisfies the triangle inequality:
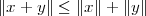 | (3.26) |
with strict equality if and only if x = αy and α R+. For orthogonal
vectors, the triangle inequality becomes the famous Pythagorean
theorem:
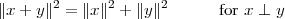 | (3.27) |
Hilbert Space. A vector space H(V,S) equipped with an inner product is called an inner product space. To obtain a Hilbert space, we need completeness. This is a slightly more technical notion, which essentially implies that convergent sequences of vectors in V have a limit that is also in V . To gain intuition, think of the set of rational numbers Q versus the set of real numbers R. The set of rational numbers is incomplete, because there are convergent sequences in Q which converge to irrational numbers. The set of real numbers contains these irrational numbers, and is in that sense the completion of Q. Completeness is usually hard to prove in the case of infinite-dimensional spaces; in the following it will be tacitly assumed and the interested reader can easily find the relevant proofs in advanced analysis textbooks. Finally, we will also only consider separate Hilbert spaces, which are the ones that admit orthonormal bases.
Finite Euclidean Spaces. The vector space CN, with the “natural” definition for the sum of two vectors z = x + y as
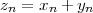 | (3.28) |
and the definition of the inner product as
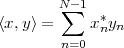 | (3.29) |
is a Hilbert space.
Polynomial Functions. An example of “functional” Hilbert space is
the vector space PN [0,1]
[0,1] of polynomial functions on the interval
[0,1] with maximum degree N. It is a good exercise to show that
P∞
of polynomial functions on the interval
[0,1] with maximum degree N. It is a good exercise to show that
P∞ [0,1]
[0,1] is not complete; consider for instance the sequence of
polynomials
is not complete; consider for instance the sequence of
polynomials
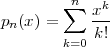
This series converges as ![p (x) → ex ⁄∈ P ([0,1])
n ∞](livre135x.png) .
.
Square Summable Functions. Another interesting example of functional
Hilbert space is the space of square integrable functions over a finite interval.
For instance, L2 [-π,π]
[-π,π] is the space of real or complex functions on the
interval [-π,π] which have a finite norm. The inner product over
L2
is the space of real or complex functions on the
interval [-π,π] which have a finite norm. The inner product over
L2 [-π,π]
[-π,π] is defined as
is defined as
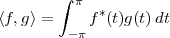 | (3.30) |
so that the norm of f(t) is
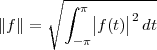 | (3.31) |
For f(t) to belong to L2 [-π,π]
[-π,π] it must be ∥f∥ < ∞.
it must be ∥f∥ < ∞.
The inner product is a fundamental tool in a vector space since it allows us
to introduce a notion of distance between vectors. The key intuition about
this is a typical instance in which a geometric construct helps us to
generalize a basic idea to much more abstract scenarios. Indeed, take the
simple Euclidean space RN and a given vector x; for any vector y RN the
inner product < x,y > is the measure of the orthogonal projection of y over
x. We know that the orthogonal projection defines the point on x
which is closest to y and therefore this indicates how well we can
approximate y by a simple scaling of x. To illustrate this, it should be noted
that
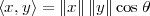
where θ is the angle between the two vectors (you can work out the expression in R2 to easily convince yourself of this; the result generalizes to any other dimension). Clearly, if the vectors are orthogonal, the cosine is zero and no approximation is possible. Since the inner product is dependent on the angular separation between the vectors, it represents a first rough measure of similarity between x and y; in broad terms, it provides a measure of the difference in shape between vectors.
In the context of signal processing, this is particularly relevant since most of the times, we are interested in the difference in shape” between signals. As we have said before, discrete-time signals are vectors; the computation of their inner product will assume different names according to the processing context in which we find ourselves: it will be called filtering, when we are trying to approximate or modify a signal or it will be called correlation when we are trying to detect one particular signal amongst many. Yet, in all cases, it will still be an inner product, i.e. a qualitative measure of similarity between vectors. In particular, the concept of orthogonality between signals implies that the signals are perfectly distinguishable or, in other words, that their shape is completely different.
The need for a quantitative measure of similarity in some applications calls for the introduction of the Euclidean distance, which is derived from the inner product as
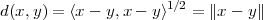 | (3.32) |
In particular, for CN the Euclidean distance is defined by the expression:
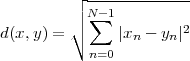 | (3.33) |
whereas for L2 [-π,π]
[-π,π] we have
we have
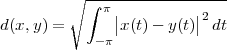 | (3.34) |
In the practice of signal processing, the Euclidean distance is referred to as the root mean square error;(4) this is a global, quantitative goodness-of-fit measure when trying to approximate signal y with x.
Incidentally, there are other types of distance measures which do not rely on a notion of inner product; for example in CN we could define
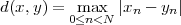 | (3.35) |
This distance is based on the supremum norm and is usually indicated by
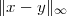 ; however, it can be shown that there is no inner product from
which this norm can be derived and therefore no Hilbert space can be
constructed where
; however, it can be shown that there is no inner product from
which this norm can be derived and therefore no Hilbert space can be
constructed where  is the natural norm. Nonetheless, this norm will
reappear later, in the context of optimal filter design.
is the natural norm. Nonetheless, this norm will
reappear later, in the context of optimal filter design.
Now that we have defined the properties of Hilbert space, it is only natural to start looking at the consequent inner structure of such a space. The best way to do so is by introducing the concept of basis. You can think of a basis as the “skeleton” of a vector space, i.e. a structure which holds everything together; yet, this skeleton is flexible and we can twist it, stretch it and rotate it in order to highlight some particular structure of the space and facilitate access to particular information that we may be seeking. All this is accomplished by a linear transformation called a change of basis; to anticipate the topic of the next Chapter, we will see shortly that the Fourier transform is an instance of basis change.
Sometimes, we are interested in exploring in more detail a specific subset of a given vector space; this is accomplished via the concept of subspace. A subspace is, as the name implies, a restricted region of the global space, with the additional property that it is closed under the usual vector operations. This implies that, once in a subspace, we can operate freely without ever leaving its confines; just like a full-fledged space, a subspace has its own skeleton (i.e. the basis) and, again, we can exploit the properties of this basis to highlight the features that interest us.
Assume H(V,S) is a Hilbert space, with V a vector space and S a set of scalars (i.e. C).
Subspace. A subspace of V is defined as a subset P ⊆ V that satisfies the following properties:
Clearly, V is a subspace of itself.
Span. Given an arbitrary set of M vectors W =  x(m)
x(m) m=0,1,…,M-1, the
span of these vectors is defined as
m=0,1,…,M-1, the
span of these vectors is defined as
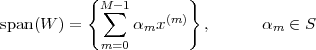 | (3.38) |
i.e. the span of W is the set of all possible linear combinations of the vectors in W. The set of vectors W is called linearly independent if the following holds:
 | (3.39) |
Basis. A set of K vectors W =  x(k)
x(k)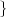 k=0,1,…,K-1 from a subspace P is a
basis for that subspace if
k=0,1,…,K-1 from a subspace P is a
basis for that subspace if
The last statement affirms that any y P can be written as a linear
combination of  x(k)
x(k)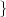 k=0,1,…,K-1 or that, for all y P, there exist K
coefficients αk such that
k=0,1,…,K-1 or that, for all y P, there exist K
coefficients αk such that
 | (3.40) |
which is equivalently expressed by saying that the set W is complete in P.
Orthogonal/Orthonormal Basis. An orthonormal basis for a subspace P
is a set of K basis vectors W =  x(k)
x(k) k=0,1,…,K-1 for which
k=0,1,…,K-1 for which
![⟨ (i) (j)⟩
x ,x = δ[i- j] 0 ≤ i,j < K](livre166x.png) | (3.41) |
which means orthogonality across vectors and unit norm. Sometimes, the set of vectors can be orthogonal but not normal (i.e. the norm of the vectors is not unitary). This is not a problem provided that we remember to include the appropriate normalization factors in the analysis and/or synthesis formulas. Alternatively, an lineary idependent set of vectors can be orthonormalized via the Gramm-Schmidt procedure, which can be found in any linear algebra textbook.
Among all bases, orthonormal bases are the most “beautiful” in a way because of their structure and their properties. One of the most important properties for finite-dimensional spaces is the following:
In other words, in finite dimensions, once we find a full set of orthogonal vectors, we are sure that the set spans the space.
Let W =  x(k)
x(k) k=0,1,…,K-1 be an orthonormal basis for a (sub)space
P. Then the following properties (all of which are easily verified)
hold:
k=0,1,…,K-1 be an orthonormal basis for a (sub)space
P. Then the following properties (all of which are easily verified)
hold:
Analysis Formula. The coefficients in the linear combination (3.40) are obtained simply as
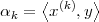 | (3.42) |
The coefficients {αk} are called the Fourier coefficients(5) of the orthonormal expansion of y with respect to the basis W and (3.42) is called the Fourier analysis formula; conversely, Equation (3.40) is called the synthesis formula.
Parseval’s Identity For an orthonormal basis, there is a norm conservation property given by Parseval’s identity:
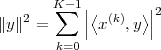 | (3.43) |
For physical quantities, the norm is dimensionally equivalent to a measure of energy; accordingly, Parseval’s identity is also known as the energy conservation formula.
Bessel’s Inequality. The generalization of Parseval’s equality is Bessel’s
inequality. In our subspace P, consider a set of L orthonormal vectors
 (a set which is not necessarily a basis since it may be L < K), with
G =
(a set which is not necessarily a basis since it may be L < K), with
G =  g(l)
g(l) l=1,2,…L-1; then the norm of any vector y P is lower bounded as
:
l=1,2,…L-1; then the norm of any vector y P is lower bounded as
:
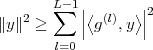 | (3.44) |
and the lower bound is reached for all y if and only if the system G is complete, that is, if it is an orthonormal basis for P.
Best Approximations. Assume P is a subspace of V ; if we try to
approximate a vector y V by a linear combination of basis vectors
from the subspace P, then we are led to the concepts of least squares
approximations and orthogonal projections. First of all, we define the
best linear approximation 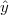 P of a general vector y V to be the
approximation which minimizes the norm
P of a general vector y V to be the
approximation which minimizes the norm  . Such approximation is
easily obtained by projecting y onto an orthonormal basis for P, as shown in
Figure 3.3. With W as our usual orthonormal basis for P, the projection is
given by
. Such approximation is
easily obtained by projecting y onto an orthonormal basis for P, as shown in
Figure 3.3. With W as our usual orthonormal basis for P, the projection is
given by
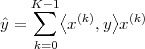 | (3.45) |
Define the approximation error as the vector d = y -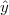 ; it can be easily
shown that:
; it can be easily
shown that:
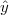 .
.
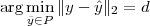 | (3.46) |
This approximation with an orthonormal basis has a key property: it can be successively refined. Assume you have the approximation with the first m terms of the orthonormal basis:
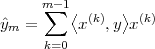 | (3.47) |
and now you want to compute the (m + 1)-term approximation. This is simply given by
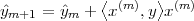 | (3.48) |
While this seems obvious, it is actually a small miracle, since it does not hold for more general, non-orthonormal bases.
|
|
Considering the examples of 3.2.2, we have the following:
Finite Euclidean Spaces. For the simplest case of Hilbert spaces, namely
CN, orthonormal bases are also the most intuitive since they contain exactly
N mutually orthogonal vectors of unit norm. The classical example is the
canonical basis  δ(k)
δ(k) k=0…N-1 with
k=0…N-1 with
![(k)
δn = δ[n - k]](livre188x.png) | (3.49) |
but we will soon study more interesting bases such as the Fourier basis
 w(k)
w(k) , for which
, for which
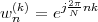
In CN, the analysis and synthesis formulas (3.42) and (3.40) take
a particularly neat form. For any set  x(k)
x(k) of N orthonormal
vectors one can indeed arrange the conjugates of the basis
vectors(6)
as the successive rows of an N × N square matrix M so that each
matrix element is the conjugate of the n-th element of the m-th basis
vector:
of N orthonormal
vectors one can indeed arrange the conjugates of the basis
vectors(6)
as the successive rows of an N × N square matrix M so that each
matrix element is the conjugate of the n-th element of the m-th basis
vector:
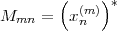
M is called a change of basis matrix. Given a vector y, the set of
expansion coefficient {αk}k=0…N-1 can now be written itself as a
vector(7)
α CN. Therefore, we can rewrite the analysis formula (3.42) in
matrix-vector form and we have
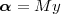 | (3.50) |
The reconstruction formula (3.40) for y from the expansion coefficients, becomes, in turn,
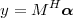 | (3.51) |
where the superscript denotes the Hermitian transpose (transposition and
conjugation of the matrix). The previous equation shows that y is a linear
combination of the columns of MH, which, in turn, are of course the
vectors  x(k)
x(k) . The orthogonality relation (3.49) takes the following
forms:
. The orthogonality relation (3.49) takes the following
forms:
| MHM | = I | (3.52) |
| MMH | = I | (3.53) |
Polynomial Functions. A basis for PN [0,1]
[0,1] is
is  xk
xk 0≤k<N. This basis,
however, is not an orthonormal basis. It can be transformed to an
orthonormal basis by a standard Gramm-Schmidt procedure; the basis vector
thus obtained are called Legendre polynomials.
0≤k<N. This basis,
however, is not an orthonormal basis. It can be transformed to an
orthonormal basis by a standard Gramm-Schmidt procedure; the basis vector
thus obtained are called Legendre polynomials.
Square Summable Functions. An orthonormal basis set for L2 [-π,π]
[-π,π] is the set
is the set  (1∕
(1∕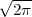 )exp(jnt)
)exp(jnt) n
n Z. This is actually the classic Fourier
basis for functions on an interval. Please note that, here, as opposed
to the previous examples, the number of basis vectors is actually
infinite. The orthogonality of these basis vectors is easily verifiable; their
completeness, however, is rather hard to prove and this, unfortunately,
is very much the rule for all non-trivial, infinite-dimensional basis
sets.
Z. This is actually the classic Fourier
basis for functions on an interval. Please note that, here, as opposed
to the previous examples, the number of basis vectors is actually
infinite. The orthogonality of these basis vectors is easily verifiable; their
completeness, however, is rather hard to prove and this, unfortunately,
is very much the rule for all non-trivial, infinite-dimensional basis
sets.
We are now in a position to formalize our intuitions so far, with respect to the equivalence between discrete-time signals and vector spaces, with a particularization for the three main classes of signals that we have introduced in the previous Chapter. Note that in the following, we will liberally interchange the notations x and x[n] to denote a sequence as a vector embedded in its appropriate Hilbert space.
The correspondence between the class of finite-length, length-N signals and CN should be so immediate at this point that it does not need further comment. As a reminder, the canonical basis is the canonical basis for CN. The k-th canonical basis vector is often expressed in signal form as
![δ[n - k] n = 0,...,N - 1, k = 0,...,N - 1](livre208x.png)
As we have seen, N-periodic signals are equivalent to length-N signals. The space of N-periodic sequences is therefore isomorphic to CN. In particular, the sum of two sequences considered as vectors is the standard pointwise sum for the elements:
![z[n] = x [n]+ y[n] n ∈ Z-](livre209x.png) | (3.54) |
while, for the inner product, we extend the summation over a period only:
![N -1
⟨x[n ],y[n]⟩ = ∑ x*[n]y[n ]
n=0](livre210x.png) | (3.55) |
The canonical basis for the space of N-periodic sequences is the canonical
basis for CN, because of the isomorphism; in general, any basis for CN is also
a basis for the space of N-periodic sequences. Sometimes, however, we will
also consider an explicitly periodized version of the basis. For the canonical
basis, in particular, the periodized basis is composed of N vectors of
infinite-length 
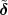 (k)}k=0…N-1 with
(k)}k=0…N-1 with
![∞
˜(k) ∑
δ = δ[n - k - iN ]
i=-∞](livre213x.png)
Such a sequence is called a pulse train. Note that here we are abandoning mathematical rigor, since the norm of each of these basis vectors is infinite; yet the pulse train, if handled with care, can be a useful tool in formal derivations.
In the case of infinite sequences, whose “natural” Euclidean space would appear to be C∞, the situation is rather delicate. While the sum of two sequences can be defined in the usual way, by extending the sum for CN to C∞, care must be taken when evaluating the inner product. We have already pointed out that the formula:
![⟨ ⟩ ∞∑ *
x[n],y[n] = x [n]y[n]
n=-∞](livre214x.png) | (3.56) |
can diverge even for simple constant sequences such as x[n] = y[n] = 1. A way out of this impasse is to restrict ourselves to ℓ2(Z), the space of square summable sequences, for which
![∑ | |2
∥x ∥2 = |x [n]| < ∞
n∈Z-](livre215x.png) | (3.57) |
This is the space of choice for all the theoretical derivations involving infinite sequences. Note that these sequences are often called “of finite energy”, since the square norm corresponds to the definition of energy as given in (2.19).
The canonical basis for ℓ2(Z) is simply the set  δ(k)
δ(k) kZ; in signal
form:
kZ; in signal
form:
![δ(k) = δ[n- k ], n, k ∈ Z
--](livre218x.png) | (3.58) |
This is an infinite set, and actually an infinite set of linearly independent vectors, since
![∑
δ[n - k] = αlδ[n - l]
l∈Z∕k](livre219x.png) | (3.59) |
has no solution for any k. Note that, for an arbitrary signal x[n] the analysis formula gives
![α = ⟨δ (k),x⟩ = ⟨δ[n - k],x[n ]⟩ = x[k]
k](livre220x.png)
so that the reconstruction formula becomes
![∑∞ (k) ∑∞
x[n ] = αk δ = x[k]δ[n- k ]
k=-∞ k=-∞](livre221x.png)
which is the reproducing formula (2.18). The Fourier basis for ℓ2(Z) will be introduced and discussed at length in the next Chapter.
As a last remark, note that the space of all finite-support signals, which is clearly a subset of ℓ2(Z), does not form a Hilbert space. Clearly, the space is closed under addition and scalar multiplication, and the canonical inner product is well behaved since all sequences have only a finite number of nonzero values. However, the space is not complete; to clarify this, consider the following family of signals:
![{
yk[n] = 1∕n |n| < k
0 otherwise](livre222x.png)
For k growing to infinity, the sequence of signals converges as yk[n] → y[n] = 1∕n for all n; while y[n] is indeed in ℓ2(Z), since
y[n] is clearly not a finite-support signal.
A comprehensive review of linear algebra, which contains all the concepts of Hilbert spaces but in finite dimensions, is the classic by G. Strang, Linear Algebra and Its Applications (Brooks Cole, 2005). For an introduction to Hilbert spaces, there are many mathematics books; we suggest N. Young, An Introduction to Hilbert Space (Cambridge University Press, 1988). As an alternative, a more intuitive and engineering-motivated approach is in the classic book by D. G. Luenberger, Optimization by Vector Space Methods (Wiley, 1969).
Exercise 3.1: Elementary operators. An operator  is a transformation
of a given signal and is indicated by the notation
is a transformation
of a given signal and is indicated by the notation
![{ }
y[n] = H x[n]](livre224x.png)
For instance, the delay operator  is indicated as
is indicated as
![{ }
D x[n] = x[n - 1]](livre225x.png)
and the one-step difference operator is indicated as
![{ } { }
V x [n] = x[n]- D x[n] = x[n ]- x[n- 1]](livre226x.png) | (3.60) |
A linear operator is one for which the following holds:
![{ H {αx [n ]} = αH {x [n]}
{ } { } { }
H x[n ]+ y[n ] = H x[n] +H y[n ]](livre227x.png)
is linear.
 is linear.
is linear.
 x[n]
x[n] = x2[n] is not linear.
= x2[n] is not linear.In CN, any linear operator on a vector x can be expressed as a matrix-vector multiplication for a suitable N × N matrix A. In CN, we define the delay operator as the left circular shift of a vector:
![{ } T
D x = [xN -1 x0 x1 ... xN -2]](livre230x.png)
Assume N = 4 for convenience; it is easy to see that
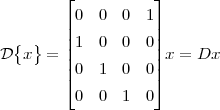
so that D is the matrix associated to the delay operator.
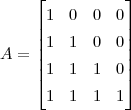
Which operator do you think it is associated to? What does the operator do?
Exercise 3.2: Bases. Let  x(k)
x(k) k=0,…,N-1 be a basis for a subspace S.
Prove that any vector z S is uniquely represented in this basis.
k=0,…,N-1 be a basis for a subspace S.
Prove that any vector z S is uniquely represented in this basis.
Hint: prove by contradiction.
Exercise 3.3: Vector spaces and signals.
![[a1,a2,...,an]+ [b1,b2,...,bn] = [a1 + b1,a2 + b2,...,an + bn]](livre235x.png)
and the multiplication by a scalar:
![α[a1,a2,...,an] = [αa1,αa2,...,αan ]](livre236x.png)
form a vector space. Give its dimension and find a basis.
Exercise 3.4: The Haar basis. Consider the following change of basis matrix in C8, with respect to the standard orthonormal basis:

Note the pattern in the first four rows, in the next two, and in the last two.
The basis described by H is called the Haar basis and it is one of the most celebrated cornerstones of a branch of signal processing called wavelet analysis. To get a feeling for its properties, consider the following set of numerical experiments (you can use Matlab or any other numerical package):
![{x = [1 1 ... 1]}](livre238x.png)
and compute its coefficients in the Haar basis.
![{x = [+1 - 1 +1 ... +1 - 1]}](livre239x.png)
and compute its coefficients in the Haar basis.
| © Presses polytechniques et universitaires romandes, 2008 All rights reserved |
Fourier theory has a long history, from J. Fourier’s early work on the transmission of heat to recent results on non-harmonic Fourier series. Fourier theory is a branch of harmonic analysis, and in that sense, a topic in pure and applied mathematics. At the same time, because of its usefulness in practical applications, Fourier analysis is a key tool in several engineering branches, and in signal processing in particular.
Why is Fourier analysis so important? To understand this, let us take a short philosophical detour. Interesting signals are time-varying quantities: you can imagine, for instance, the voltage level at the output of a microphone or the measured level of the tide at a particular location; in all cases, the variation of a signal, over time, implies that a transfer of energy is happening somewhere, and ultimately this is what we want to study. Now, a time-varying value which only increases over time is not only a physical impossibility but a recipe for disaster for whatever system is supposed to deal with it; fuses will blow, wires will melt and so on. Oscillations, on the other hand, are nature’s and man’s way of keeping things in motion without trespassing all physical bounds; from Maxwell’s wave equation to the mechanics of the vocal cords, from the motion of an engine to the ebb and flow of the tide, oscillatory behavior is the recurring theme. Sinusoidal oscillations are the purest form of such a constrained motion and, in a nutshell, Fourier’s immense contribution was to show that (at least mathematically) one could express any given phenomenon as the combined output of a number of sinusoidal “generators”.
Sinusoids have another remarkable property which justifies their ubiquitous presence. Indeed, any linear time-invariant transformation of a sinusoid is a sinusoid at the same frequency: we express this by saying that sinusoidal oscillations are eigenfunctions of linear time-invariant systems. This is a formidable tool for the analysis and design of signal processing structures, as we will see in much detail in the context of discrete-time filters.
The purpose of the present Chapter is to introduce and analyze some key results on Fourier series and Fourier transforms in the context of discrete-time signal processing. It appears that, as we mentioned in the previous Chapter, the Fourier transform of a signal is a change of basis in an appropriate Hilbert space. While this notion constitutes an extremely useful unifying framework, we also point out the peculiarities of its specialization within the different classes of signal. In particular, for finite-length signals we highlight the eminently algebraic nature of the transform, which leads to efficient computational procedures; for infinite sequences, we will analyze some of its interesting mathematical subtleties.
The Fourier transform of a signal is an alternative representation of the data in the signal. While a signal lives in the time domain,(1) its Fourier representation lives in the frequency domain. We can move back and forth at will from one domain to the other using the direct and inverse Fourier operators, since these operators are invertible.
In this Chapter we study three types of Fourier transform which apply to the three main classes of signals that we have seen so far:
The frequency representation of a signal (given by a set of coefficients in the case of the DFT and DFS and by a frequency distribution in the case of the DTFT) is called the spectrum.
The basic ingredient of all the Fourier transforms which follow, is the discrete-time complex exponential; this is a sequence of the form:
![x [n] = A ej(ωn+φ) = A[cos(ωn + φ) + jsin(ωn + φ )]](livre240x.png) |
A complex exponential represents an oscillatory behavior; A R is the
amplitude of the oscillation, ω is its frequency and φ is its initial phase.
Note that, actually, a discrete-time complex exponential sequence is
not always a periodic sequence; it is periodic only if ω = 2π(M∕N)
for some value of M,N Z. The power of a complex exponential is
equal to the average energy over a period, i.e. |A|2, irrespective of
frequency.
In the introduction, we hinted at the fact that Fourier analysis allows us to decompose a physical phenomenon into oscillatory components. However, it may seem odd, that we have chosen to use complex oscillation for the analysis of real-world signals. It may seem even odder that these oscillations can have a negative frequency and that, as we will soon see in the context of the DTFT, the spectrum extends over to the negative axis.
The starting point in answering these legitimate questions is to recall that the use of complex exponentials is essentially a matter of convenience. One could develop a complete theory of frequency analysis for real signals using only the basic trigonometric functions. You may actually have noticed this if you are familiar with the Fourier Series of a real function; yet the notational overhead is undoubtedly heavy since it involves two separate sets of coefficients for the sine and cosine basis functions, plus a distinct term for the zero-order coefficient. The use of complex exponentials elegantly unifies these separate series into a single complex-valued sequence. Yet, one may ask again, what does it mean for the spectrum of a musical sound to be complex? Simply put, the complex nature of the spectrum is a compact way of representing two concurrent pieces of information which uniquely define each spectral component: its frequency and its phase. These two values form a two-element vector in R2 but, since R2 is isomorphic to C, we use complex numbers for their mathematical convenience.
With respect negative frequencies, one must first of all consider, yet again, a basic complex exponential sequence such as x[n] = exp(jωn). We can visualize its evolution over discrete-time as a series of points on the unit circle in the complex plane. At each step, the angle increases by ω, defining a counterclockwise circular motion. It is easy to see that a complex exponential sequence of frequency -ω is just the same series of points with the difference that the points move clockwise instead; this is illustrated in detail in Figure 4.1. If we decompose a real signal into complex exponentials, we will show that, for any given frequency value, the phases of the positive and negative components are always opposite in sign; as the two oscillations move in opposite directions along the unit circle, their complex part will always cancel out exactly, thus returning a purely real signal.(2)
|
|
The final step in developing a comfortable feeling for complex oscillations comes from the realization that, in the synthesis of discrete-time signals (and especially in the case of communication systems) it is actually more convenient to work with complex-valued signals, themselves. Although the transmitted signal of a device like an ADSL box is a real signal, the internal representation of the underlying sequences is complex; therefore complex oscillations become a necessity.
We now develop a Fourier representation for finite-length signals; to do so, we need to find a set of oscillatory signals of length N which contain a whole number of periods over their support. We start by considering a family of finite-length sinusoidal signals (indexed by an integer k) of the form
![jωkn
wk[n] = e , n = 0,...,N - 1](livre243x.png) | (4.1) |
where all the ωk’s are distinct frequencies which fulfill our requirements. To determine these frequency values, note that, in order for wk[n] to contain a whole number of periods over N samples, it must conform to
![wk [N] = wk[0] = 1](livre244x.png)
which translates to
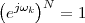
The above equation has N distinct solutions which are the N roots of unity exp(j2πm∕N), m = 0,…,N - 1; if we define the complex number
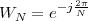
then the family of N signals in (4.1) can be written as
![-nk
wk [n] = W N , n = 0,...,N - 1](livre247x.png) | (4.2) |
for each value of k = 0,…,N - 1. We can represent these N signals as a set of
vectors  w(k)
w(k) k=0,…,N-1 in CN with
k=0,…,N-1 in CN with
![(k) [ -k -2k -(N-1)k]T
w = 1 W N W N ... W N](livre250x.png) | (4.3) |
The real and imaginary parts of w(k) for N = 32 and for some values of k are plotted in Figures 4.2 to 4.5.
We can verify that  w(k)
w(k) k=0,…,N-1 is a set of N orthogonal vectors and
therefore a basis for CN; indeed we have (noting that
k=0,…,N-1 is a set of N orthogonal vectors and
therefore a basis for CN; indeed we have (noting that  WN-k
WN-k * = WNk):
* = WNk):
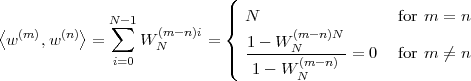 | (4.4) |
since WNiN = 1 for all i Z. In more compact notation we can therefore
state that
![⟨ ⟩
w(m ),w (n) = N δ[n- m ]](livre256x.png) | (4.5) |
The vectors  w(k)
w(k) k=0,…,N-1 are the Fourier basis for CN, and therefore for
the space of length-N signals. It is immediately evident that this basis
is not orthonormal, since
k=0,…,N-1 are the Fourier basis for CN, and therefore for
the space of length-N signals. It is immediately evident that this basis
is not orthonormal, since  w(k)
w(k) 2 = N, but that it could be made
orthonormal simply by scaling the basis vectors by (1∕
2 = N, but that it could be made
orthonormal simply by scaling the basis vectors by (1∕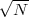 ). In signal
processing practice, however, it is customary to keep the normalization
factor explicit in the change of basis formulas; this is mostly due
to computational reasons, as we will see later, but, for the sake of
consistency with the mainstream literature, we will also follow this
convention.
). In signal
processing practice, however, it is customary to keep the normalization
factor explicit in the change of basis formulas; this is mostly due
to computational reasons, as we will see later, but, for the sake of
consistency with the mainstream literature, we will also follow this
convention.
The Discrete Fourier Transform (DFT) analysis and synthesis formulas can
now be easily expressed in the familiar matrix notation as in Section 3.3.3:
define an N × N square matrix W by stacking the conjugate of the basis
vectors, i.e. Wnk = exp(-j(2π∕N)nk) = WNnk; from this we can state, for
all vectors x CN:
| X | = Wx | (4.6) |
| x | = 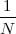 WHX WHX | (4.7) |
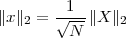 | (4.8) |
(once again, note the explicit normalization factor).
It is very common in the literature to explicitly write out the inner products in (4.6) and (4.7); this is both for historical reasons and to underscore the highly structured form of this transformation which, as we will see, is the basis for very efficient computational procedures. In detail, we have the analysis formula
![N -1
X [k] = ∑ x[n]W nk, k = 0,...,N - 1
N
n=0](livre264x.png) | (4.9) |
and the dual synthesis formula
![N∑-1
x [n] = 1- X [k]W -nk, n = 0,...,N - 1
N k=0 N](livre265x.png) | (4.10) |
where we have used the standard convention of “lumping” the normalizing factor (1∕N) entirely within in the reconstruction sum (4.10).
To return to the physical interpretation of the DFT, what we have just obtained is the decomposition of a finite-length signal into a set of N sinusoidal components; the magnitude and initial phase of each oscillator are given by the coefficients X[k] in (4.9) (or, equivalently, by the vector elements Xk in (4.6)(3) ). To stress the point again:
 X[k]
X[k] , i.e. to the
magnitude of the k-th DFT coefficient;
, i.e. to the
magnitude of the k-th DFT coefficient;
The first N output values of this “machine” are exactly x[n].
If we look at this from the opposite end, each X[k] shows “how much”
oscillatory behavior at frequency 2π∕k, is contained in the signal; this is
consistent with the fact that an inner product is a measure of similarity. The
coefficients X[k] are referred to as the spectrum of the signal. The square
magnitude  X[k]
X[k] 2 is a measure (up to a scale factor N) of the signal’s
energy at the frequency (2π∕N)k; the coefficients X[k], therefore, show
exactly how the global energy of the original signal is distributed
in the frequency domain while Parseval’s equality (4.8) guarantees
that the result is consistent. The phase of each Fourier coefficient,
indicated by ∡X[k], specifies the initial phase of each oscillator for the
reconstruction formula, i.e. the relative alignment of each complex
exponential at the onset of the signal. While this does not influence the
energy distribution in frequency, it does have a significant effect on the shape
of the signal in the discrete-time domain as we will shortly see in more
detail.
2 is a measure (up to a scale factor N) of the signal’s
energy at the frequency (2π∕N)k; the coefficients X[k], therefore, show
exactly how the global energy of the original signal is distributed
in the frequency domain while Parseval’s equality (4.8) guarantees
that the result is consistent. The phase of each Fourier coefficient,
indicated by ∡X[k], specifies the initial phase of each oscillator for the
reconstruction formula, i.e. the relative alignment of each complex
exponential at the onset of the signal. While this does not influence the
energy distribution in frequency, it does have a significant effect on the shape
of the signal in the discrete-time domain as we will shortly see in more
detail.
Some examples for signals in C64 are plotted in Figures 4.6–4.9. Figure 4.6 shows one of the simplest cases: indeed, the signal x[n] is a sinusoid whose frequency coincides with that of one of the basis vectors (precisely, to that of w(4)) and, as a consequence of the orthogonality of the basis, only X[4] and X[60] are nonzero (this can be easily verified by decomposing the sinusoid as the sum of two appropriate basis functions). Figure 4.7 shows the same signal, but this time with a phase offset.
The magnitude DFT does not change, but the phase offset appears in the phase of the transform. Figure 4.8 shows the transform of a sinusoid whose frequency does not coincide with any of the basis frequencies. As a consequence, all of the basis vectors are needed to reconstruct the signal. Clearly, the magnitude is larger for frequencies closer to hot of the original signal’s (6π∕64 and 7π∕64 in this case); yet, to reconstruct x[n] exactly, we need the contribution of the entire basis. Finally, Figure 4.9 shows the DFT of a step signal. It can be shown (with a few trigonometric manipulations) that the DFT of a step signal is
![( )
sin--(π(-∕N)M--k)- -jNπ(M- 1)k
X [k] = sin (π∕N )k e](livre278x.png)
where N is the length of the signal and M is the length of the step (in Figure 4.9 N = 64 and M = 5, for instance.)
Consider the reconstruction formula in (4.10); what happens if we let the
index n roam outside of the [0,N - 1] interval? Since WN(n+iN)k = WNnk
for all i Z, we note that x[n + iN] = x[n]. In other words, the
reconstruction formula in (4.10) implicitly defines a periodic sequence of
period N. This is the reason why, earlier, we stated that periodic sequences
are the natural way to embed a finite-length signal into a sequence: their
Fourier representation is formally identical. This is not surprising since a) we
have already established a correspondence between CN and 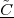 N and b) we
are actually expressing a length-N sequence as a combination of N-periodic
basis signals.
N and b) we
are actually expressing a length-N sequence as a combination of N-periodic
basis signals.
The Fourier representation of periodic sequences is called the Discrete
Fourier Series (DFS), and its explicit analysis and synthesis formulas are the
exact equivalent of (4.9) and (4.10), modified only with respect to the range
of the indices. We have already seen that in (4.10), the reconstruction
formula, n is now in Z. Symmetrically, due to the N-periodicity of WNk, we
can let the index k in (4.9) assume any value in Z too; this way, the
DFS coefficients become an N-periodic sequence themselves and the
DFS becomes a change of basis in  N using the definition of inner
product given in Section (3.4.2) and the formal periodic basis for
N using the definition of inner
product given in Section (3.4.2) and the formal periodic basis for
 N:
N:
 [k] [k] | = ∑
n=0N-1 [n]W
Nnk, k Z [n]W
Nnk, k Z | (4.11) |
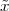 [n] [n] | = 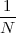 ∑
k=0N-1 ∑
k=0N-1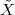 [k]W
N-nk, n Z [k]W
N-nk, n Z | (4.12) |
We now consider a Fourier representation for infinite non-periodic sequences. From a purely mathematical point of view, the Discrete-Time Fourier Transform of a sequence x[n] is defined as
![∑∞
X (ejω ) = x[n ]e-jωn
n=- ∞](livre302x.png) | (4.13) |
The DTFT is therefore a complex-valued function of the real argument ω, and, as can be easily verified, it is periodic in ω with period 2π. The somewhat odd notation X(exp(jω)) is quite standard in the signal processing literature and offers several advantages:
The DTFT, when it exists, can be inverted via the integral
![∫ π
x[n ] =-1- X (ejω )ejωnd ω
2π - π](livre303x.png) | (4.14) |
as can be easily verified by substituting (4.13) into 4.14) and using
![∫ π
e- jω(n-k) = 2πδ[n - k]
-π](livre304x.png)
In fact, due to the 2π-periodicity of the DTFT, the integral in (4.14) can be computed over any 2π-wide interval on the real line (i.e. between 0 and 2π, for instance). The relation between a sequence x[n] and its DTFT X(exp(jω)) will be indicated in the general case by
![x [n] DT←F→T X (ejω )](livre305x.png)
While the DFT and DFS were signal transformations which involved only a finite number of quantities, both the infinite summation and the real-valued argument, appearing in the DTFT, can create an uneasiness which overshadows the conceptual similarities between the transforms. In the following, we start by defining the mathematical properties of the DTFT and we try to build an intuitive feeling for this Fourier representation, both with respect to its physical interpretation and to its conformity to the “change of basis” framework, that we used for the DFT and DFS.
Mathematically, the DTFT is a transform operator which maps discrete-time sequences onto the space of 2π-periodic functions. Clearly, for the DTFT to exist, the sum in (4.13) must converge, i.e. the limit for M →∞ of the partial sum
![M
jω ∑ - jωn
XM (e ) = x[n ]e
n=-M](livre306x.png) | (4.15) |
must exist and be finite. Convergence of the partial sum in (4.15) is very easy to prove for absolutely summable sequences, that is for sequences satisfying
![∑M | |
M li→m∞ = |x[n]| < ∞
n=- M](livre307x.png) | (4.16) |
since, according to the triangle inequality,
![|| jω || M∑ || - jωn || ∑M || ||
XM (e ) ≤ x[n ]e = x[n]
n=-M n=- M](livre308x.png) | (4.17) |
For this class of sequences it can also be proved that the convergence of XM(exp(jω)) to X(exp(jω)) is uniform and that X(exp(jω)) is continuous. While absolute summability is a sufficient condition, it can be shown that the sum in (4.15) is convergent also for all square-summable sequences, i.e. for sequences whose energy is finite; this is very important to us with respect to the discussion in Section 3.4.3 where we defined the Hilbert space ℓ2(Z). In the case of square summability only, however, the convergence of (4.15) is no longer uniform but takes place only in the mean-square sense, i.e.
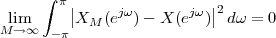 | (4.18) |
Convergence in the mean square sense implies that, while the total energy of the error signal becomes zero, the pointwise values of the partial sum may never approach the values of the limit. One manifestation of this odd behavior is called the Gibbs phenomenon, which has important consequences in our approach to filter design, as we will see later. Furthermore, in the case of square-summable sequences, X(exp(jω)) is no longer guaranteed to be continuous.
As an example, consider the sequence:
![{
1 for - N ≤ n ≤ N
x[n] =
0 otherwise](livre310x.png) | (4.19) |
Its DTFT can be computed as the sum(4)
| X(ejω) | = ∑ n=-NNe-jωn | ||
| = ∑ n=1Nejωn + ∑ n=0Ne-jωn | |||
= 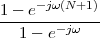 + + 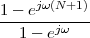 - 1 - 1 | |||
= ejω∕2 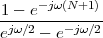 + e-jω∕2 + e-jω∕2 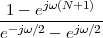 - 1 - 1 | |||
= 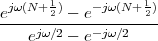 | |||
= 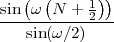 |
|
|
The DTFT of this particular signal turns out to be real (we will see later that this is a consequence of the signal’s symmetry) and it is plotted in Figure 4.10. When, as is very often the case, the DTFT is complex-valued, the usual way to represent it graphically takes the magnitude and the phase separately into account. The DTFT is always a 2π-periodic function and the standard convention is to plot the interval from -π to π. Larger intervals can be considered if the periodicity needs to be made explicit; Figure 4.11, for instance, shows five full periods of the same function.
|
|
A way to gain some intuition about the structure of the DTFT formulas is to consider the DFS of periodic sequences with larger and larger periods. Intuitively, as we look at the structure of the Fourier basis for the DFS, we can see that the number of basis vectors in (4.9) grows with the length N of the period and, consequently, the frequencies of the underlying complex exponentials become “denser” between 0 and 2π. We want to show that, in the limit, we end up with the reconstruction formula of the DTFT.
To do so, let us restrict ourselves to the domain of absolute summable
sequences; for these sequences, we know that the sum in (4.13) exists. Now,
given an absolutely summable sequence x[n], we can always build an
N-periodic sequence  [n] as
[n] as
![∑∞
˜x[n] = x[n + iN]
i=-∞](livre321x.png) | (4.20) |
for any value of N (see Example 2.2); this is guaranteed by the fact that the
above sum converges for all n Z (because of the absolute summability of
x[n]) so that all values of  [n] are finite. Clearly, there is overlap
between successive copies of x[n]; the intuition, however, is the following:
since in the end we will consider very large values for N and since
x[n], because of absolute summability, decays rather fast with n, the
resulting overlap of “tails” will be negligible. This can be expressed
as
[n] are finite. Clearly, there is overlap
between successive copies of x[n]; the intuition, however, is the following:
since in the end we will consider very large values for N and since
x[n], because of absolute summability, decays rather fast with n, the
resulting overlap of “tails” will be negligible. This can be expressed
as
![lim x˜[n] = x[n]
N →∞](livre323x.png)
Now consider the DFS of 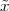 [n]:
[n]:
![( )
˜ N∑ -1 -j2πnk ∞∑ N∑-1 - j2π(n+iN)k
X [k] = ˜x[n]e N = x [n + iN ]e N
n=0 i= -∞ n=0](livre325x.png) | (4.21) |
where in the last term we have used (4.20), interchanged the order of the summation and exploited the fact that exp(-j(2π∕N)(n + iN)k) = exp(-j(2π∕N)nk). We can see that, for every value of i in the outer sum, the argument of the inner sum varies between iN and iN + N - 1, i.e. non-overlapping intervals, so that the double summation can be simplified as
![∞
˜ ∑ -j2πmk
X [k] = x [m ]e N
m= -∞](livre326x.png) | (4.22) |
and therefore
![|
X˜[k] = X (ejω)|ω= 2πk
N](livre327x.png) | (4.23) |
This already gives us a noteworthy piece of intuition: the DFS coefficients for the periodized signal are a discrete set of values of its DTFT (here considered solely as a formal operator) computed at multiples of 2π∕N. As N grows, the spacing between these frequency intervals narrows more and more so that, in the limit, the DFS converges to the DTFT.
To check that this assertion is consistent, we can now write the DFS reconstruction formula using the DFS values given to us by inserting (4.23) in (4.10):
![N∑-1
˜x[n] = 1- X (ej2Nπk)ej2πN-nk
N k=0](livre328x.png) | (4.24) |
By defining Δ = (2π∕N), we can rewrite the above expression as
![N- 1
x˜[n] = -1-∑ X (ej(kΔ))ej(kΔ )n Δ
2π
k=0](livre329x.png) | (4.25) |
and the summation is easily recognized as the Riemann sum with step Δ
approximating the integral of f(ω) = X(ejω)ejωn between 0 and 2π.
As N goes to infinity (and therefore  [n] → x[n]), we can therefore
write
[n] → x[n]), we can therefore
write
![1 ∫ 2π
˜x[n] → --- X (ejω)ejωndω
2π 0](livre331x.png) | (4.26) |
which is indeed the DTFT reconstruction formula (4.14).(5)
We now show that, if we are willing to sacrifice mathematical rigor, the DTFT can be cast in the same conceptual framework we used for the DFT and DFS, namely as a basis change in a vector space. The following formulas are to be taken as nothing more than a set of purely symbolic derivations, since the mathematical hypotheses under which the results are well defined are far from obvious and are completely hidden by the formalism. It is only fair to say, however, that the following expressions represent a very handy and intuitive toolbox to grasp the essence of the duality between the discrete-time and the frequency domains and that they can be put to use very effectively to derive quick results when manipulating sequences.
One way of interpreting Equation (4.13) is to see that, for any given value ω0, the corresponding value of the DTFT is the inner product in ℓ2(Z) of the sequence x[n] with the sequence exp(jω0n); formally, at least, we are still performing a projection in a vector space akin to C∞:
![⟨ ⟩
X (ejω) = ejωn,x[n]](livre332x.png)
Here, however, the set of “basis vectors” {exp(jωn)}ωR is indexed by the
real variable ω and is therefore uncountable. This uncountability is
mirrored in the inversion formula (4.14), in which the usual summation
is replaced by an integral; in fact, the DTFT operator maps ℓ2(Z)
onto L2 [-π,π]
[-π,π] which is a space of 2π-periodic, square integrable
functions. This interpretation preserves the physical meaning given
to the inner products in (4.13) as a way to measure the frequency
content of the signal at a given frequency; in this case the number of
oscillators is infinite and their frequency separation becomes infinitesimally
small.
which is a space of 2π-periodic, square integrable
functions. This interpretation preserves the physical meaning given
to the inner products in (4.13) as a way to measure the frequency
content of the signal at a given frequency; in this case the number of
oscillators is infinite and their frequency separation becomes infinitesimally
small.
To complete the picture of the DTFT as a change of basis, we want to show
that, at least formally, the set {exp(jωn)}ωR constitutes an orthogonal “basis” for
ℓ2(Z).(6)
In order to do so, we need to introduce a quirky mathematical entity called
the Dirac delta functional; this is defined in an implicit way by the following
formula
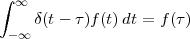 | (4.27) |
where f(t) is an arbitrary integrable function on the real line; in particular
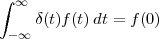 | (4.28) |
While no ordinary function satisfies the above equation, δ(t) can be interpreted as shorthand for a limiting operation. Consider, for instance, the family of parametric functions(7)
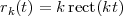 | (4.29) |
which are plotted in Figure 4.12. For any continuous function f(t) we can write
![∫ ∞ ∫ 1∕2k |
rk(t)f(t)dt = k f(t)dt = f(γ)|γ∈[-1∕2k,1∕2k]
-∞ -1∕2k](livre339x.png) | (4.30) |
where we have used the Mean Value theorem. Now, as k goes to infinity, the
integral converges to f(0); hence we can say that the limit of the series of
functions rk(t) converges then to the Dirac delta. As already stated, the
delta cannot be considered as a proper function, so the expression δ(t)
outside of an integral sign has no mathematical meaning; it is customary
however to associate an “idea” of function to the delta and we can think of it
as being undefined for t 0 and to have a value of ∞ at t = 0. This
interpretation, together with (4.27), defines the so-called sifting property of
the Dirac delta; this property allows us to write (outside of the integral
sign):
0 and to have a value of ∞ at t = 0. This
interpretation, together with (4.27), defines the so-called sifting property of
the Dirac delta; this property allows us to write (outside of the integral
sign):
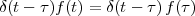 | (4.31) |
The physical interpretation of the Dirac delta is related to quantities expressed as continuous distributions for which the most familiar example is probably that of a probability distribution (pdf). These functions represent a value which makes physical sense only over an interval of nonzero measure; the punctual value of a distribution is only an abstraction. The Dirac delta is the operator that extracts this punctual value from a distribution, in a sense capturing the essence of considering smaller and smaller observation intervals.
To see how the Dirac delta applies to our basis expansion, note that equation (4.27) is formally identical to an inner product over the space of functions on the real line; by using the definition of such an inner product we can therefore write
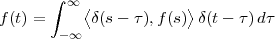 | (4.32) |
which is, in turn, formally identical to the reconstruction formula of Section 3.4.3. In reality, we are interested in the space of 2π-periodic functions, since that is where DTFTs live; this is easily accomplished by building a 2π-periodic version of the delta as
 | (4.33) |
where the leading 2π factor is for later convenience. The resulting object is
called a pulse train, similarly to what we built for the case of periodic
sequences in 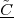 N. Using the pulse train and given any 2π-periodic function
f(ω), the reconstruction formula (4.32) becomes
N. Using the pulse train and given any 2π-periodic function
f(ω), the reconstruction formula (4.32) becomes
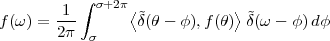 | (4.34) |
for any σ R.
Now that we have the delta notation in place, we are ready to start.
First of all, we show the formal orthogonality of the basis functions
{exp(jωn)}ωR. We can write
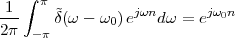 | (4.35) |
The left-hand side of this equation has the exact form of the DTFT reconstruction formula (4.14); hence we have found the fundamental relationship
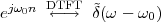 | (4.36) |
Now, the DTFT of a complex exponential exp(jσn) is, in our change of basis interpretation, simply the inner product ⟨exp(jωn),exp(jσn)⟩; because of (4.36) we can therefore express this as
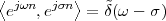 | (4.37) |
which is formally equivalent to the orthogonality relation in (4.5).
We now recall for the last time that the delta notation subsumes a limiting operation: the DTFT pair (4.36) should be interpreted as shorthand for the limit of the partial sums
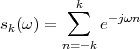
(where we have chosen ω0 = 0 for the sake of example). Figure 4.13 plots
|sk(ω)| for increasing values of k (we show only the [-π,π] interval, although
of course the functions are 2π-periodic). The family of functions sk(ω) is
exactly equivalent to the family of functions rk(t) we saw in (4.29);
they too become increasingly narrow while keeping a constant area
(which turns out to be 2π). That is why we can simply state that
sk(ω) → (ω).
(ω).
From (4.36) we can easily obtain other interesting results: by setting ω0 = 0 and by exploiting the linearity of the DTFT operator, we can derive the DTFT of a constant sequence:
 | (4.38) |
or, using Euler’s formulas, the DTFTs of sinusoidal functions:
cos(ω0n + φ) 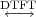   ejφ ejφ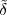 (ω - ω
0) + e-jφ (ω - ω
0) + e-jφ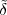 (ω + ω
0) (ω + ω
0)![]](livre361x.png) | (4.39) | |
sin(ω0n + φ) 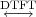 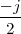  ejφ ejφ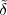 (ω - ω
0) - e-jφ (ω - ω
0) - e-jφ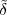 (ω + ω
0) (ω + ω
0)![]](livre367x.png) | (4.40) |
We can now show that, thanks to the delta formalism, the DTFT is the most general type of Fourier transform for discrete-time signals. Consider a length-N signal x[n] and its N DFT coefficients X[k]; consider also the sequences obtained from x[n] either by periodization or by building a finite-support sequence. The computation of the DTFTs of these sequences highlights the relationships linking the three types of discrete-time transforms that we have seen so far.
Periodic Sequences. Given a length-N signal x[n], n = 0,…,N - 1,
consider the associated N-periodic sequence 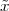 [n] = x[n mod N] and its N
DFS coefficients X[k]. If we try to write the analysis DTFT formula for
[n] = x[n mod N] and its N
DFS coefficients X[k]. If we try to write the analysis DTFT formula for 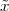 [n]
we have
[n]
we have
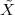 (ejω) (ejω) | = ∑
n=-∞∞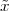 [n]e-jωn [n]e-jωn | ||
= ∑
n=-∞∞![( )
1 N∑-1 j2πnk
N- X [k]e N
k=0](livre372x.png) e-jωn e-jωn | (4.41) | ||
= 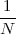 ∑
k=0N-1X[k] ∑
k=0N-1X[k]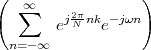 | (4.42) |
![1 N∑-1 ( 2π )
X˜(ejω) = -- X [k]˜δ ω - ---k
N k=0 N](livre375x.png) | (4.43) |
which is the relationship between the DTFT and the DFS. If we restrict ourselves to the [-π,π] interval, we can see that the DTFT of a periodic sequence is a series of regularly spaced deltas placed at the N roots of unity and whose amplitude is proportional to the DFS coefficients of the sequence. In other words, the DTFT is uniquely determined by the DFS and vice versa.
Finite-Support Sequences. Given a length-N signal x[n], n = 0,…, N - 1 and its N DFT coefficients X[k], consider the associated finite-support sequence
![{
x[n] 0 ≤ n < N
¯x [n] =
0 otherwise](livre376x.png)
from which we can easily derive the DTFT of 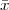 as
as
![( )
¯ jω N∑- 1 2-π
X (e ) = X [k]Λ ω - N k
k=0](livre378x.png) | (4.44) |
with
What the above expression means, is that the DTFT of the finite support
sequence  [n] is again uniquely defined by the N DFT coefficients of the
finite-length signal x[n] and it can be obtained by a type of Lagrangian
interpolation. As in the previous case, the values of DTFT at the
roots of unity are equal to the DFT coefficients; note, however, that
the transform of a finite support sequence is very different from the
DTFT of a periodized sequence. The latter, in accordance with the
definition of the Dirac delta, is defined only in the limit and for a finite
set of frequencies; the former is just a (smooth) interpolation of the
DFT.
[n] is again uniquely defined by the N DFT coefficients of the
finite-length signal x[n] and it can be obtained by a type of Lagrangian
interpolation. As in the previous case, the values of DTFT at the
roots of unity are equal to the DFT coefficients; note, however, that
the transform of a finite support sequence is very different from the
DTFT of a periodized sequence. The latter, in accordance with the
definition of the Dirac delta, is defined only in the limit and for a finite
set of frequencies; the former is just a (smooth) interpolation of the
DFT.
The DTFT possesses the following properties.
Symmetries and Structure. The DTFT of a time-reversed sequence is
![x[- n ] DT←FT→ X (e-jω)](livre381x.png) | (4.45) |
while, for the complex conjugate of a sequence we have
![* DTFT * -jω
x [n] ← → X (e )](livre382x.png) | (4.46) |
For the very important case of a real sequence x[n] R, property 4.46
implies that the DTFT is conjugate-symmetric:
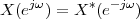 | (4.47) |
which leads to the following special symmetries for real signals:
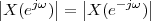 | (4.48) |
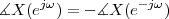 | (4.49) |
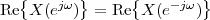 | (4.50) |
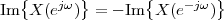 | (4.51) |
Finally, if x[n] is real and symmetric, then the DTFT is real:
![x[n] ∈ R, x [- n] = x [n] ⇐ ⇒ X (ejω) ∈ R](livre388x.png) | (4.52) |
while, for real antisymmetric signals we have that the DTFT is purely imaginary:
![x[n] ∈ R , x[- n] = - x[n] ⇐⇒ Re{X (ejω)} = 0
--](livre389x.png) | (4.53) |
Linearity and Shifts. The DTFT is a linear operator:
![αx [n]+ βy[n] D←TF→T αX (ejω )+ βY (ejω )](livre390x.png) | (4.54) |
A shift in the discrete-time domain leads to multiplication by a phase term in the frequency domain:
![x[n - n0] D←TF→T e- jωn0X (ejω)](livre391x.png) | (4.55) |
while multiplication of the signal by a complex exponential (i.e. signal modulation by a complex “carrier” at frequency ω0) leads to
![DTFT ( )
ejω0nx [n] ←→ X ej(ω-ω0)](livre392x.png) | (4.56) |
which means that the spectrum is shifted by ω0. This last result is known as the modulation theorem.
Energy Conservation. The DTFT satisfies the Plancherel-Parseval equality:
![⟨ ⟩ 1 ⟨ ⟩
x[n],y[n ] = --- X (ejω),Y (ejω)
2π](livre393x.png) | (4.57) |
or, using the respective definitions of inner product for ℓ2(Z) and
L2 [-π,π]
[-π,π] :
:
![∑∞ * 1 ∫ π * jω jω
x [n ]y[n] = 2π- X (e )Y(e )dω
n=- ∞ -π](livre396x.png) | (4.58) |
(note the explicit normalization factor 1∕2π). The above equality specializes into Parseval’s theorem as
![∑∞ | |2 1 ∫ π| jω |2
|x[n]| = 2π- |X (e )| dω
n=-∞ -π](livre397x.png) | (4.59) |
which establishes the conservation of energy property between the time and the frequency domains.
The DTFT properties we have just seen extend easily to the Fourier Transform of periodic signals. The easiest way to obtain the particularizations which follow is to apply relationship (4.43) to the results of the previous Section.
Symmetries and Structure. The DFS of a time-reversed sequence is
![˜x[- n] D←F→S ˜X [- k]](livre398x.png) | (4.60) |
while, for the complex conjugate of a sequence we have
![* DFS *
˜x [n] ← → ˜X [- k]](livre399x.png) | (4.61) |
For real periodic sequences, the following special symmetries hold (see (4.47)–(4.53)):
 [k] [k] | =  *[-k] *[-k] | (4.62) |
  [k] [k] | =   [-k] [-k] | (4.63) |
∡ [k] [k] | = -∡ [-k] [-k] | (4.64) |
Re 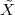 [k] [k] | = Re 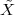 [-k] [-k] | (4.65) |
Im 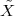 [k] [k] | = -Im 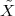 [-k] [-k] | (4.66) |
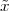 [n] is real and symmetric, then the DFS is real:
[n] is real and symmetric, then the DFS is real:
![˜x[n] = ˜x[- n] ⇐⇒ ˜X[k] ∈ R](livre423x.png) | (4.67) |
while, for real antisymmetric signals, we can state that the DFS is purely imaginary.
Linearity and Shifts. The DFS is a linear operator, since it can be expressed as a matrix-vector product. A shift in the discrete-time domain leads to multiplication by a phase term in the frequency domain:
![˜x[n - n ] D←F→S W kn0˜X[k]
0 N](livre424x.png) | (4.68) |
while multiplication of the signal by a complex exponential of frequency multiple of 2π∕N leads to of a shift in frequency:
![-nk0 DFS
WN ˜x[n] ←→ ˜X[k - k0]](livre425x.png) | (4.69) |
Energy Conservation. We have already seen the energy conservation property in the context of basis expansion. Here, we simply recall Parseval’s theorem, which states
![N∑-1 N∑-1
||˜x[n ]||2 = 1- || ˜X[k]||2
n=0 N k=0](livre426x.png) | (4.70) |
The properties of the DFT are obviously the same as those for the DFS, given the formal equivalence of the transforms. The only detail is how to interpret shifts, index reversal and symmetries for finite, length-N vectors; this is easily solved by considering the fact that the equivalence DFT-DFS translates in the time domain to a homomorphism between a length-N signal and its associated N-periodic extension to an infinite sequence. A shift, for instance, can be applied to the periodized version of the signal and the resulting shifted length N signal is given by the values of the shifted sequence from 0 to N - 1, as previously explained in Section 2.2.2.
Mathematically, this means that all shifts and time reversals of a length-N signal are operated modulo N. Consider a length-N signal:
![[x[0] x[1] ... x[N - 1]]T = x [n]](livre427x.png) | (4.71) |
Its time-reversed version is
![[ ]T
x[0] x[N - 1] x[N - 2] ... x[2] x [1] = x[- n mod N ]](livre428x.png) | (4.72) |
as we can easily see by considering the underlying periodic extension (note that x[0] remains in place!) A shift by k corresponds to a circular shift:

![]](livre430x.png) T T | |||||||||||
= x (n - k) mod N (n - k) mod N![]](livre432x.png) | (4.73) |
|
|
The concept of symmetry can be reinterpreted as follows: a symmetric signal is equal to its time reversed version; therefore, for a length-N signal to be symmetric, the first member of (4.71) must equal the first member of (4.72), that is
![⌊ ⌋
x[k] = x[N - k], k = 1,2,..., (N - 1)∕2](livre437x.png) | (4.74) |
Note that, in the above definition, the index k runs from 1 of  (N - 1)∕2
(N - 1)∕2 ;
this means that symmetry does not place any constraint on the value of x[0]
and, similarly, the value of x[N∕2] is also unconstrained for even-length
signals. Figure 4.14 shows some examples of symmetric length-N signals for
different values of N. Of course the same definition can be used for
antisymmetric signals with just a change of sign.
;
this means that symmetry does not place any constraint on the value of x[0]
and, similarly, the value of x[N∕2] is also unconstrained for even-length
signals. Figure 4.14 shows some examples of symmetric length-N signals for
different values of N. Of course the same definition can be used for
antisymmetric signals with just a change of sign.
Symmetries and Structure. The symmetries and structure derived for the DFS can be rewritten specifically for the DFT as
| x[-n mod N] |  X[-k mod N] X[-k mod N] | (4.75) |
| x*[n] |  X*[-k mod N] X*[-k mod N] | (4.76) |
The following symmetries hold only for real signals:
| X[k] | = X*[-k mod N] | (4.77) |
 X[k] X[k] | =  X[-k mod N] X[-k mod N] | (4.78) |
| ∡X[k] | = -∡X[-k mod N] | (4.79) |
Re X[k] X[k] | = Re X[-k mod N] X[-k mod N] | (4.80) |
Im X[k] X[k] | = -Im X[-k mod N] X[-k mod N] | (4.81) |
![x[k] = x [N - k], k = 1,2,...,⌊(N - 1)∕2⌋ ⇐ ⇒ X [k] ∈ R](livre454x.png) | (4.82) |
while, for real antisymmetric signals we have that the DFT is purely imaginary.
Linearity and Shifts. The DFT is obviously a linear operator. A circular shift in the discrete-time domain leads to multiplication by a phase term in the frequency domain:
![[ ] DFT kn0
x (n - n0) mod N ← → W N X [k ]](livre455x.png) | (4.83) |
while the finite-length equivalent of the modulation theorem states
![- nk0 DFT [ ]
W N x [n] ← → X (k - k0) mod N](livre456x.png) | (4.84) |
Energy Conservation. Parseval’s theorem for the DFT is (obviously) identical to (4.70):
![N∑-1| |2 1 N∑-1| |2
|x[n ]| = -- |X[k]|
n=0 N k=0](livre458x.png) | (4.85) |
In the previous Sections, we have developed three frequency representations for the three main types of discrete-time signals; the derivation was eminently theoretical and concentrated mostly upon the mathematical properties of the transforms seen as a change of basis in Hilbert space. In the following Sections we will see how to put the Fourier machinery to practical use.
We have seen two fundamental ways to look at a signal: its time-domain representation, in which we consider the values of the signal as a function of discrete time, and its frequency-domain representation, in which we consider its energy and phase content as a function of digital frequency. The information contained in each of the two representations is exactly the same, as guaranteed by the invertibility of the Fourier transform; yet, from an analytical point of view, we can choose to concentrate on one domain or the other according to what we are specifically seeking. Consider for instance a piece of music; such a signal contains two coexisting perceptual features, meter and key. Meter can be determined by looking at the duration patterns of the played notes: its “natural” domain is therefore the time domain. The key, on the other hand, can be determined by looking at the pitch patterns of the played notes: since pitch is related to the frequency content of the sound, the natural domain of this feature is the frequency domain.
We can recall that the DTFT is mostly a theoretical analysis tool; the DTFTs which can be computed exactly (i.e. those in which the sum in (4.13) can be solved in closed form) represent only a small set of sequences; yet, these sequences are highly representative and they will be used over and over to illustrate a prototypical behavior. The DFT,(8) on the other hand, is fundamentally a numerical tool in that it defines a finite set of operations which can be computed in a finite amount of time; in fact, a very efficient algorithmic implementation of the DFT exists under the name of Fast Fourier Transform (FFT) which only requires a number of operations on the order of N(log N) for an N-point data vector. The DFT, as we know, only applies to finite-length signals but this is actually acceptable since, in practice, all measured signals have finite support; in principle, therefore, the DFT suffices for the spectral characterization of real-world sequences. Since the transform of a finite-length signal and its DTFT are related by (4.43) or by (4.44) according to the underlying model for the infinite-length extension, we can always use the DTFT to illustrate the fundamental concepts of spectral analysis for the general case and then particularize the results for finite-length sequences.
The first question that we ask ourselves is how to represent spectral data. Since the transform values are complex numbers, it is customary to separately plot their magnitude and their phase; more often than not, we will concentrate on the magnitude only, which is related to the energy distribution of the signal in the frequency domain.(9) For infinite sequences whose DTFT can be computed exactly, the graphical representation of the transform is akin to a standard function graph – again, the interest here is mostly theoretical. Consider now a finite-length signal of length N; its DFT can be computed numerically, and it yields a length-N vector of complex spectral values. These values can be displayed as such (and we obtain a plain DFT plot) or they can be used to obtain the DTFT of the periodic or finite-support extension of the original signal.
Consider for example the length-16 triangular signal x[n] in Figure 4.15;
note in passing that the signal is symmetric according to our definition in
(4.74) so that its DFT is real. The DFT coefficients  X[k]
X[k] are plotted in
Figure 4.16; according to the fact that x[n] is a real sequence, the set of
DFT coefficients is symmetric (again according to (4.74)). The k-th DFT
coefficient corresponds to the frequency (2π∕N)k and, therefore, the
plot’s abscissa extends implicitly from 0 to 2π; this is a little different
than what we are used to in the case of the DTFT, where we usually
consider the [-π,π] interval, but it is customary. Furthermore, the
difference is easily eliminated if we consider the sequence of X[k] as being
N-periodic (which it is, as we showed in Section 4.3) and plot the values
from -k∕2 to k∕2 for k even, or from -(k - 1)∕2 to (k - 1)∕2 for k
odd.
are plotted in
Figure 4.16; according to the fact that x[n] is a real sequence, the set of
DFT coefficients is symmetric (again according to (4.74)). The k-th DFT
coefficient corresponds to the frequency (2π∕N)k and, therefore, the
plot’s abscissa extends implicitly from 0 to 2π; this is a little different
than what we are used to in the case of the DTFT, where we usually
consider the [-π,π] interval, but it is customary. Furthermore, the
difference is easily eliminated if we consider the sequence of X[k] as being
N-periodic (which it is, as we showed in Section 4.3) and plot the values
from -k∕2 to k∕2 for k even, or from -(k - 1)∕2 to (k - 1)∕2 for k
odd.
|
|
This can be made explicit by considering the N-periodic extension of x[n]
and by using the DFS-DTFT relationship (4.23); the standard way to plot
this is as in Figure 4.17. Here the N pulse trains 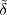 (ω - (2π∕N)k)
are represented as lines (or arrows) scaled by the magnitude of the
corresponding DFT coefficients. By plotting the representative [-π,π]
interval, we can appreciate, in full, the symmetry of the transform’s
magnitude.
(ω - (2π∕N)k)
are represented as lines (or arrows) scaled by the magnitude of the
corresponding DFT coefficients. By plotting the representative [-π,π]
interval, we can appreciate, in full, the symmetry of the transform’s
magnitude.
By considering the finite-support extension of x[n] instead, and by plotting the magnitude of its DTFT, we obtain Figure 4.18. The points in the plot can be computed directly from the summation defining the DTFT (which, for finite-support signals only contains a finite number of terms) and by evaluating the sum over a sufficiently fine grid of values for ω in the [-π,π] interval; alternatively, the whole set of points can be obtained in one shot from an FFT with a sufficient amount of zero-padding (this method will be precised later). Again, the DTFT of a finite-support extension is just a smooth interpolation of the original DFT points and no new information is added.
|
|
|
|
The Fast Fourier Transform, or FFT, is not another type of transform but simply the name of an efficient algorithm to compute the DFT. The algorithm, in its different flavors, is so ubiquitous and so important that the acronym FFT is often used liberally to indicate the DFT (or the DFS, which would be more appropriate since the underlying model is that of a periodic signal).
We have already seen in (4.6) that the DFT can be expressed in terms of a matrix vector multiplication:
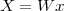
as such, the computation of the DFT requires a number of operations on the order of N2. The FFT algorithm exploits the highly structured nature of W to reduce the number of operations to N log(N). In matrix form this is equivalent to decomposing W into the product of a series of matrices with mostly zero or unity elements. The algorithmic details of the FFT can be found in the bibliography; we can mention, however, that the FFT algorithm is particularly efficient for data lengths which are a power of 2 and that, in general, the more prime factors the data length can be decomposed into, the more efficient the FFT implementation.
FFT algorithms are tailored to the specific length of the input signal. When the input signal’s length is a large prime number or when only a subset of FFT algorithms is available (when, for instance, all we have is the radix-2 algorithm, which processes input vectors with lengths of a power of 2) it is customary to extend the length of the signal to match the algorithmic requirements. This is usually achieved by zero padding, i.e. the length-N data vector is extended to a chosen length M by appending (M - N) zeros to it. Now, the maximum resolution of an N-point DFT, i.e. the separation between frequency components, is 2π∕N. By extending the signal to a longer length M, we are indeed reducing the separation between frequency components. One may think that this artificial increase in resolution allows the DFT to show finer details of the input signal’s spectrum. It is not so.
The M-point DFT X(M) of an N-point data vector x, obtained via zero-padding, can be obtained directly from the “canonical” N-point DFT of the vector X(N) via a simple matrix multiplication:
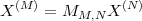 | (4.86) |
where the M × N matrix MM,N is given by
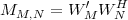
where WN is the standard DFT matrix and WM′ is the M × N matrix obtained by keeping just the first N columns of the standard DFT matrix WM. The fundamental meaning of (4.86) is that, by zero padding, we are adding no information to the spectral representation of a finite-length signal. Details of the spectrum which were not apparent in an N-point DFT are still not apparent in a zero-padded version of the same. It can be shown that (4.86) is a form of Lagrangian interpolation of the original DFT samples; therefore the zero-padded DFT is more attractive in a “cosmetic” fashion since the new points, when plotted, show a smooth curve between the original DFT points (and this is how plots such as the one in Figure 4.18 are obtained).
The spectrum is a complete, alternative representation of a signal; by analyzing the spectrum, one can obtain, at a glance, the fundamental information, reguired to characterize and classify a signal in the frequency domain.
Magnitude The magnitude of a signal’s spectrum, obtained by the Fourier transform, represents the energy distribution in frequency for the signal. It is customary to broadly classify discrete-time signals into three classes:
|
For real-valued signals, the magnitude spectrum is a symmetric function and the above classifications take this symmetry into account. Remember also, that all spectra of discrete-time signals are 2π-periodic functions so that the above definitions are to be interpreted in a 2π-periodic fashion. For once, this is made explicit in Figures 4.19 to 4.21 where the plotting range, instead of the customary [-π,π] interval, is extended from -2π to 2π.
Phase As we have stated before, the Fourier representation allows us to think of any signal as the sum of the outputs of a (potentially infinite) number of sinusoidal generators. While the magnitude of the spectrum defines the inherent power produced by each of the generators, its phase defines the relative alignment of the generated sinusoids. This alignment determines the shape of the signal in the discrete-time domain. To illustrate this with an example, consider the following 64-periodic signal:(10)
![3 ( )
˜x[n] = ∑ --1---sin 2π-(2i+ 1)n+ φ
2i+ 1 64 i
i=0](livre472x.png) | (4.87) |
The magnitude of its DFS 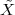 [k] is independent of the values of φi = 0,
i = 0,1,2,3, and it is plotted in Figure 4.22. If the phase terms are uniformly
zero, i.e. φi = 0, i = 0,1,2,3,
[k] is independent of the values of φi = 0,
i = 0,1,2,3, and it is plotted in Figure 4.22. If the phase terms are uniformly
zero, i.e. φi = 0, i = 0,1,2,3, 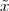 [n] is the discrete-time periodic signal plotted
in Figure 4.23; the alignment of the constituent sinusoids is such
that the “square wave” exhibits a rather sharp transition between
half-periods and a rather flat behavior over the half-period intervals. In
addition, it should be noted with a zero phase term, the periodic signal is
symmetric and that therefore the DFS coefficients are real. Now consider
modifying the individual phases so that φi = 2πi∕3; in other words, we
introduce a linear phase term in the constituent sinusoids. While the DFS
magnitude remains exactly the same, the resulting time-domain signal is
the one depicted in Figure 4.24; lack of alignment between sinusoids
creates a “smearing” of the signal which no longer resembles a square
wave.
[n] is the discrete-time periodic signal plotted
in Figure 4.23; the alignment of the constituent sinusoids is such
that the “square wave” exhibits a rather sharp transition between
half-periods and a rather flat behavior over the half-period intervals. In
addition, it should be noted with a zero phase term, the periodic signal is
symmetric and that therefore the DFS coefficients are real. Now consider
modifying the individual phases so that φi = 2πi∕3; in other words, we
introduce a linear phase term in the constituent sinusoids. While the DFS
magnitude remains exactly the same, the resulting time-domain signal is
the one depicted in Figure 4.24; lack of alignment between sinusoids
creates a “smearing” of the signal which no longer resembles a square
wave.
|
|
|
|
|
|
Recall our example at the beginning of this Chapter, when we considered the time and frequency information contained in a piece of music. We stated that the melodic information is related to the frequency content of the signal; obviously this is only partially true, since the melody is determined not only by the pitch values but also by their duration and order. Now, if we take a global Fourier Transform of the entire musical piece we have a comprehensive representation of the frequency content of the piece: in the resulting spectrum there is information about the frequency of each played note.(11) The time information, however, that is the information pertaining to the order in which the notes are played, is completely hidden by the spectral representation. This makes us wonder whether there exists a time-frequency representation of a signal, in which both time and frequency information are readily apparent.
The simplest time-frequency transformation is called the spectrogram. The recipe involves splitting the signal into small consecutive (and possibly overlapping) length-N pieces and computing the DFT of each. What we obtain is the following function of discrete-time and of a dicrete frequency index:
![N- 1
S[k,m] = ∑ x[mM + i]W ik
N
i=0](livre478x.png) | (4.88) |
where M, 1 ≤ M ≤ N controls the overlap between segments. In matrix notation we have
![⌊ ⌋
x[0] x[M ] x[2M ] ⋅⋅⋅
| |
|| x[1] x[M + 1] x[2M + 1] ⋅⋅⋅||
S = WN || .. .. .. ||
⌈ . . . ⋅⋅⋅⌉
x[N - 1] x[M + N - 1] x[L] ⋅⋅⋅](livre479x.png) | (4.89) |
The resulting spectrogram is therefore an N ×⌊L∕M⌋ matrix, where L is the total length of the signal x[n]. It is usually represented graphically as a plot in which the x-axis is the discrete-time index m, the y-axis is the discrete frequency index k and a color is the magnitude of S[k,m], with darker colors for larger values.
As an example of the insight we can gain from the spectrogram, consider analyzing the well-known Bolero by Ravel. Figure 4.25 shows the spectrogram of the initial 37 seconds of the piece. In the first 13 seconds the only instrument playing is the snare drum, and the vertical line in the spectrogram represents, at the same time, the wide frequency content of a percussive instrument and its rhythmic pattern: if we look at the spacing between lines, we can identify the “trademark” drum pattern of Ravel’s Bolero. After 13 seconds, the flute starts playing the theme; this is identifiable in the dark horizontal stripes which denote a high energy content around the frequencies which correspond to the pitches of the melody; with further analysis we could even try to identify the exact notes. The clarity of this plot is due to the simple nature of the signal; if we now plot the spectrogram of the last 20 seconds of the piece, we obtain Figure 4.26. Here the orchestra is playing full blast, as indicated by the high energy activity across the whole spectrum; we can only detect the onset of the rhythmic shouts that precede the final chord.
|
|
Each of the columns of S represents the “local” spectrum of the signal for a time interval of length N. We can therefore say that the time resolution of the spectrogram is N samples since the value of the signal at time n0 influences the DFT of the N-point window around n0. Seen from another point of view, the time information is “smeared” over an N-point interval. At the same time, the frequency resolution of the spectrogram is 2π∕N (and we cannot increase it by zero-padding, as we have just shown). The conflict is therefore apparent: if we want to increase the frequency resolution we need to take longer windows but in so doing, we lose the time localization of the spectrogram; likewise, if we want to achieve a fine resolution in time, the corresponding spectral information for each “time slice” will be very coarse. It is rather easy to show that the amount of overlap does not change the situation. In practice, we need to choose an optimal tradeoff taking the characteristics of the signal into consideration.
The above problem, described for the case of the spectrogram, is actually a particular instance of a general uncertainty principle for time-frequency analysis. The principle states that, independently of the analysis tools that we put in place, we can never hope to achieve arbitrarily good resolution in both time and frequency since there exists a lower bound greater than zero for the product of the localization measure in time and frequency.
The conceptual representation of discrete-time signals relies on the notion of a dimensionless “time”, indicated by the integer index n. The absence of a physical dimension for time has the happy consequence that all discrete-time signal processing tools become indifferent to the underlying physical nature of the actual signals: stock exchange values or sampled orchestral music are just sequences of numbers. Similarly, we have just derived a frequency representation for signals which is based on the notion of a dimensionless frequency; because of the periodicity of the Fourier basis, all we know is that π is the highest digital frequency that we can represent in this model. Again, the power of generality is (or will soon be) apparent: a digital filter which is designed to remove the upper half of a signal’s spectrum can be used with any type of input sequence, with the same results. This is in stark contrast with the practice of analog signal processing in which a half-band filter (made of capacitors, resistors and other electronic components) must be redesigned for any new class of input signals.
This dimensionless abstraction, however, is not without its drawbacks from the point of view of hands-on intuition; after all, we are all very familiar with signals in the real world for which time is expressed in seconds and frequency is expressed in hertz. We say, for instance, that speech has a bandwidth up to 4 KHz, that the human ear is sensitive to frequencies up to 20 KHz, that a cell phone transmits in the GHz band, and so on. What does “π” mean in these cases? The precise, formal link between real-world signal and discrete-time signal processing is given by the Sampling Theorem, which we will study later. The fundamental idea, however, is that we can remove the abstract nature of a discrete-time signal (and, correspondingly, of a dimensionless frequency) by associating a time duration to the interval between successive discrete-time indices in the sequence.
Let us say that the “real-world” time between indices n and n + 1 in a discrete-time sequence is Ts seconds (where Ts is generally very small); this can correspond to sampling a signal every Ts seconds or to generating a synthetic sequence with a DSP chip whose clock cycle is Ts seconds. Now, recall that the phase increment between successive samples of a generic complex exponential ejω0n is ω0 radians. The oscillation, therefore, completes a full cycle in n0 = (2π∕ω0) samples. If Ts is the real-world time between samples, the full cycle is completed in n0Ts seconds and so its “real-world” frequency is f0 = 1∕(n0Ts) hertz. The relationship between the digital frequency ω0 and the “real” frequency f0 in Hertz as determined by the “clock” period Ts is therefore
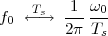 | (4.90) |
In particular, the highest real frequency which can be represented in the discrete-time system (which corresponds to ω = π) is
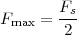
where we have used Fs = (1∕Ts); Fs is just the operating frequency of the discrete time system (also called the sampling frequency or clock frequency). With this notation, the digital frequency ω0 corresponding to a real frequency f0 is
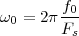
The compact disk system, for instance, operates at a frequency Fs = 44.1 KHz; the maximum representable frequency for the system is 22.05 KHz (which constitutes the highest-pitched sound which can be encoded on, and reproduced by, a CD).
Example 4.1: The structure of DFT formulas
The DFT and inverse DFT (IDFT) formulas have a high degree of symmetry. Indeed, we can use the DFT algorithm to compute the IDFT with just a little manipulation: this can be useful if we have a “black box” FFT routine and we want to compute an inverse transform.
In the space of length-N signals, indicate the DFT of a signal x as
![[ ]T
X = X [0] X [1] ... X [N - 1] = DFT {x}](livre485x.png)
so that we can also write
![DFT {x}[n] = X [n]](livre486x.png)
Now consider the time-reversed signal
![[ ]T
Xr = X [N - 1] X [N - 2] ... X[1] X[0]](livre487x.png)
we can show that
![x[n] = 1-W n ⋅DFT {X }[n]
N N r](livre488x.png)
so that the inverse DFT can be obtained as the DFT of a time-reversed and scaled version of the original DFT. Indeed, with the change of variable m = (N - 1) - k, we have
| DFT{Xr}[n] | = ∑
k=0N-1X (N - 1) - k (N - 1) - k![]](livre490x.png) e-j e-j kn kn | ||
= ∑
m=0N-1X[m]e-j (N-1-m)n (N-1-m)n | |||
= ∑
m=0N-1X[m]ej mn ej mn ej n e-j n e-j Nn Nn | |||
= ej n ∑
m=0N-1X[m]ej n ∑
m=0N-1X[m]ej mn = ej mn = ej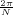 n ⋅ N ⋅ x[n] n ⋅ N ⋅ x[n] |
Example 4.2: The DTFT of the step function
In the delta-function formalism, the Fourier transform of the unit signal
x[n] = 1 is the pulse train  (ω). Intuitively, the reasoning goes as follows:
the unit signal has the same value over its entire infinite, two-sided
support; nothing ever changes, there is not even the minutest glimpse of
movement in the signal, ergo its spectrum can only have a nonzero
value at the zero frequency. Recall that a frequency of zero is the
frequency of dead quiet; the spectral value at ω = 0 is also known
as the DC component (for Direct Current), as opposed to a livelier
AC (Alternating Current). At the same time, the unit signal has a
very large energy, an infinite energy to be precise; imagine it as the
voltage at the poles of a battery connected to a light bulb: to keep
the light on for all eternity (i.e. over Z) the energy must indeed be
infinite. Our delta function captures this duality very effectively, if not
rigorously.
(ω). Intuitively, the reasoning goes as follows:
the unit signal has the same value over its entire infinite, two-sided
support; nothing ever changes, there is not even the minutest glimpse of
movement in the signal, ergo its spectrum can only have a nonzero
value at the zero frequency. Recall that a frequency of zero is the
frequency of dead quiet; the spectral value at ω = 0 is also known
as the DC component (for Direct Current), as opposed to a livelier
AC (Alternating Current). At the same time, the unit signal has a
very large energy, an infinite energy to be precise; imagine it as the
voltage at the poles of a battery connected to a light bulb: to keep
the light on for all eternity (i.e. over Z) the energy must indeed be
infinite. Our delta function captures this duality very effectively, if not
rigorously.
Now consider the unit step u[n]; this is a somewhat stranger entity since it still possesses infinite energy and it still is a very quiet signal – except in n = 0. The transition in the origin is akin to flipping a switch in the battery/light bulb circuit above with the switch remaining on for the rest of (positive) eternity. As for the Fourier transform, intuitively we will still have a delta in zero (because of the infinite energy) but also some nonzero values over the entire frequency range because of the “movement” in n = 0. We know that for |a| < 1 it is
![n DTFT ----1-----
a u[n] ← → 1- a e-jω](livre500x.png)
so that it is tempting to let a → 1 and just say
![u [n] DTF←T→ ?? ----1---
1 - e-jω](livre501x.png)
This is not quite correct; even intuitively, the infinite energy delta is missing. To see what’s wrong, let us try to find the inverse Fourier transform of the above expression; by using the substitution exp(jω) = z and contour integration on the unit circle we have
![1 ∫ π ejωn 1 ∮ zn dz
ˆu[n] = 2π- 1--e--jω-dω = 2π- 1--z-1-jz-
-π C](livre502x.png)
Since there is a pole on the contour, we need have to use Cauchy’s principal value theorem for the indented integration contour shown in Figure 4.27. For n ≥ 0 there are no poles other than in z = 1 and we can use the “half-residue” theorem to obtain
![∮ n [ ]
--z-- dz = jπ Residue at z = 1 = jπ
C′z - 1](livre503x.png)
so that
![1
ˆu[n ] =-- for n ≥ 0
2](livre504x.png)
For n < 0 there is a (multiple) pole in the origin; with the change of variable v = z-1 we have
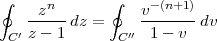
where C′′ is the same contour as C′ but oriented clockwise. Because of this inversion it is
![ˆu[n] = - 1 for n < 0
2](livre506x.png)
In conclusion
![{
-1{ 1 } +1 ∕2 for n ≥ 0
DTFT 1---e-jω = ˆu[n] =
- 1∕2 for n < 0](livre507x.png)
But this is almost good! Indeed,
![u[n] = ˆu[n]+ 1-
2](livre508x.png)
so that finally the DTFT of the unit step is
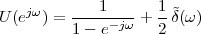 | (4.91) |
and its magnitude is sketched in Figure 4.28.
A nice engineering book on Fourier theory is The Fourier Transform and Its Applications, by R. Bracewell (McGraw- Hill, 1999). A more mathematically oriented textbook is Fourier Analysis, by T. W. Korner (Cambridge University Press, 1989), as is P. Bremaud’s book, Mathematical Principles of Signal Processing (Springer, 2002).
Exercise 4.1: DFT of elementary functions. Derive the formula for
the DFT of the length-N signal x[n] = cos (2π∕N)Ln + φ
(2π∕N)Ln + φ .
.
Exercise 4.2: Real DFT. Compute the DFT of the length-4 signal x[n] = {a,b,c,d}. For which values of a,b,c,d is the DFT real?
Exercise 4.3: Limits. What is the value of the limit
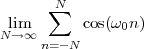
(in a signal processing sense)?
Exercise 4.4: Estimating the DFT graphically. Consider a length-64 signal x[n] which is the sum of the three sinusoidal signals plotted in the following Figure (the signals are plotted as continuous lines just for clarity). Compute the DFT coefficients X[k], k = 0,1,…,63.
|
|
Exercise 4.5: The structure of DFT formulas. Consider a length-N signal x[n], N = 0,…,N - 1; what is the length-N signal y[n] obtained as
![{ { } }
y[n] = DFT DFT x[n]](livre516x.png)
(i.e. by applying the DFT algorithm twice in a row)?
Exercise 4.6: Two DFTs for the price of one. When you compute the DFT of an length-N real signal, your data contains N real values while the DFT vector contains N complex values: there is clearly a redundancy of a factor of two in the DFT vector, which is apparent when you consider its Hermitian symmetry (i.e. X[k] = X*[N - k]). You can exploit this fact to compute the DFT of two real length-N signals for the price of one. This is useful if you have a pre-packaged FFT algorithm which you want to apply to real data.
Assume x[n] and y[n] are two length-N real signals. Build a complex signal c[n] = x[n] + jy[n] and compute its DFT C[k], k = 0,1,…,N - 1. Show that
![1 ( )
X [k] = -- C[k]+ C *[N - k]
2 k = 0,1,...,N - 1
Y[k] = 1-(C [k]- C*[N - k ])
2j](livre517x.png)
where X[k] and Y [k] are the DFTs of x[n] and y[n], respectively.
Exercise 4.7: The Plancherel-Parseval equality. Let x[n] and y[n] be two complex valued sequences and X(exp(jw)) and Y (exp(jw)), their corresponding DTFTs.
![⟨ ⟩ ⟨ ⟩
x[n],y[n ] = -1- X (ejw),Y(ejw)
2π](livre518x.png)
where we use the inner products for ℓ2(Z) and L2 [-π,π]
[-π,π] ,
respectively.
,
respectively.
Exercise 4.8: Numerical computation of the DFT. Consider the signal x(n) = cos(2πf0n). Compute and draw the DFT of the signal in N = 128 points, for
You can use any numerical package to do this. Explain the differences that we can see in these two spectra.
Exercise 4.9: DTFT vs. DFT. Consider the following infinite non-periodic discrete time signal:
x[n] = 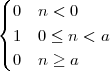 |
We want to visualize the magnitude of X(exp(jω)) using a numerical package (for instance, Matlab). Most numeric packages cannot handle continuous sequences such as X(exp(jω)); therefore we need to consider only a finite number of points for the spectrum.
The DTFT is mostly a theoretical analysis tool, and in many cases, we will compute the DFT. Moreover, for obvious reasons, numeric computation programs as, Matlab, only compute the DFT. Recall that in Matlab we use the Fast Fourier Transform (FFT), an efficient algorithm to compute the DFT.
| © Presses polytechniques et universitaires romandes, 2008 All rights reserved |
The previous Chapters gave us a thorough overview on both the nature of discrete-time signals and on the tools used in analyzing their properties. In the next few Chapters, we will study the fundamental building block of any digital signal processing system, that is, the linear filter. In the discrete-time world, filters are nothing but procedures which store and manipulate mathematically the numerical samples appearing at their input and their output; in other words, any discrete-time filter can be described procedurally in the form of an algorithm. In the special case of linear and time-invariant filters, such an algorithm can be concisely described mathematically by a constant-coefficient difference equation.
In its most general form, a discrete-time system can be described as a black box accepting a number of discrete-time sequences as inputs and producing another number of discrete-time sequences at its output.
In this book we are interested in studying the class of linear time-invariant
(LTI) discrete-time systems with a single input and a single output; a system
of this type is referred to as a filter. A linear time-invariant system can
thus be viewed as an operator which transforms an input sequence into an
output sequence:
![{ }
y[n] = H x[n]](livre524x.png)
Linearity is expressed by the equivalence
![{ } { } { }
H αx1[n]+ βx2 [n ] = αH x1[n] + βH x2[n]](livre526x.png) | (5.1) |
for any two sequences x1[n] and x2[n] and any two scalars α,β C.
Time-invariance is expressed by
![y[n] = H {x[n]} ⇐ ⇒ H {x[n - n ]} = y[n - n ]
0 0](livre527x.png) | (5.2) |
Linearity and time-invariance are very reasonable and “natural” requirements for a signal processing system. Imagine a recording system: linearity implies that a signal obtained by recording a violin and a piano playing together is the same as the sum of the signals obtained recording the violin and the piano separately (but in the same recording room). Multi-track recordings in music production are an application of this concept. Time invariance basically means that the system’s behavior is independent of the time the system is turned on. Again, to use a musical example, this means that a given digital recording played back by a digital player will sound the same, regardless of when it is played.
Yet, simple as these properties, linearity and time-invariance taken
together have an incredibly powerful consequence on a system’s behavior.
Indeed, a linear time-invariant system turns out to be completely
characterized by its response to the input x[n] = δ[n]. The sequence
h[n] = {δ[n]} is called the impulse response of the system and h[n] is all we
need to know to determine the system’s output for any other input sequence.
To see this, we know that for any sequence we can always write the
canonical orthonormal expansion (i.e. the reproducing formula in
(2.18))
![∑∞
x[n ] = x[k]δ[n- k]
k=-∞](livre528x.png)
and therefore, if we let  δ[n]
δ[n] = h[n], we can apply (5.1) and (5.2) to
obtain
= h[n], we can apply (5.1) and (5.2) to
obtain
![{ } ∑∞
y[n] = H x[n ] = x[k ]h[n - k]
k=- ∞](livre531x.png) | (5.3) |
The summation in (5.3) is called the convolution of sequences x[n] and h[n] and is denoted by the operator “*” so that (5.3) can be shorthanded to
![y[n] = x [n] *h[n]](livre532x.png)
This is the general expression for a filtering operation in the discrete-time domain. To indicate a specific value of the convolution at a given time index n0, we may use the notation y[n0] = (x * h)[n0]
Clearly, for the convolution of two sequences to exist, the sum in (5.3) must be finite and this is always the case if both sequences are absolutely summable. As in the case of the DTFT, absolute summability is just a sufficient condition and the sum (5.3) can be well defined in certain other cases as well.
Basic Properties. The convolution operator is easily shown to be linear and time-invariant (which is rather intuitive seeing as it describes the behavior of an LTI system):
![( )
x[n ]* α ⋅y[n]+ β ⋅w[n] = α ⋅x[n]* y[n]+ β ⋅x[n ]*w [n ]](livre533x.png) | (5.4) |
![w [n ] = x[n]* y[n ] ⇐ ⇒ x[n]* y[n- k] = w[n - k]](livre534x.png) | (5.5) |
The convolution is also commutative:
![x [n]* y[n] = y[n]* x[n]](livre535x.png) | (5.6) |
which is easily shown via a change of variable in (5.3). Finally, in the case of square summable sequences, it can be shown that the convolution is associative:
![( ) ( )
x [n]* h[n] * w[n] = x[n]* h[n]*w [n]](livre536x.png) | (5.7) |
This last property describes the effect of connecting two filters and  in
cascade and it states that the resulting effect is that of a single filter
whose impulse response is the convolution of the two original impulse
responses. As a corollary, because of the commutative property, the
order of the two filters in the cascade is completely irrelevant. More
generally, a sequence of filtering operations can be performed in any
order.
in
cascade and it states that the resulting effect is that of a single filter
whose impulse response is the convolution of the two original impulse
responses. As a corollary, because of the commutative property, the
order of the two filters in the cascade is completely irrelevant. More
generally, a sequence of filtering operations can be performed in any
order.
Please note that associativity does not necessarily hold for sequences which are not square-summable. A classic counterexample is the following: consider the three sequences
| x[n] | = u[n] the unit step | ||
| y[n] | = δ[n] - δ[n - 1] the first-difference operator | ||
| w[n] | = 1 a constant signal |
ℓ2(Z). It is easy to verify that
| x[n] * (y[n] * w[n]) | = 0 | ||
| (x[n] * y[n]) * w[n] | = 1 |
Convolution and Inner Product. It is immediately obvious that, for two sequences x[n] and h[n], we can write:
![⟨ ⟩
x[n ]*h[n] = h*[n - k],x[k ]](livre537x.png)
that is, the value at index n of the convolution of two sequences is the inner product (in ℓ2(Z)) of the first sequence – conjugated,(1) time-reversed and re-centered at n – with the input sequence. The above expression describes the output of a filtering operation as a series of “localized” inner products; filtering, therefore, measures the time-localized similarity (in the inner product sense, i.e. in the sense of the correlation) between the input sequence and a prototype sequence (the time-reversed impulse response).
In general, the convolution operator for a signal is defined with respect to the inner product of its underlying Hilbert space. For the space of N-periodic sequences, for instance, the convolution is defined as
 [n] *ỹ[n] [n] *ỹ[n] | = ∑
k=0N-1 [k]ỹ[n - k] [k]ỹ[n - k] | (5.8) |
= ∑
k=0N-1 [n - k]ỹ[k] [n - k]ỹ[k] | (5.9) |
| X(ejω) * Y (ejω) | = 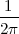  X*(ej(ω-σ)),Y (ejσ) X*(ej(ω-σ)),Y (ejσ) | (5.10) |
= 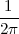 ∫
-ππX(ej(ω-σ))Y (ejσ)dσ ∫
-ππX(ej(ω-σ))Y (ejσ)dσ | (5.11) | |
=  ∫
-ππX(ejσ)Y (ej(ω-σ))dσ ∫
-ππX(ejσ)Y (ej(ω-σ))dσ | (5.12) |
As we said, an LTI system is completely described by its impulse response,
i.e. by h[n] =  x[n]}.
x[n]}.
FIR vs IIR. Since the impulse response is defined as the transformation of the discrete-time delta and since the delta is an infinite-length signal, the impulse response is always an infinite-length signal, i.e. a sequence. The nonzero values of the impulse response are usually called taps. Two distinct cases are possibles:
Note that in the case of FIR filters, the convolution operator entails only a finite number of sums and products; if h[n] = 0 for n < N and n ≥ M, we can invoke commutativity and rewrite (5.3) as
![M∑- 1
y[n] = h[k ]x[n - k]
k=N](livre547x.png)
Thus, convolution sums involving a finite-support impulse response are always well defined.
Causality. A system is called causal if its output does not depend on future values of the input. In practice, a causal system is the only type of “real-time” system we can actually implement, since knowledge of the future is normally not an option in real life. Yet, noncausal filters maintain a practical interest since in some application (usually called “batch processing”) we may have access to the entirety of a discrete-time signal, which has been previously stored on some form of memory support.(2) A filter whose output depends exclusively on future values of the input is called anticausal.
For an LTI system, causality implies that the associated impulse response
is zero for negative indices; this is the only way to remove all “future” terms
in the convolution sum (5.3). Similarly, for anticausal systems, the impulse
response must be zero for all positive indices. Clearly, between the strict
causal and anticausal extremes, we can have intermediate cases: consider for
example a filter 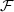 whose impulse response is zero for n < -M with
M N+. This filter is technically noncausal, but only in a “finite”
way. If we consider the pure delay filter , whose impulse response
is
whose impulse response is zero for n < -M with
M N+. This filter is technically noncausal, but only in a “finite”
way. If we consider the pure delay filter , whose impulse response
is
![d[n] = δ[n - 1]](livre548x.png)
we can easily see that can be made strictly causal by cascading M
delays in front of it. Clearly, an FIR filter is always causal up to a
delay.
Stability. A system is called bounded-input bounded-output stable (BIBO stable) if its output is bounded for all bounded input sequences. Again, stability is a very natural requirement for a filter, since it states that the output will not “blow up” when the input is reasonable. Linearity and time-invariance do not guarantee stability (as anyone who has ever used a hands-free phone has certainly experienced).
A bounded sequence x[n] is one for which it is possible to find a
finite value L R+ so that |x[n]| < L for all n. A necessary and
sufficient condition for an LTI system to be BIBO stable is that
its impulse response h[n] be absolutely summable. The sufficiency
of the condition is proved as follows: if x[n] < L for all n, then we
have
![|| ∞ || ∞ ∞
||y[n]|| = ||h[n]*x [n]|| = || ∑ h[k]x[n - k]|| ≤ ∑ ||h[k]x [n- k]|| ≤ L ∑ ||h[k]||
| |
k=- ∞ k=- ∞ k=-∞](livre549x.png) |
and the last term is finite if h[n] is absolutely summable. Conversely, assume that h[n] is not absolutely summable and consider the signal
![( )
x [n] = sign h[- n]](livre550x.png)
![∞∑ ∑∞ | |
y[0] = (h * x)[0] = h[k]x[- k] = |h[k]| = ∞
k=-∞ k= -∞](livre551x.png)
Note that in the case of FIR filters, the convolution sum only involves a finite number of terms. As a consequence, FIR filters are always stable.
So far, we have described a filter from a very abstract point of view, and we have shown that a filtering operation corresponds to a convolution with a defining sequence called the impulse response. We now take a diametrically opposite standpoint: we introduce a very practical problem and arrive at a solution which defines an LTI system. Once we recognize that the solution is indeed a discrete-time filter, we will be able to make use of the theoretical results of the previous Sections in order, to analyze its properties.
Consider a sequence like the one in Figure 5.2; we are clearly in the presence of a “smooth” signal corrupted by noise, which appears as little wiggles in the plot. Our goal is the removal of the noise, i.e. to smooth out the signal, in order to improve its readability.
An intuitive and basic approach to remove noise from data is to replace each point of the sequence x[n] by a local average, which can be obtained by taking the average of the sample at n and its N - 1 predecessors. Each point of the “de-noised” sequence can therefore be computed as
![1 N∑- 1
y[n ] =-- x[n - k]
N k=0](livre553x.png) | (5.13) |
This is easily recognized as a convolution sum, and we can obtain the impulse response of the associated filter by letting x[n] = δ[n]; it is easy to see that
![N -1 ( 1
1- ∑ { N- for 0 ≤ n < N
h [n] = N δ[n - k] = (
k=0 0 for n < 0 and n ≥ N](livre554x.png) | (5.14) |
The impulse response, as it turns out, is a finite-support sequence so the filter that we have just built, is an FIR filter; this particular filter goes under the name of Moving Average (MA) filter. The “smoothing power” of this filter is dependent on the number of samples we take into account in the average or, in other words, on the length N of its impulse response. The filtered version of the original sequence for small and large values of N is plotted in Figures 5.3 and 5.4 respectively. Intuitively we can see that as N grows, more and more wiggles are removed. We will soon see how to handle the “smoothing power” of a filter in a precise, quantitative way. A general characteristic of FIR filters, that should be immediately noticed is that the value of the output does not depend on values of the input which are more than N steps away; FIR filters are therefore finite memory filters. Another aspect that we can mention at this point concerns the delay introduced by the filter: each output value is the average of a window of N input values whose representative sample is the one falling in the middle; thus, there is a delay of N∕2 samples between input and output, and the delay grows with N.
The moving average filter that we built in the previous Section has an obvious drawback; the more we want to smooth the signal, the more points we need to consider and, therefore, the more computations we have to perform to obtain the filtered value. Consider now the formula for the output of a length-M moving average filter:
![M∑- 1
yM[n] = 1-- x[n- k ]
M k=0](livre559x.png) | (5.15) |
We can easily see that
![M - 1 1
yM [n] = ------yM -1[n - 1]+ ---x[n] = λyM - 1[n - 1]+ (1- λ )x [n]
M M](livre560x.png) |
where we have defined λ = (M - 1)∕M. Now, as M grows larger, we can safely assume that if we compute the average over M - 1 or over M points, the result is basically the same: in other words, for M large, we can say that yM-1[n] ≈ yM[n]. This suggests a new way to compute the smoothed version of a sequence in a recursive fashion:
![y[n] = λy[n - 1]+ (1 - λ)x[n]](livre561x.png) | (5.16) |
This no longer looks like a convolution sum; it is, instead, an instance of a constant coefficient difference equation. We might wonder whether the transformation realized by (5.16) is still linear and time-invariant and, in this case, what its impulse response is. The first problem that we face in addressing this question stems from the recursive nature of (5.16): each new output value depends on the previous output value. We need to somehow define a starting value for y[n] or, in system theory parlance, we need to set the initial conditions. The choice which guarantees that the system defined by (5.16) is linear and time-invariant corresponds to the requirement that the system response to a sequence identically zero, be zero for all n; this requirement is also known as zero initial conditions, since it corresponds to setting y[n] = 0 for n < N0 where N0 is some time in the past.
The linearity of (5.16) can now be proved in the following way : assume that the output sequence for the system defined by (5.16) is y[n] when the input is x[n]. It is immediately obvious that y1[n] = αy[n] satisfies (5.16) for an input equal to αx[n]. All we need to prove is that this is the only solution. Assume this is not the case and call y2[n] the other solution; we have
| y1[n] | = λy1[n - 1] + (1 - λ) αx[n] αx[n] | ||
| y2[n] | = λy2[n - 1] + (1 - λ) αx[n] αx[n] |
Now that we know that (5.16) defines an LTI system, we can try to compute its impulse response. Assuming zero initial conditions and x[n] = δ[n], we have
![y[n] = 0 for n < 0
y[0] = 1 - λ
y[1] = (1 - λ)λ
y[2] = (1 - λ)λ2
.
..
y[n] = (1 - λ)λn](livre570x.png) | (5.17) |
so that the impulse response (shown in Figure 5.7) is
![n
h [n] = (1- λ) λ u[n]](livre571x.png) | (5.18) |
The impulse response clearly defines an IIR filter and therefore the immediate question is whether the filter is stable. Since a sufficient condition for stability is that the impulse response is absolutely summable, we have
![∑∞ n+1
||h[n]|| = lim |1 - λ|1---|λ|----
n= -∞ n→ ∞ 1- |λ|](livre572x.png) | (5.19) |
We can see that the above limit is finite for |λ| < 1 and so the system is BIBO stable for these values. The value of λ (which is, as we will see, the pole of the system) determines the smoothing power of the filter (Fig. 5.5). As λ → 1, the input is smoothed more and more as can be seen in Figure 5.6, at a constant computational cost. The system implemented by (5.16) is often called a leaky integrator, in the sense that it approximates the behavior of an integrator with a leakage (or forgetting) factor λ. The delay introduced by the leaky integrator is more difficult to analyze than for the moving average but, again, it grows with the smoothing power of the filter; we will soon see how to proceed in order to quantify the delay introduced by IIR filters.
As we can infer from this simple analysis, IIR filters are much more delicate entities than FIR filters; in the next Chapters we will also discover that their design is also much less straightforward and offers less flexibility. This is why, in practice, FIR filters are the filters of choice. IIR filters, however, and especially the simplest ones such as the leaky integrator, are extremely attractive when computational power is a scarce resource.
The above examples have introduced the notion of filtering in an operational and intuitive way. In order to make more precise statements on the characteristics of a discrete-time filter we need to move to the frequency domain. What does a filtering operation translate to in the frequency domain? The fundamental result of this Section is the convolution theorem for discrete-time signals: a convolution in the discrete-time domain is equivalent to a multiplication of Fourier transforms in the frequency domain. This result opens up a very fruitful perspective on filtering and filter design, together with alternative approaches to the implementation of filtering devices, as we will see momentarily.
Consider the case of a complex exponential sequence of frequency ω0 as the
input to a linear time-invariant system ; we have
![∞∑ ∞∑ ∞∑
H {ejω0n} = ejω0kh [n - k] = h[k]ejω0(n-k) = ejω0n h[k]e-jω0k = H (ejω0)ejω0n
k= -∞ k=-∞ k= -∞](livre574x.png) | (5.20) |
where H(ejω0) (i.e. the DTFT of h[n] at ω = ω0) is called the frequency response of the filter at frequency ω0. The above result states the fundamental fact that complex exponentials are eigensequences(3) of linear-time invariant systems. We notice the following two properties:
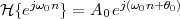
i.e. the output oscillation is scaled in amplitude by A0 =
 H(ejω0
H(ejω0 , the magnitude of the DTFT, and it is shifted in phase
by θ0 = ∡H(ejω0), the phase of the DTFT.
, the magnitude of the DTFT, and it is shifted in phase
by θ0 = ∡H(ejω0), the phase of the DTFT.
Consider two sequences x[n] and h[n], both absolutely summable. The discrete-time Fourier transform of the convolution y[n] = x[n] * h[n] is
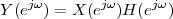 | (5.21) |
The proof is as follows: if we take the DTFT of the convolution sum, we have
![∑∞ ∑∞
Y (ejω) = x[k ]h[n - k]e-jωn
n=-∞ k=- ∞](livre579x.png)
and by interchanging the order of summation (which can be done because of the absolute summability of both sequences) and by splitting the complex exponential, we obtain
![jω ∑∞ - jωk ∑∞ -jω(n-k)
Y (e ) = x[k ]e h [n - k]e
k=- ∞ n=-∞](livre580x.png)
from which the result immediately follows after a change of variable. Before discussing the implications of the theorem, we to state and prove its dual, which is called the modulation theorem.
Consider now the discrete-time sequences x[n] and w[n], both absolutely summable, with discrete-time Fourier transforms X(ejω) and W(ejω). The discrete-time Fourier transform of the product y[n] = x[n]w[n] is
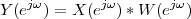 | (5.22) |
where the DTFT convolution is via the convolution operator for 2π-periodic functions, defined in (5.12). This is easily proven as follows: we begin with the DTFT inversion formula of the DTFT convolution:
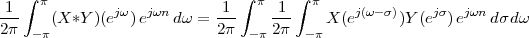 |
and we split the last integral to obtain
![( 1 ∫ π ) ( 1 ∫ π )
--- X(ej(ω-σ))ej(ω-σ)n dω --- Y (ejσ)ejσn dσ = x[n ]y[n]
2π -π 2π -π](livre583x.png) |
These fundamental results are summarized in Table 5.1.
|
Since an LTI system is completely characterized by its impulse response, it is also uniquely characterized by its frequency response. The frequency response provides us with a different perspective on the properties of a given filter, which are embedded in the magnitude and the phase of the response.
Just as the impulse response completely characterizes a filter in the discrete-time domain, its Fourier transform, called the filter’s frequency response, completely characterizes the filter in the frequency domain. The properties of LTI systems are described in terms of their DTFTs magnitude and phase, each of which controls different features of the system’s behavior.
Magnitude. The most powerful intuition arising from the convolution theorem is obtained by considering the magnitude of the spectra involved in a filtering operation. Recall that a Fourier spectrum represents the energy distribution of a signal in frequency; by appropriately “shaping” the magnitude spectrum of a filter’s impulse response we can easily boost, attenuate, and even completely eliminate, a given part of the frequency content in the filtered input sequence. According to the way the magnitude spectrum is affected by the filter, we can classify filters into three broad categories (here as before we assume that the impulse response is real, and therefore the associated magnitude spectrum is symmetric; in addition, the 2π periodicity of the spectrum is implicitly understood):
The frequency interval (or intervals) for which the magnitude of the frequency response is zero (or practically negligible) is called the stopband. Conversely, the frequency interval (or intervals) for which the magnitude is non-negligible is called the passband.
Phase. The phase response of a filter has an equally important effect on the output signal, even though its impact is less intuitive.
By and large, the phase response acts as a generalized delay. Consider Equation (5.20) once more; we can see that a single sinusoidal oscillation undergoes a phase shift equal to the phase of the impulse response’s Fourier transform. A phase offset for a sinusoid is equivalent to a delay in the time domain. This is immediately obvious in the case of a trigonometric function defined on the real line since we can always write
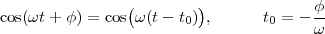
For discrete-time sinusoids, it is not always possible to express the phase offset in terms of an integer number of samples (exactly for the same reasons for which a discrete- time sinusoid is not always periodic in its index n); yet the effect is the same, in that a phase offset corresponds to an implicit delay of the sinusoid. When the phase offset for a complex exponential is not an integer multiple of its frequency, we say that we are in the presence of a fractional delay. Now, since each sinusoidal component of the input signal may be delayed by an arbitrary amount, the output signal will be composed of sinusoids whose relative alignment may be very different from the original. Phase alignment determines the shape of the signal in the time domain, as we have seen in Section 4.7.4. A filter with unit magnitude across the spectrum, which does not affect the amplitude of the sinusoidal components, but whose phase response is not linear, can completely change the shape of a filtered signal.(5)
Linear Phase. A very important type of phase response is linear phase:
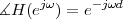 | (5.23) |
Consider a simple system which just delays its input, i.e. y[n] = x[n - D]
with D Z; this is obviously an LTI system with impulse response
h[n] = δ[n-D] and frequency response H(ejω) = e-jωD. This means that, if
the value d in (5.23) is an integer, (5.23) defines a pure delay system; since
the magnitude is constant and equal to one, this is an example of an allpass
filter. If d is not an integer, (5.23) still defines an allpass delay system for
which the delay is fractional, and we should interpret its effect as
explained in the previous Section. In particular, if we think of the
original signal in terms of its Fourier reconstruction formula, the
fractionally delayed output is obtained by stepping forward the initial
phase of all oscillators by a non-integer multiple of the frequency.
In the discrete-time domains, we have a signal which takes values
“between” the original samples but, since the relative phase of any
one oscillator, with respect to the others, has remained the same as
in the original signal, the shape of the signal in the time domain is
unchanged.
For a general filter with linear phase we can always write
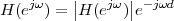
In other words, the net effect of the linear phase filter is that of a cascade of two systems: a zero-phase filter which affects only the spectral magnitude of the input and therefore introduces no phase distortion, followed by a (possibly fractional) delay system (which, again, introduces just a delay but no phase distortion).
Group Delay. When a filter does not have linear phase, it is important to quantify the amount of phase distortion both in amount and in location. Nonlinear phase is not always a problem; if a filter’s phase is nonlinear just in the stopband, for instance, the actual phase distortion is negligible. The concept of group delay is a measure of nonlinearity in the phase; the idea is to express the phase response around any given frequency ω0 using a first order Taylor approximation. Define φ(ω) = ∡H(ejω) and approximate φ(ω) around ω0 as φ(ω0 + τ) = φ(ω0) + τφ′(ω0); we can write
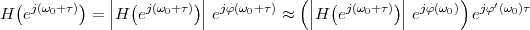 | (5.24) |
so that, approximately, the frequency response of the filter is linear phase for at least a group of frequencies around a given ω0. The delay for this group of frequencies is the negative of the derivative of the phase, from which the definition of group delay is
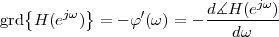 | (5.25) |
For truly linear phase systems, the group delay is a constant. Deviations from a constant value quantify the amount of phase distortion introduced by a filter in terms of the (possibly non-integer) number of samples by wich a frequency component is delayed.
Now that we know what to look for in a filter, we can revisit the “empirical” de-noising filters introduced in Section 5.3. Both filters are realizable, in the sense that they can be implemented with practical and efficient algorithms, as we will study in the next Chapters. Their frequency responses allow us to qualify and quantify precisely their smoothing properties, which we previously described, in an intuitive fashion.
Moving Average. The frequency response of the moving average filter (Sect. 5.3.1) can be shown to be
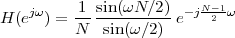 | (5.26) |
In the above expression, it is easy to separate the magnitude and the phase, which are plotted in Figure 5.8. The group delay for the filter is the constant (N - 1)∕2, which means that the filter delays its output by (N - 1)∕2 samples (i.e. there is a fractional delay for N even). This formalizes the intuition that the “representative sample” for an averaging window of N samples is the sample in the middle. If N is even, this does not correspond to a real sample but to a “ghost” sample in the middle.
Leaky Integrator. The frequency response of the leaky integrator in Section 5.3.2 is
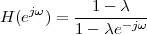 | (5.27) |
Magnitude and phase are, respectively,
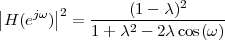 | (5.28) |
![[ λ sin (ω ) ]
∡H (ejω) = arctan ------------
1 - λ cos(ω )](livre594x.png) | (5.29) |
and they are plotted in Figure 5.9. The group delay, also plotted in Figure 5.9, is obtained by differentiating the phase response:
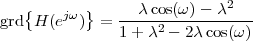 | (5.30) |
The group delay indicates that, for the frequencies for which the magnitude is not very small, the delay increases with the smoothing power of the filter.
Note that, according to the classification in Section 5.4.3, both the moving average and the leaky integrator are lowpass filters.
The frequency characterization introduced in Section 5.4.3 immediately leads to questions such as “What is the best lowpass filter?” or “Can I have a highpass filter with zero delay?” It turns out that the answers to such questions are given by ideal filters. Ideal filters are what the (Platonic) name suggests: theoretical abstractions which capture the essence of the basic filtering operation but which are not realizable in practice. In a way, they are the “gold standard” of filter design.
Ideal Lowpass. The ideal lowpass filter is a filter which “kills” all frequency content above a cutoff frequency ωc and leaves all frequency content below ωc untouched; it is defined in the frequency domain as
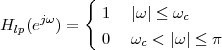 | (5.31) |
and clearly, the filter has zero phase delay. The ideal lowpass can also be defined in terms of its bandwidth ωb = 2ωc. The DTFT inversion formula gives the corresponding impulse response:
![sin (ωcn )
hlp[n] = --------
πn](livre600x.png) | (5.32) |
The impulse response is a symmetric infinite sequence and the filter is therefore IIR; unfortunately, however, it can be proved that no realizable system (i.e. no algorithm with a finite number of operations per output sample) can exactly implement the above impulse response. More bad news: the decay of the impulse response is slow, going to zero only as 1∕n, and it is not absolutely summable; this means that any FIR approximation of the ideal lowpass obtained by truncating h[n] needs a lot of samples to achieve some accuracy and that, in any case, convergence to the ideal frequency response is only be in the mean square sense. An immediate consequence of these facts is that, when designing realizable filters, we will take an entirely different approach.
Despite these practical difficulties, the ideal lowpass and its associated DTFT pair are so important as a theoretical paradigm, that two special function names are used to denote the above expressions. These are defined as follows:
| rect(x) | = 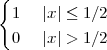 | (5.33) |
| sinc(x) | = 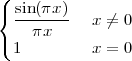 | (5.34) |
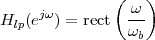 | (5.35) |
(obviously 2π-periodized over all R). Its impulse response in terms of bandwidth becomes
![( )
h [n ] = ωb-sinc ωb-n
lp 2π 2π](livre606x.png) | (5.36) |
or, in terms of cutoff frequency,
![ωc (ωc )
hlp[n ] =-π-sinc -π-n](livre607x.png) | (5.37) |
The DTFT pair:
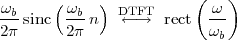 | (5.38) |
constitutes one of the fundamental relationships of digital signal processing.
Note that as ωb → 2π, we re-obtain the well-known DTFT pair δ[n] ↔ 1,
while as ωb → 0 we can re-normalize by (2π∕ωb) to obtain 1 ↔ (ω).
(ω).
Ideal Highpass. The ideal highpass filter with cutoff frequency ωc is the complementary filter to the ideal lowpass, in the sense that it eliminates all frequency content below the cutoff frequency. Its frequency response is
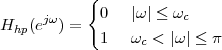 | (5.39) |
where the 2π-periodicity is as usual implicitly assumed. From the relation Hh(ejω) = 1 - rect(ω∕2ωc) the impulse response is easily obtained as
![ω ( ω )
hhp[n] = δ[n]- -csinc -cn
π π](livre611x.png)
Ideal Bandpass. The ideal bandpass filter with center frequency ω0 and bandwidth ωb, ωb∕2 < ω0 is defined in the frequency domain between -π and π as
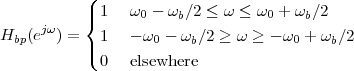 | (5.40) |
where the 2π-periodicity is, as usual, implicitly assumed. It is left as an exercise to prove that the impulse response is
![( )
hbp[n] = 2 cos(ω0n ) ωb-sinc ωb-n
2π 2π](livre613x.png) | (5.41) |
Hilbert Filter. The Hilbert filter is defined in the frequency domain as
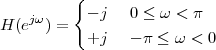 | (5.42) |
where the 2π-periodicity is, as usual, implicitly assumed. Its impulse response is easily computed as
![(
2sin2(πn-∕2)- { 0 for n even
h[n] = πn = ( -2- for n odd
nπ](livre618x.png) | (5.43) |
Clearly  H(ejω)
H(ejω) = 1, so this filter is allpass. It introduces a phase shift of
π∕2 in the input signal so that, for instance,
= 1, so this filter is allpass. It introduces a phase shift of
π∕2 in the input signal so that, for instance,
![h[n]* cos(ω0n ) = - sin(ω0n)](livre621x.png) | (5.44) |
as one can verify from (4.39) and (4.40). More generally, the Hilbert filter is used in communication systems to build efficient demodulation schemes, as we will see later. The fundamental concept is the following: consider a real signal x[n] and its DTFT X(ejω); consider also the signal processed by the Hilbert filter y[n] = h[n] * x[n]. This can be defined as
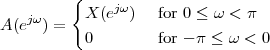
i.e. A(ejω) is the positive-frequency part of the spectrum of x[n]. Since x[n] is real, its DTFT has symmetry X(ejω) = X*(e-jω) and therefore we can write
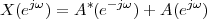
By separating the real and imaginary parts we can always write A(ejω) = AR(ejω) + jAI(ejω) and so
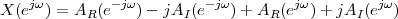
For the filtered signal, we know that Y (ejω) = H(ejω)X(ejω) and therefore
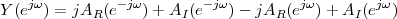
It is, thus, easy to see that
![x[n ]+ jy[n ] DT←F→T 2A (ejω)](livre626x.png) | (5.45) |
i.e. the spectrum of the signal a[n] = x[n] + jy[n] contains only the positive-frequency components of the original signal x[n]. The signal a[n] is called the analytic signal associated to x[n].
Contrary to ideal filters, realizable filters are LTI systems which can be implemented in practice; this means that there exists an algorithm which computes every output sample with a finite number of operations and using a finite amount of memory storage. Note that the impulse response of a realizable filter need not be finite-support; while FIR filters are clearly realizable we have seen at least one example of realizable IIR filter (i.e. the leaky integrator).
Let us consider (informally) the possible mathematical description of an LTI system, seen as a “machine” which takes one input sample at a time and produces a corresponding output sample. Linearity in the input-output relationship implies that the description can involve only linear operations, i.e. sums and multiplications by scalars. Time invariance implies that the scalars be constants. Finally, realizability implies that, inside the above mentioned “machine”, there can be only a finite number of adders and multipliers (and, correspondingly, a finite number of memory cells). Such a mathematical relationship goes under the name of constant-coefficient difference equation (CCDE).
In its most general form, a constant-coefficient difference equation defines a relationship between an input signal x[n] and an output signal y[n] as
![N∑-1 M∑-1
aky[n - k] = bkx[n - k]
k=0 k=0](livre627x.png) | (5.46) |
In the rest of this book we restrict ourselves to the case in which all the coefficients ak and bk are real. Usually, a0 = 1, so that the above equation can easily be rearranged as
![M- 1 N -1
y[n] = ∑ b x[n - k]- ∑ a y[n - k]
k k
k=0 k=1](livre628x.png) | (5.47) |
Clearly, the above relation defines each output sample y[n] as a linear
combination of past and present input values and past output values. However,
it is easy to see that if aN-1 0 we can for instance rearrange (5.46)
as
0 we can for instance rearrange (5.46)
as
![M∑- 1 ′ N∑-2 ′
y[n - N + 1] = bkx[n - k]- aky[n - k]
k=0 k=0](livre630x.png)
where a′k = ak∕aN-1 and b′k = bk∕aN-1. With the change of variable m = n - N + 1, this becomes
![N -1 N -1
y[m] = ∑ b′x[m + k]- ∑ a′y[m + k]
k k
k=N- M k=1](livre631x.png) | (5.48) |
which shows that the difference equation can also be computed in another way, namely by expressing y[m] as a linear combination of future values of input and output. It is rather intuitive that the first approach defines a causal behavior, while the second approach is anticausal.
Contrary to the differential equations used in the characterization of continuous-time systems, difference equations can be used directly to translate the transformation operated by the system into an explicit algorithmic form. To see this, and to gain a lot of insight into the properties of difference equations, it may be useful to consider a possible implementation of the system in (5.47), shown as a C code sample in Figure 5.14.
|
extern double a[N]; // The a’s coefficients extern double b[M]; // The b’s coefficients static double x[M]; // Delay line for x static double y[N]; // Delay line for y double GetOutput(double input) { int k; // Shift delay line for x: for (k = N-1; k > 0; k--) x[k] = x[k-1]; // new input value x[n]: x[0] = input; // Shift delay line for y: for (k = M-1; k > 0; k--) y[k] = y[k-1]; double y = 0; for (k = 0; k < M; k++) y += b[k] * x[k]; for (k = 1; k < M; k++) y -= a[k] * y[k]; // New value for y[n]; store in delay line return (y[0] = y); }
|
It is easy to verify that
If we try to compile and execute the code, however, we immediately run into an initialization problem: the first time (actually, the first max(N,M - 1) times) we call the function, the delay lines which hold past values of x[n] and y[n] will contain undefined values. Most likely, the compiler will notice this condition and will print a warning message signaling that the static arrays have not been properly initialized. We are back to the problem of setting the initial conditions of the system. The choice which guarantees linearity and time invariance is called the zero initial conditions and corresponds to setting the delay lines to zero before starting the algorithm. This choice implies that the system response to the zero sequence is the zero sequence and, in this way, linearity and time invariance can be proven as in Section 5.3.2.
CCDEs provide a powerful operational view of filtering; in very simple case, such as in Section 5.3.2 or in the case of FIR filters, the impulse response (and therefore its frequency response) can be obtained directly from the filter’s equation. This is not the general case however, and to analyze a generic realizable filter from its CCDE, we need to be able to easily derive the transfer function from the CCDE. Similarly, in order to design a realizable filter which meets a set of requirement, we need to devise a procedure which “tunes” the coefficients in the CCDE until the frequency response is satisfactory while preserving stability; in order to do this, again, we need a convenient tool to link the CCDE to the magnitude and phase response. This tool will be introduced in the next Chapter, and goes under the name of z-transform.
Example 5.1: Radio transmission
AM radio was one of the first forms of telecommunication and remains to this day a ubiquitous broadcast method due to the ease with which a robust receiver can be assembled. From the hardware point of view, an AM transmitter uses a transducer (i.e. a microphone) to convert sound to an electric signal, and then modulates this signal into a frequency band which correspond to a region of the electromagnetic spectrum in which propagation is well-behaved (see also Section 12.1.1). An AM receiver simply performs the reverse steps. Here we can neglect the physics of transducers and of antennas and concentrate on an idealized digital AM transmitter.
|
|
Modulation. Suppose x[n] is a real, discrete-time signal representing voice or music. Acoustic signals are a type of lowpass (or baseband) signal; while good for our ears (which are baseband receivers) baseband signals are not suitable for direct electromagnetic transmission since propagation in the baseband is poor and since occupancy of the same band would preclude the existence of multiple radio channels. We need to use modulation in order to shift a baseband signal in frequency and transform it into a bandpass signal prior to transmission. Modulation is accomplished by multiplying the baseband signal by an oscillatory carrier at a given center frequency; note that modulation is not a time-invariant operation. Consider the signal
![{ }
y[n] = Re x[n]ejωcn](livre635x.png)
where ωc is the carrier frequency. This corresponds to a cosine modulation since
![y[n] = x[n]cos(ωcn)](livre636x.png)
and (see (4.56)):
![[ ]
Y (ejω ) = 1 X (ej(ω- ωc))+ X(ej(ω+ωc))
2](livre637x.png)
The complex signal c[n] = x[n]ejωcn is called the complex bandpass signal and, while not transmissible in practice, it is a very useful intermediate representation of the modulated signal especially in the case of Hilbert demodulation.
Assume that the baseband signal has spectral support [-ωb∕2, ωb∕2] (i.e. assume that its energy is zero for |ω| > ωb∕2); a common way to express this concept is to say that the bandwidth of the baseband signal is ωb. What is the maximum carrier frequency ωc that we can use to create a bandpass signal? If we look at the effect of modulation on the spectrum and we take into account its 2π-periodicity as in Figure 5.15 we can see that if we choose too large a modulation frequency the positive passband overlaps with the negative passband of the first repetition. Intuitively, we are trying to modulate too fast and we are falling back into the folding of frequencies larger than 2π which we have seen in Example 2.1. In our case the maximum frequency of the modulated signal is ωc + ωb∕2. To avoid overlap with the first repetition of the spectrum, we must guarantee that:
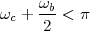 | (5.49) |
which limit the maximum carrier frequency to ωc < π - ωb∕2.
Demodulation. An AM receiver must undo the modulation process; again,
assume we’re entirely in the discrete-time domain. The first step is to isolate
the channel of interest by using a sharp bandpass filter centered on the
modulation frequency ωc (see also Exercise 5.7). Neglecting the impairments
introduced by the transmission (noise and distortion) we can initially assume
that after filtering the receiver possesses an exact copy of the modulated
signal y[n]. The original signal x[n] can be retrieved in several ways; an
elegant scheme, for instance, is Hilbert demodulation. The idea behind
Hilbert demodulation is to reconstruct the complex bandpass signal c[n]
from y[n] as c[n] = y[n] + j h[n] * y[n]
h[n] * y[n] where h[n] is the impulse
response of the Hilbert filter as given in (5.43). Once this is done, we
multiply c[n] by the complex exponential e-jωcn and take the real
part. This demodulation scheme will be studied in more detail in
Section 12.3.1.
where h[n] is the impulse
response of the Hilbert filter as given in (5.43). Once this is done, we
multiply c[n] by the complex exponential e-jωcn and take the real
part. This demodulation scheme will be studied in more detail in
Section 12.3.1.
A more classic scheme involves multiplying y[n] by a sinusoidal carrier at the same frequency as the carrier and filtering the result with a lowpass filter with cutoff at ωb∕2. After the multiplication, the signal is
![u [n] = y[n ]cosωcn = x[n]cos2ωcn = 1-x[n]+ 1-x[n]cos2ωcn
2 2](livre641x.png) |
and the corresponding spectrum is therefore
![[ ]
jω 1- jω 1- ( j(ω+2ωc)) ( j(ω- 2ωc))
U (e ) = 2 X (e ) + 4 X e + X e](livre642x.png)
|
|
This spectrum is shown in Figure 5.16, with explicit repetitions; note that if the maximum frequency condition in (5.49) is satisfied, the components at twice the carrier frequency that may leak into the [-π,π] interval from the neighboring spectral repetitions do not overlap with the baseband. From the figure, if we choose
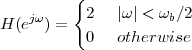
then 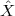 (ejω) = H(ejω)U(ejω) = X(ejω). The component at ω = 2ωc is
filtered out and thus the spectrum of the demodulated signal is equal to the
spectrum of the original signal. Of course the ideal low-pass is in
practice replaced by a realizable IIR or an FIR filter with adequate
properties.
(ejω) = H(ejω)U(ejω) = X(ejω). The component at ω = 2ωc is
filtered out and thus the spectrum of the demodulated signal is equal to the
spectrum of the original signal. Of course the ideal low-pass is in
practice replaced by a realizable IIR or an FIR filter with adequate
properties.
Finally, for the fun of it, we can look at a “digital galena” demodulator.
Galena receivers (whose general structure is shown in Figure 5.17) are the
simplest (and oldest) type of radio receiver: the antenna and the tuning coil
form a variable LC bandpass filter to select the band while a galena crystal,
touched by a thin metal wire called the “cat’s whisker”, acts as a rectifying
nonlinearity. A pair of high-impedance headphones is connected between the
cat’s whisker and ground; the mechanical inertia of the headphones
acts as a simple lowpass filter which completes the radio receiver. In
a digital simulation of a galena receiver, the antenna and coil are
replaced by our sharp digital bandpass filter, at the output of which we
find y[n]. The rectified signal at the cat’s whisker can be modeled as
yr[n] =  y[n]
y[n] ; since yr[n] is positive, the integration realized by the
crude lowpass in the headphone can reveal the baseband envelope and
eliminate most of the high frequency content. The process is best
understood in the time domain and is illustrated in Figure 5.18. Note that,
spectrally, the qualitative effect of the nonlinearity is indeed to bring the
bandpass component back to baseband; as for most nonlinear processing,
however, no simple analytical form for the baseband spectrum is
available.
; since yr[n] is positive, the integration realized by the
crude lowpass in the headphone can reveal the baseband envelope and
eliminate most of the high frequency content. The process is best
understood in the time domain and is illustrated in Figure 5.18. Note that,
spectrally, the qualitative effect of the nonlinearity is indeed to bring the
bandpass component back to baseband; as for most nonlinear processing,
however, no simple analytical form for the baseband spectrum is
available.
Example 5.2: Can IIRs see the future?
If we look at the bottom panel of Figure 5.9 we can notice that the group
delay is negative for frequencies above approximately π∕7. Does that mean
that we can look into the future?
(Hint: no.)
|
|
To see what we mean, consider the effect of group delay on a narrowband signal x[n] centered at ω0; a narrowband signal can be easily constructed by modulating a baseband signal s[n] (i.e. a signal so that S(ejω) = 0 for |ω| > ωb and ωb very small). Set
![x[n] = s[n]cos(ω0n)](livre653x.png)
and consider a real-valued filter H(ejω) such that for τ small it is
 H(ej(ω0+τ))
H(ej(ω0+τ)) ≈ 1 and the antisymmetric phase response is
≈ 1 and the antisymmetric phase response is
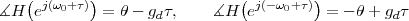 |
clearly the group delay of the filter around ω0 is gd. If we filter the narrowband signal x[n] with H(ejω), we can write the DTFT of the output for 0 ≤ ω < π as
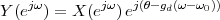
since, even though the approximation for H(ejω) holds only in a small neighborhood of ω0, X(ejω) is zero everywhere else so “we don’t care”. If we write out the expression for the full spectrum we have
![1 [ ( ) ( ) ] 1 [ ( ) ( ) ]
Y (ejω) = --S ej(ω- ω0) ej(θ- gd(ω-ω0)) + S ej(ω+ω0) ej(-θ+gd(ω-ω0)) = -- S ej(ω-ω0) ejφ + S ej(ω+ω0) e-jφ e-jgd&#x
2 2](livre658x.png) |
where we have put φ = θ + gdω0. We can recognize by inspection that the first term is simply s[n] modulated by a cosine with a phase offset of φ; the trailing linear phase term is just a global delay. If we assume gd is an integer we can therefore write
![y[n] = s[n- gd]cos(nω0 + θ)](livre659x.png) | (5.50) |
so that the effect of the group delay is to delay the narrowband envelope by exactly gd samples. The analysis still holds even if gd is not an integer, as we will see in Chapter 9 when we deal with fractional delays.
Now, if gd is negative, (5.50) seems to imply that the envelope s[n] is advanced in time so that a filter with negative group delay is able to produce a copy of the input before the input is even applied; we would have a time machine which can look into the future! Clearly there must something wrong but the problem cannot be with the filter since the leaky integrator is an example of a perfectly realizable filter with negative group delay in the stopband. In fact, the inconsistency lies with the hypothesis of having a perfectly narrowband signal: just like the impulse response of an ideal filter is necessarily an infinite two-sided sequence, so any perfectly narrowband signal cannot have an identifiable “beginning”. When we think of “applying” the input to the filter, we are implicitly assuming a one-sided (or, more likely, a finite-support) signal and this signal has nonzero spectral components at all frequencies. The net effect of these is that the overall delay for the signal will always be nonnegative.
Discrete-time filters are covered in all signal processing books, e.g. a good review is given in Discrete-Time Signal Processing, by A. V. Oppenheim and R. W. Schafer (Prentice-Hall, last edition in 1999).
Exercise 5.1: Linearity and time-invariance – I. Consider the
transformation  x[n]
x[n] = nx[n]. Does define an LTI system?
= nx[n]. Does define an LTI system?
Exercise 5.2: Linearity and time-invariance – II. Consider a
discrete-time system {⋅}. When the input is the signal x[n] = cos (2π∕5)n
(2π∕5)n ,
the output is
,
the output is  x[n]
x[n] = sin
= sin (π∕2)n
(π∕2)n . Can the system be linear and
time-break invariant? Explain.
. Can the system be linear and
time-break invariant? Explain.
Exercise 5.3: Finite-support convolution. Consider the finite-support signal h[n] defined as
![{
1 for |n| ≤ M
h[n ] =
0 otherwise](livre668x.png)
 X(ejω)
X(ejω) changes as M
grows.
changes as M
grows.
Exercise 5.4: Convolution – I. Let x[n] be a discrete-time sequence defined as
![(
|{ M - n 0 ≤ n ≤ M
x [n] = M + n - M ≤ n ≤ 0
|(
0 otherwise](livre671x.png)
for some odd integer M.
Exercise 5.5: Convolution – II. Consider the following discrete-time signals:
| x[n] | = cos(1.5n) | ||
| y[n] | =  sinc sinc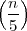 |
 x[n]
x[n] 2 * y[n]
2 * y[n]
Exercise 5.6: System properties. Consider the following input-output relations and, for each of the underlying systems, determine whether the system is linear, time invariant, BIBO stable, causal or anti-causal. Characterize the eventual LTI systems by their impulse response.
Exercise 5.7: Ideal filters. Derive the impulse response of a bandpass filter with center frequency ω0 and passband ωb:
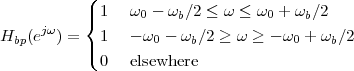
(Hint: consider the following ingredients: a cosine of frequency ω0, a lowpass filter of bandwidth ωb and the modulation theorem.)
Exercise 5.8: Zero-phase filtering. Consider an operator  which
turns a sequence into its time-reversed version:
which
turns a sequence into its time-reversed version:
![{ }
R x[n] = x[- n]](livre677x.png)
Suppose you have an LTI filter with impulse response h[n] and you
perform the following sequence of operations in the followin order:
| s[n] | =  x[n] x[n] | ||
| r[n] | =  s[n] s[n] | ||
| w[n] | =  r[n] r[n] | ||
| y[n] | =  w[n] w[n] |
Exercise 5.9: Nonlinear signal processing. Consider the system
implementing the input-output relation y[n] =  x[n]
x[n] = x2[n].
= x2[n].
Now consider the following cascade system:
|
|
where 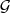 is the following ideal highpass filter:
is the following ideal highpass filter:
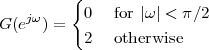
(as per usual, G(ejω) is 2π-periodic – i.e. prolonged by periodicity outside of
[-π,π]). The output of the cascade is therefore v[n] = ![{ { } }
H x[n]](livre690x.png) .
.
Exercise 5.10: Analytic signals and modulation. In this exercise we explore a modulation-demodulation scheme commonly used in data transmission systems. Consider two real sequences x[n] and y[n], which represent two data streams that we want to transmit. Assume that their spectrum is of lowpass type, i.e. X(ejω) = Y (ejω) = 0 for |ω| > ωc. Consider further the following derived signal:
![c[n] = x[n ]+ jy[n ]](livre692x.png)
and the modulated signal:
![jω0n
r[n] = c[n]e , ωc < ω0 < π - ωc](livre693x.png)
 R(ejω)
R(ejω) for whatever shapes
you choose for X(ejω),Y (ejω). Verify from your plot that r[n] is
an analytic signal.
for whatever shapes
you choose for X(ejω),Y (ejω). Verify from your plot that r[n] is
an analytic signal.The signal r[n] is called a complex bandpass signal. Of course it cannot be transmitted as such, since it is complex. The transmitted signal is, instead,
![{ }
s[n] = Re r[n]](livre696x.png)
This modulated signal is an example of Quadrature Amplitude Modulation (QAM).
Now we want to recover x[n] and y[n] from s[n]. To do so, follow these steps:
 h[n] * s[n]
h[n] * s[n] = r[n], where h[n] is the Hilbert
filter. In other words, we have recovered the analytic signal r[n]
from its real part only.
= r[n], where h[n] is the Hilbert
filter. In other words, we have recovered the analytic signal r[n]
from its real part only.
| © Presses polytechniques et universitaires romandes, 2008 All rights reserved |
Mathematically, the z-transform is a mapping between complex sequences
and analytical functions on the complex plane. Given a discrete-time signal
x[n], the z-transform of x[n] is formally defined as the complex function of a
complex variable z C
![∞∑
X (z) = Z {x[n]} = x[n]z-n
n=-∞](livre699x.png) | (6.1) |
Contrary to the Fourier transform (as well as to other well-known transforms such as the Laplace transform or the wavelet transform), the z-transform is not an analysis tool per se, in that it does not offer a new physical insight on the nature of signals and systems. The z-transform, however, derives its status as a fundamental tool in digital signal processing from two key features:
Probably the best approach to the z-transform is to consider it as a clever mathematical transformation which facilitates the manipulation of complex sequences; for discrete-time filters, the z-transform bridges the algorithmic side (i.e. the CCDE) to the analytical side (i.e. the spectral properties) in an extremely elegant, convenient and ultimately beautiful way.
To see the usefulness of the z-transform in the context of the analysis and the design of realizable filters, it is sufficient to consider the following two formal properties of the z-transform operator:
![{ }
Z αx [n ]+ βy[n] = αX (z)+ βY (z)](livre700x.png)
![{ } - N
Z x[n - N ] = z X (z)](livre701x.png)
In the above, we have conveniently ignored all convergence issues for the z-transform; these will be addressed shortly but, for the time being, let us just make use of the formalism as it stands.
Consider the generic filter CCDE (Constant-Coefficient Difference Equation) in (5.46):
![M∑- 1 N∑-1
y[n] = bkx[n - k]- aky[n - k]
k=0 k=1](livre702x.png)
If we apply the z-transform operator to both sides and exploit the linearity and time-shifting properties, we have
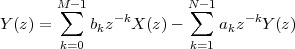 | (6.2) |
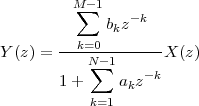 | (6.3) |
 | (6.4) |
H(z) is called the transfer function of the LTI filter described by the CCDE. The following properties hold:
 δ[n]
δ[n] = 1).
= 1).
![{ }
Z y[n ] = Y (z) = X (z)H (z)](livre708x.png) | (6.5) |
which can easily be verified using an approach similar to the one used in Section 5.4.2.
As we saw in Section 5.7.1, a CCDE can be rearranged to express either a causal or a noncausal realization of a filter. This ambiguity is reflected in the z-transform and can be made explicit by the following example. Consider the sequences
| x1[n] | = u[n] | (6.6) |
| x2[n] | = δ[n] - u[-n] | (6.7) |
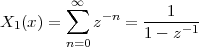 | (6.8) |
(again, let us neglect convergence issues for the moment). For the second sequence we have
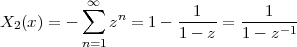 | (6.9) |
so that, at least formally, X1(z) = X2(z). In other words, the z-transform is not an invertible operator or, more precisely, it is invertible up to a causality specification. If we look more in detail, the sum in (6.8) converges only for |z| > 1 while the sum in (6.9) converges only for |z| < 1. This is actually a general fact: the values for which a z-transform exists define the causality or anticausality of the underlying sequence.
We are now ready to address the convergence issues that we have put aside so far. For any given sequence x[n], the set of points on the complex plane for which ∑ x[n]z-n exists and is finite, is called the region of convergence (ROC) for the z-transform. In order to study the properties of this region, it is useful to split the sum in (6.1) as
![-∑ 1 -n M∑ -n
X(z) = x[n]z + x[n]z
n=-N n=0](livre711x.png) | (6.10) |
![∑N n M∑ x-[n]
X (z) = x [n]z + zn
n=1 n=0](livre712x.png) | (6.11) |
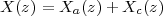 | (6.12) |
where N,M ≥ 0 and where both N and M can be infinity. Now, for X(z0) to exist and be finite, both power series Xa(z) and Xc(z) must converge in z0; since they are power series, when they do converge, they converge absolutely. As a consequence, for all practical purposes, we define the ROC in terms of absolute convergence:(1)
![∑∞
z ∈ ROC {X (z)} ⇐ ⇒ ||x[n]z-n|| < ∞
n= -∞](livre714x.png) | (6.13) |
Then the following properties are easily derived:
ROC,
then the set of complex points  z ||z| = |z0|
z ||z| = |z0| is also in the ROC,
and such a set defines a circle.
is also in the ROC,
and such a set defines a circle.
 Xa(z)
Xa(z) = C \ {∞}).
As for Xc(z), assume Xc(z0) exists and is finite and take any z1
so that |z1| > |z0|; we have that for all n:
= C \ {∞}).
As for Xc(z), assume Xc(z0) exists and is finite and take any z1
so that |z1| > |z0|; we have that for all n:
![||x[n]|| ||x [n]||
||--n-|| ≤ ||-n-||
z1 z0](livre719x.png)
so that Xc(z) is absolutely convergent in z1 as well.
 Xc(z)
Xc(z) = C\{0}). As for Xa(z), assume Xa(z0) exists
and is finite and take any z1 so that |z1| < |z0|; we have that for
all n:
= C\{0}). As for Xa(z), assume Xa(z0) exists
and is finite and take any z1 so that |z1| < |z0|; we have that for
all n:
![|| n|| || n||
x[n]z0 ≤ x[n ]z1](livre722x.png)
so that Xa(z) is absolutely convergent in z1 as well.
The z-transform provides us with a quick and easy way to test the stability of a linear system. Recall from Section 5.2.2 that a necessary and sufficient condition for an LTI system to be BIBO stable is the absolute summability of its impulse response. This is equivalent to saying that a system is BIBO stable if and only if the z-transform of its impulse response is absolutely convergent in |z| = 1. In other words, a system is BIBO stable if the ROC of its transfer function includes the unit circle.
For rational transfer functions, the analysis of the ROC is quite simple; indeed, the only ”trouble spots” for convergence are the values for which the denominator of (6.3) is zero. These values are called the poles of the transfer functions and clearly they must lie outside of the ROC. As a consequence, we have an extremely quick and practical rule to determine the stability of a realizable filter.
For an anticausal system the procedure is symmetrical; once the largest-magnitude pole is known, the ROC will be a disk of radius |p0| and therefore in order to have stability, all the poles will have to be outside of the unit circle.
The rational transfer function derived in (6.3) can be written out explicitly in terms of the CCDEs coefficients, as follows:
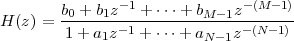 | (6.14) |
The transfer function is the ratio of two polynomials in z-1 where the degree of the numerator polynomial is M - 1 and that of the denominator polynomial is N - 1. As a consequence, the transfer function can be rewritten in factored form as
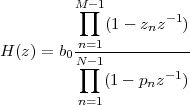 | (6.15) |
where the zn are the M - 1 complex roots of the numerator polynomial and are called the zeros of the system; the pn are the N - 1 complex roots of the denominator polynomial and, as we have seen, they are called the poles of the system. Both poles and zeros can have arbitrary multiplicity. Clearly, if zi = pk for some i and k (i.e. if a pole and a zero coincide) the corresponding first-order factors cancel each other out and the degrees of numerator and denominator are both decreased by one. In general, it is assumed that such factors have already been removed and that the numerator and denominator polynomials of a given rational transfer function are coprime.
The poles and the zeros of a filter are usually represented graphically on the complex plane as crosses and dots, respectively. This allows for a quick visual assessment of stability which, for a causal system, consists of checking whether all the crosses are inside the unit circle (or, for anticausal systems, outside).
The pole-zero plot can exhibit distinctive patterns according to the properties of the filter.
Real-Valued Filters. If the filter coefficients are real-valued (and this is the only case that we consider in this text book) both the numerator and denominator polynomials are going to have real-valued coefficients. We can now recall a fundamental result from complex algebra: the roots of a polynomial with real-valued coefficients are either real or they occur in complex- conjugate pairs. So, if z0 is a complex zero of the system, z0* is a zero as well. Similarly, if p0 is a complex pole, so is p0*. The pole-zero plot will therefore shows a symmetry around the real axis (Fig. 6.2a).
|
|
Linear-Phase FIR Filters. First of all, note that the pole-zero plot for an FIR filter is actually just a zero plot, since FIR’s have no poles.(2) A particularly important case is that of linear phase FIR filters; as we will see in detail in Section 7.2.2, linear phase imposes some symmetry constraints on the CCDE coefficients (which, of course, coincide with the filter taps). These constraints have a remarkable consequence: if z0 is a (complex) zero of the system, 1∕z0 is a zero as well. Since we consider real-valued FIR filters exclusively, the presence of a complex zero in z0 implies the existence of three other zeros, namely in 1∕z0, z0* and 1∕z0* (Fig. 6.2b). See also the discussion in Section 7.2.2
We have seen in Section 5.2.1 that the effect of a cascade of two or more
filters is that of a single filter whose impulse response is the convolution of all
of the filters’ impulse responses. By the convolution theorem, this
means that the overall transfer function of a cascade of K filters
i, i = 1,…,K is simply the product of the single transfer functions
Hi(z):
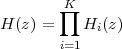
If all filters are realizable, we can consider the factored form of each Hi(z) as in (6.15). In the product of transfer functions, it may happen that some of the poles of a given Hi(z) coincide with the zeros of another transfer function, which leads to a pole-zero cancellation in the overall transfer function. This is a method that can be used (at least theoretically) to stabilize an otherwise unstable filter. If one of the poles of the system (assuming causality) lies outside of the unit circle, this pole can be compensated by cascading an appropriate first- or second-order FIR section to the original filter. In practical realizations, care must be taken to make sure that the cancellation is not jeopardized by numerical precision problems.
The pole-zero plot represents a convenient starting point in order to estimate
the shape of the magnitude for a filter’s transfer function. The basic idea is
to consider the absolute value of H(z), which is a three-dimensional plot
( H(z)
H(z) being a real function of a complex variable). To see what happens to
being a real function of a complex variable). To see what happens to
 H(z)
H(z) it is useful to imagine a “rubber sheet” laid over the complex plane;
then,
it is useful to imagine a “rubber sheet” laid over the complex plane;
then,
so that the shape of  H(z)
H(z) is that of a very lopsided “circus tent”. The
magnitude of the transfer function is just the height of this circus tent
measured around the unit circle.
is that of a very lopsided “circus tent”. The
magnitude of the transfer function is just the height of this circus tent
measured around the unit circle.
In practice, to sketch a transfer function (in magnitude) given the pole-zero plot, we proceed as follows. Let us start by considering the upper half of the unit circle, which maps to the [0,π] interval for the ω axis in the DTFT plot; for real-valued filters, the magnitude response is an even function and, therefore, the [-π,0] interval need not be considered explicitly. Then:
|
|
|
|
As an example, the magnitude responses of the pole-zero plots in Figure 6.2 are displayed in Figures 6.3 and 6.4.
We will quickly revisit the examples of the previous chapter to show the versatility of the z-transform.
|
|
Moving Average. From the impulse response in (5.14), the transfer function of the moving average filter is
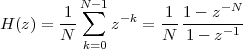 | (6.16) |
from which the frequency response (5.26) is easily derived by setting z = ejω. It is easy to see that the poles of the filter are on all the roots of unity except for z = 1, where the numerator and denominator in (6.17) cancel each other out. A factored representation of the transfer function for the moving average is therefore
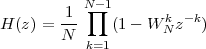 | (6.17) |
and the pole-zero plot (for N = 8) is shown in Figure 6.5(a). There being no poles, the filter is unconditionally stable.
Leaky Integrator. From the CCDE for the leaky integrator (5.16) we immediately have
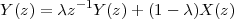 | (6.18) |
from which
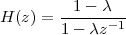 | (6.19) |
The transfer function has therefore a single real pole in z = λ; for a causal realization, this implies that the ROC is the region of the complex plane extending outward from the circle of radius λ. The causal filter is stable if λ lies inside the unit circle, i.e. if λ < 1. An example of pole-zero plot together with the associated ROC is shown in Figure 6.5(b) for the (stable) case of λ = 0.65.
Example 6.1: Transform of periodic functions
The z-transform converges without fuss for infinite-energy sequences which the Fourier transform has some difficulties dealing with. For instance, the z-transform manages to “bring down” the unit step because of the vanishing power of z-n for |z| > 1 and n large and this is the case for all one-sided sequences which grow no more than exponentially. However, if |z-n|→ 0 for n →∞ then necessarily |z-n|→∞ for n →-∞ and this may pose a problem for the convergence of the z-transform in the case of two-sided sequences. In particular, the z-transform does not converge in the case of periodic signals since only one side of the repeating pattern is “brought down” while the other is amplified limitlessly. We can circumvent this impasse by “killing” half of the periodic signal with a unit step. Take for instance the one-sided cosine:
![x[n] = cos(ω0n)u [n]](livre741x.png)
its z-transform can be derived as
| X(z) | = ∑ n=-∞∞z-n cos(ω 0n)u[n] | ||
| = ∑ n=0∞z-n cos(ω 0n) | |||
=  ∑
n=0∞ejω0nz-n + ∑
n=0∞ejω0nz-n +  ∑
n=0∞e-jω0nz-n ∑
n=0∞e-jω0nz-n | |||
=  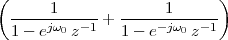 | |||
= 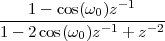 |
Example 6.2: The impossibility of ideal filters
The z-transform of an FIR impulse response can be expressed as a simple polynomial P(z) of degree L - 1 where L is the number of nonzero taps of the filter (we can neglect leading factors of the form z-N). The fundamental theorem of algebra states that such a polynomial has at most L - 1 roots; as a consequence, the frequency response of an FIR filter can never be identically zero over a frequency interval since, if it were, its z-transform would have an infinite number of roots. Similarly, by considering the polynomial P(z) - C, we can prove that the frequency response can never be constant C over an interval which proves the impossibility of achieving ideal (i.e. “brickwall”) responses with an FIR filter. The argument can be easily extended to rational transfer functions, confirming the impossibility of a realizable filter whose characteristic is piecewise perfectly flat.
The z-transform is closely linked to the solution of linear, constant coefficient difference equations. For a more complete treatment, see, for example, R. Vich, Z Transform Theory and Applications (Springer, 1987), or A. J. Jerri, Linear Difference Equations with Discrete Transforms Method (Kluwer, 1996).
Exercise 6.1: Interleaving. Consider two two-sided sequences h[n] and g[n] and consider a third sequence x[n] which is built by interleaving the values of h[n] and g[n]:
| x[n] | = …, h[-3], g[-3], h[-2], g[-2], h[-1], g[-1], h[0], | ||
| g[0], h[1], g[1], h[2], g[2], h[3], g[3], … |
Exercise 6.2: Properties of the z-transform. Let x[n] be a discrete-time sequence and X(z) be its corresponding z-transform with appropriate ROC.
![Z d
nx [n] ←→ - z---X (z)
dz](livre747x.png)
![n Z ----1------
(n+ 1)α u[n ]← → (1 - αz- 1)2 , |z| > |α|](livre748x.png)
Exercise 6.3: Stability. Consider a causal discrete system represented by the following difference equation:
![y[n]- 3.25y[n - 1]+ 0.75 y[n- 2] = x[n- 1]+ 3x [n - 2]](livre749x.png)
Exercise 6.4: Pole-zero plot and stability – I. Consider a causal LTI system with the following transfer function:
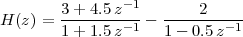
Sketch the pole-zero plot of the transfer function and specify its region of convergence. Is the system stable?
Exercise 6.5: Pole-zero plot and stability – II. Consider the transfer function of an anticausal LTI system
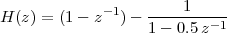
Sketch the pole-zero plot of the transfer function and specify its region of convergence. Is the system stable?
Exercise 6.6: Pole-zero plot and magnitude response. In the following pole-zero plots, multiple zeros at the same location are indicated by the multiplicity number shown to the upper right of the zero. Sketch the magnitude of each frequency response and determine the type of filter.
|
|
Exercise 6.7: z-transform and magnitude response. Consider a causal LTI system described by the following transfer function:
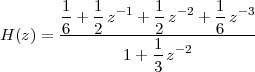
Now fire up your favorite numerical package (or write some C code) and consider the following length-128 input signal:
![{
0 n ∈ [1 ... 50]
x[n ] =
1 n ∈ [51 ... 128]](livre754x.png)
 X[k]
X[k] .
.
 Y [k]
Y [k] .
.
Exercise 6.8: DFT and z-transform. It is immediately obvious that the DTFT of a sequence x[n] is simply its z-transform evaluated on the unit circle, i.e. for z = ejω. Equivalently, for a finite-length signal x, the DFT is simply the z-transform of the finite support extension of the signal evaluated at z = WN-k for k = 0,…,N - 1:
![|
N∑-1 -n|| N∑-1 nk
X [k] = x [n]z || = x[n ]W N
n=0 z=W -Nk n=0](livre759x.png)
By taking advantage of this fact, derive a simple expression for the DFT of the time-reversed signal
![[ T
xr = x[N - 1] x [N - 2] ... x [1] x[0 ]]](livre760x.png)
Exercise 6.9: A CCDE. Consider an LTI system described by the following constant-coefficient difference equation:
![y[n - 1]+ 0.25y[n- 2 ] = x[n]](livre761x.png)
Exercise 6.10: Inverse transform. Write out the discrete-time signal x[n] whose z-transform is
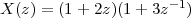
Exercise 6.11: Signal transforms. Consider a discrete-time signal x[n] whose z-transform is
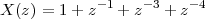
Consider now the length-4 signal y[n]:
![y[n] = x[n], n = 0,1,2,3](livre764x.png)
| © Presses polytechniques et universitaires romandes, 2008 All rights reserved |
In discrete-time signal processing, filter design is the art of turning a set of requirements into a well-defined numerical algorithm. The requirements, or specifications, are usually formulated in terms of the filter’s frequency response; the design problem is solved by finding the appropriate coefficients for a suitable difference equation which implements the filter and by specifying the filter’s architecture. Since realizable filters are described by rational transfer functions, filter design can usually be cast in terms of a polynomial optimization procedure for a given error measure. Additional design choices include the computational cost of the designed filters, i.e. the number of mathematical operations and storage necessary to compute each output sample. Finally, the structure of the difference equation defines an explicit operational procedure for computing the filter’s output values; by arranging the terms of the equation in different ways, we can arrive at different algorithmic structures for the implementation of digital filters.
As we have seen, a realizable filter is described by a rational transfer function; designing a filter corresponds to determining the coefficients of the polynomials in transfer function with respect to the desired filter characteristics. For an FIR filter of length M, there are M coefficients that need to be determined, and they correspond directly to the filter’s impulse response. Similarly, for an IIR filter with a numerator of degree M - 1 and a denominator of degree N - 1, there are M + N - 1 coefficients to determine (since we always assume a0 = 1). The main questions are the following:
As is apparent, real-world filters are designed with a variety of practical requirements in mind, most of which are conflicting. One such requirement, for instance, is to obtain a low “computational price” for the filtering operation; this cost is obviously proportional to the number of coefficients in the filter, but it also depends heavily on the underlying hardware architecture. The tradeoffs between disparate requirements such as cost, precision or numerical stability are very subtle and not altogether obvious; the art of the digital filter designer, although probably less dazzling than the art of the analog filter designer, is to determine the best design strategy for a given practical problem.
Filter design has a long and noble history in the analog domain: a linear electronic network can be described in terms of a differential equation linking, for instance, the voltage as a function of time at the input of the network to the voltage at the output. The arrangement of the capacitors, inductances and resistors in the network determine the form of the differential equation, while their values determine its coefficients. A fundamental difference between an analog filter and a digital filter is that the transformation from input to output is almost always considered instantaneous (i.e. the propagation effects along the circuit are neglected). In digital filters, on the other hand, the delay is always explicit and is actually the fundamental building block in a processing system. Because of the physical properties of capacitors, which are ubiquitous in analog filters, the transfer function of an analog filter (expressed in terms of its Laplace transform) is “similar” to the transfer function of an IIR filter, in the sense that it contains both poles and zeros. In a sense, IIR filters can be considered as the discrete-time counterpart of classic analog filters. FIR filters, on the other hand, are the flagship of digital signal processing; while one could conceive of an analog equivalent to an FIR, its realization would require the use of analog delay lines, which are costly and impractical components to manufacture. In a digital signal processing scenario, on the other hand, the designer can freely choose between two lines of attack with respect to a filtering problem, IIR or FIR, and therefore it is important to highlight advantages and disadvantages of each.
FIR Filters. The main advantages of FIR filters can be summarized as follows:
While their disadvantages are mainly:
IIR Filters. IIR filters are often an afterthought in the context of digital signal processing in the sense that they are designed by mimicking established design procedures in the analog domain; their appeal lies mostly in their compact formulation: for a given computational cost, i.e for a given number of operations per input sample, they can offer a much better magnitude response than an equivalent FIR filter. Furthermore, there are a few fundamental processing tasks (such as DC removal, as we will see later) which are the natural domain of IIR filters. The drawbacks of IIR filters, however, mirror in the negative the advantages of FIR’s. The main advantages of IIR filters can be summarized as follows:
While their disadvantages are mainly:
For these reasons, in this book, we will concentrate mostly on the FIR design problem and we will consider of IIR filters only in conjunction with some specific processing tasks which are often encountered in practice.
A set of filter specifications represents a set of guidelines for the design of a realizable filter. Generally, the specifications are formulated in the frequency domain and are cast in the form of boundaries for the magnitude of the frequency response; less frequently, the specifications will take the phase response into account as well.
A set of filter specifications is best illustrated by example: suppose our goal is to design a half-band lowpass filter, i.e. a lowpass filter with cutoff frequency π∕2. The filter will possess a passband, i.e. a frequency range over which the input signal is unaffected, and a stopband, i.e. a frequency range where the input signal is annihilated. In order to turn these requirements into specifications the following practical issues must be taken into account:
These specifications can be represented graphically as in Figure 7.1; note that, since we are dealing with real-valued filter coefficients, it is sufficient to specify the desired frequency response only over the [0,π] interval, the magnitude response being symmetric. The filter design problem consists now in finding the minimum size FIR or IIR filter which fulfills the required specifications. As an example, Figure 7.2 shows an IIR filter which does not fulfill the specifications since the stopband error is above the maximum error at the beginning of the stopband. Similarly, Figure 7.3 shows an FIR filter which breaks the specifications in the passband. Finally, Figure 7.4 shows a monotonic IIR filter which matches and exceeds the specifications (i.e. the error is always smaller than the maximum error).
In this section we will explore two fundamental strategies for FIR filter design, the window method and the minimax (or Parks-McClellan) method. Both methods seek to minimize the error between a desired (and often ideal) filter transfer function and the transfer function of the designed filter; they differ in the error measure which is used in the minimization. The window method is completely straightforward and it is often used for quick designs. The minimax method, on the other hand, is the procedure of choice for accurate, optimal filters. Both methods will be illustrated with respect to the design of a lowpass filter.
We have already seen in Section 5.6 that if there are no constraints (not even realizability) the best lowpass filter with cutoff frequency ωc is the ideal lowpass. The impulse response is therefore the inverse Fourier transform of the desired transfer function:
![1 ∫ π jω jωn 1 ∫ wc jωn 1 [jω n -jωn] sin(ωcn) ωc (ωc )
h [n] = 2π- H (e )e dω = 2π- e dω = 2πjn-e c - e c = ---πn--- = π--sinc π--n
-π -wc](livre769x.png) |
The resulting filter, as we saw, is an ideal filter and it cannot be represented by a rational transfer function with a finite number of coefficients.
Impulse Response Truncation. A simple idea to obtain a realizable filter is to take a finite number of samples from the ideal impulse response and use them as coefficients of a (possibly rather long) FIR filter:(2)
![{
ˆ h[n] - N ≤ n ≤ N
h[n] = 0 otherwise](livre770x.png) | (7.1) |
This is a (2N + 1)-tap FIR obtained by truncating an ideal impulse response (Figs 5.10 and 5.11). Note that the filter is noncausal, but that it can be made causal by using an N-tap delay; it is usually easier to design FIR’s by considering a noncausal version first, especially if the resulting impulse response is symmetric (or antisymmetric) around n = 0. Although this approximation was derived in a sort of “intuitive” way, it actually satisfies a very precise approximation criterion, namely the minimization of the mean square error (MSE) between the original and approximated filters. Denote by E2 this error, that is
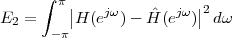
We can apply Parseval’s theorem (see (4.59)) to obtain the equivalent expression in the discrete-time domain:
![∑
E2 = 2 π ||h[n]- ˆh [n]||2
n∈Z](livre772x.png)
If we now recall that ĥ[n] = 0 for |n| > N, we have
![[ ∑N ∑∞ -∑N-1 ]
E = 2π ||h[n]- ˆh[n]||2 + ||h [n]||2 + ||h[n]||2
2 n= -N n=N+1 n=- ∞](livre773x.png)
Obviously the last two terms are nonnegative and independent of ĥ[n]. Therefore, the minimization of E2 with respect to ĥ[n] is equivalent to the minimization of the first term only, and this is easily obtained by letting
![ˆ
h[n ] = h[n], for n = - N,...,N](livre774x.png)
In spite of the attractiveness of such a simple and intuitive solution, there is a major drawback. If we consider the frequency response of the approximated filter, we have
![N
ˆH (ejω) = ∑ h[n]e-jω
n=-N](livre775x.png)
which means that Ĥ(ejω) is an approximation of H(ejω) obtained by using
only 2N + 1 Fourier coefficients. Since H(ejω) has a jump discontinuity in ωc,
Ĥ(ejω) incurs the well-known Gibbs phenomenon around ωc. The Gibbs
phenomenon states that, when approximating a discontinuous function with
a finite number of Fourier coefficients, the maximum error in an interval
around the jump discontinuity is actually independent of the number of
terms in the approximation and is always equal to roughly 9% of the jump.
In other words, we have no control over the maximum error in the magnitude
response. This is apparent in Figure 7.5 where  Ĥ(ejω)
Ĥ(ejω) is plotted for
increasing values of N; the maximum error does not decrease with
increasing N and, therefore, there are no means to meet a set of
specifications which require less than 9% error in either stopband or
passband.
is plotted for
increasing values of N; the maximum error does not decrease with
increasing N and, therefore, there are no means to meet a set of
specifications which require less than 9% error in either stopband or
passband.
|
|
The Rectangular Window. Another way to look at the resulting approximation is to express ĥ[n] as
![ˆh[n] = h [n]w[n]](livre779x.png) | (7.2) |
![( ) {
w[n] = rect n- = 1 - N ≤ n ≤ N
N 0 otherwise](livre780x.png) | (7.3) |
w[n] is called a rectangular window of length (2N + 1) taps, which in this case is centered at n = 0.
We know from the modulation theorem in (5.22) that the Fourier transform of (7.2) is the convolution (in the space of 2π-periodic functions) of the Fourier transforms of h[n] and w[n]:
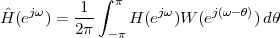
It is easy to compute W(ejω) as
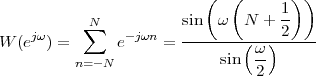 | (7.4) |
An example of W(ejω) for N = 6 is shown in Figure 7.6. By analyzing the form of W(ejω) for arbitrary N, we can determine that:
In order to understand the shape of the approximated filter, let us go back to the lowpass filter example and try to visualize the effect of the convolution in the Fourier transform domain. First of all, since all functions are 2π-periodic, everything happens circularly, i.e. what “goes out” on the right of the [-π,π] interval “pops” immediately up on the left. The value at ω0 of Ĥ(ejω) is the integral of the product between H(ejω) and a version of W(ejω) circularly shifted by ω0. Since H(ejω) is zero except over [-ωc,ωc], where it is one, this value is actually:
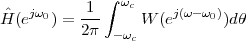
When ω0 is such that the first right sidelobe of W(ejω) is outside of the [-ωc,ωc] interval, then the integral reaches its maximum value, since the sidelobe is negative and it’s the largest. The maximum value is dependent on the shape of the window (a rectangle in this case) but not on its length. Hence the Gibbs phenomenon.
To recap, the windowing operation on the ideal impulse response, i.e. the circular convolution of the ideal frequency response with W(ejω), produces two main effects:
The sharpness of the transition band and the size of the ripples are dependent on the shape of the window’s Fourier transform; indeed, by carefully designing the shape of the windowing sequence we can trade mainlobe width for sidelobe amplitude and obtain a more controlled behavior in the frequency response of the approximation filter (although the maximum error can never be arbitrarily reduced).
Other Windows. In general, the recipe for filter design by windowing involves two steps: the analytical derivation of an ideal impulse response followed by a suitable windowing to obtain an FIR filter. The ideal impulse response h[n] is obtained from the desired frequency response H(ejω) by the usual DTFT inversion formula
![1 ∫ π
h[n ] =--- H (ejω )ejωn dω
2π - π](livre785x.png)
While the analytical evaluation of the above integral may be difficult or impossible in the general case, for frequency responses H(ejω) which are piecewise linear, the computation of h[n] can be carried out in an exact (if nontrivial) way; the result will be a linear combination of modulated sinc and sinc-squared sequences.(3) The FIR approximation is then obtained by applying a finite-length window w[n] to the ideal impulse response as in (7.2). The shape of the window can of course be more sophisticated than the simple rectangular window we have just encountered and, in fact, a hefty body of literature is devoted to the design of the “best” possible window. In general, a window should be designed with the following goals in mind:
It is clear that the first two requirements are openly in conflict; indeed, the width of the main lobe Δ is inversely proportional to the length of the window (we have seen, for instance, that for the rectangular window Δ = 4π∕M, with M, the length of the filter). The second and third requirements are also in conflict, although the relationship between mainlobe width and sidelobe amplitude is not straightforward and can be considered a design parameter. In the frequency response, reduction of the sidelobe amplitude implies that the Gibbs phenomenon is decreased, but at the “price” of an enlargement of the filter’s transition band. While a rigorous proof of this fact is beyond the scope of this book, consider the simple example of a triangular window (with N odd):
![(
{ N----n |n| < N
wt[n] = w [n] = N
( 0 otherwise](livre786x.png) | (7.5) |
It is easy to verify that wt[n] = w[n] * w[n], with w[n] = rect 2n∕(N - 1)
2n∕(N - 1) (i.e. the triangle can be obtained as the convolution of a half-support
rectangle with itself) so that, as a consequence of the convolution theorem,
we have
(i.e. the triangle can be obtained as the convolution of a half-support
rectangle with itself) so that, as a consequence of the convolution theorem,
we have
![[ ]2
Wt (ejω ) = W (ejω)W (ejω) = sin(ωN-∕2)-
sin(ω∕2 )](livre789x.png) | (7.6) |
The net result is that the amplitude of the sidelobes is quadratically reduced but the amplitude of the mainlobe Δ is roughly doubled with respect to an equivalent-length rectangular window; this is displayed in Figure 7.7 for a 17-point window (values are normalized so that both frequency responses are equal in ω = 0). Filters designed with a triangular window therefore exhibit a much wider transition band.
|
|
Other commonly used windows admit a simple parametric closed form representation; the most important are the Hamming window (Fig. 7.8):
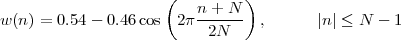
and the Blackman window (Fig. 7.9):
| w(n) | = 0.42 - 0.5cos + 0.08cos + 0.08cos , |n|≤ N - 1 , |n|≤ N - 1 |
|
|
Limitations of the Window Method. Lack of total control on passband
and stopband error is the main limitation inherent to the window method;
this said, the method remains a fundamental staple of practical signal
processing as it yields perfectly usable filters via a quick, flexible and simple
procedure. The error characteristic of a window-designed filter can be
particularly aggravating in sensitive applications such as audio processing,
where the peak in the stopband error can introduce unacceptable artifacts.
In order to improve on the filter performance, we need to completely revise
our design approach. A more suitable optimization criterion may, for
instance, be the minimax criterion, where we aim to explicitly minimize the
maximum approximation error over the entire frequency support; this is
thoroughly analyzed in the next section. We can already say, however, that
while the minimum square error is an integral criterion, the minimax is a
pointwise criterion; or, mathematically, that the MSE and the minimax are
respectively L2 [-π,π]
[-π,π] - and L∞
- and L∞ [-π,π]
[-π,π] -norm minimizations for the
error function E(ω) = Ĥ(ejω) - H(ejω). Figure 7.11 illustrates the
typical result of applying both criteria to the ideal lowpass problem. As
can be seen, the minimum square and minimax solutions are very
different.
-norm minimizations for the
error function E(ω) = Ĥ(ejω) - H(ejω). Figure 7.11 illustrates the
typical result of applying both criteria to the ideal lowpass problem. As
can be seen, the minimum square and minimax solutions are very
different.
As we saw in the opening example, FIR filter design by windowing minimizes the overall mean square error between the desired frequency response and the actual response of the filter. Since this might lead to a very large error at frequencies near the transition band, we now consider a different approach, namely the design by minimax optimization. This technique minimizes the maximum allowable error in the filter’s magnitude response, both in the passband and in the stopband. Optimality in the minimax sense requires therefore the explicit stating of a set of tolerances in the prototypical frequency response, in the form of design specifications as seen in Section 7.1.2. Before tackling the design procedure itself, we will need a series of intermediate results.
Generalized Linear Phase. In Section 5.4.3, we introduced the concept of linear phase; a filter with linear phase response is particularly desirable since the phase response translates to just a time delay (possibly fractional) and we can concentrate on the magnitude response only. We also introduced the notion of group delay and showed that linear phase corresponds to constant group delay. Clearly, the converse is not true: a frequency response of the type
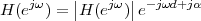
has constant group delay but differs from a linear phase system by a constant phase factor ejα. We will call this type of phase response generalized linear phase. Important cases are those for which α = 0 (strictly linear phase) and α = π∕2 (generalized linear phase used in differentiators).
FIR Filter Types. Consider a causal, M-tap FIR filter with impulse response h[n], n = 0,1,…,M - 1; in the following, we are interested in filters whose impulse response is symmetric or antisymmetric around the “midpoint”. If the number of taps is odd, the midpoint of the impulse response coincides with the center tap h[(M - 1)∕2]; if the number of taps is even, on the other hand, the midpoint is still at (M - 1)∕2 but this value does not coincide with a tap since it is located “right in between” taps h[M∕2 - 1] and h[M∕2]. Symmetric and antisymmetric FIR filters are important since their frequency response has generalized linear phase. The delay introduced by these filters is equal to (M - 1)∕2 samples; clearly, this is an integer delay if M is odd, and it is fractional (half a sample more) if M is even. There are four different possibilities for linear phase FIR impulse responses, which are listed here with their corresponding generalized linear phase parameters :
|
The generalized linear phase of (anti)symmetric FIRs is easily shown. Consider for instance a Type I filter, and define C = (M - 1)∕2, the location of the center tap; we can compute the transfer function of the shifted impulse response hd[n] = h[n + C], which is now symmetric around zero, i.e. hd[-n] = hd[n]:
![C -1 C C
H (z) = ∑ h [n ]z-n = h [0]+ ∑ h [n]z-n+ ∑ h [n]z-n = h [0]+ ∑ h [n](zn+z -n)
d d d d d d d
n= -C n= -C n=1 n=1](livre804x.png) | (7.7) |
By undoing the time shift we obtain the original Type I transfer function:
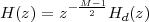 | (7.8) |
On the unit circle (7.7) becomes
![∑C ∑C
Hd (ejω) = hd[0]+ hd[n ](ejωn + e- jωn) = hd[0]+ 2 hd[n ]cosnω
n=1 n=1](livre806x.png) | (7.9) |
which is a real function; the original Type I frequency response is obtained from (7.8):
![⌊ ⌋
[ ] M∑-1
H (ejω) = ⌈h M----1 + 2 h[n]cosnω ⌉ e-jωM-21-
2 n=(M+1 )∕2](livre807x.png)
which is clearly linear phase with delay d = (M - 1)∕2 and α = 0. The generalized linear phase of the other three FIR types can be shown in exactly the same way.
Zero Locations. The symmetric structures of the four types of FIR filters impose some constraints on the locations of the zeros of the transfer function. Consider again a Type I filter; from (7.7) it is easy to see that Hd(z-1) = Hd(z); by using (7.8) we therefore have
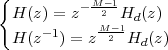
which leads to
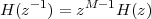 | (7.10) |
It is easy to show that the above relation is also valid for Type II filters, while for Type III and Type IV (antisymmetric filters) we have
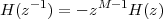 | (7.11) |
These relations mean that if z0 is a zero of a linear phase FIR, then so is z0-1. This result, coupled with the usual fact that all complex zeros come in conjugate pairs, implies that if z0 is a zero of H(z), then:
R then ρ and 1∕ρ are zeros.
Consider now equation (7.10) again; if we set z = -1,
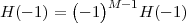 | (7.12) |
for Type II filters, M - 1 is an odd number, which leads to the conclusion that H(-1) = 0; in other words, Type II filters must have a zero at ω = π. Similar results can be demonstrated for the other filter types, and they are summarized below:
|
These constraints are important in the choice of the filter type for a given set of specifications. Type II and Type III filters are not suitable in the design of highpass filters, for instance; similarly, Type III and Type IV filters are not suitable in in the design of lowpass filters.
Chebyshev Polynomials. Chebyshev polynomials are a family of
orthogonal polynomials  Tk(x)
Tk(x) kN which have, amongst others, the
following interesting property:
kN which have, amongst others, the
following interesting property:
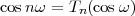 | (7.13) |
in other words, the cosine of an integer multiple of an angle ω can be expressed as a polynomial in the variable cosω. The first few Chebyshev polynomials are
| T0(x) | = 1 | ||
| T1(x) | = x | ||
| T2(x) | = 2x2 - 1 | ||
| T3(x) | = 4x3 - 3x | ||
| T4(x) | = 8x4 - 8x2 + 1 |
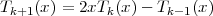 | (7.14) |
From the above table it is easy to see that we can write, for instance,
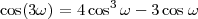
The interest in Chebyshev polynomials comes from the fact that the zero-centered frequency response of a linear phase FIR can be expressed as a linear combination of cosine functions, as we have seen in detail for Type I filters in (7.9). By using Chebyshev polynomials we can rewrite such a response as just one big polynomial in the variable cosω. Let us consider an explicit example for a length-7 Type I filter with nonzero coefficients h[n] = [d c b a b c d]; we can state that
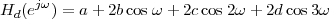
and by using the first four Chebyshev polynomials we can write
| Hd(ejω) | = a + 2bcosω + 2c(2cos2ω - 1) + 2d(4cos3ω - 3cosω) | ||
| = (a - 2c) + (2b - 6d)cosω + 4ccos2ω + 8dcos3ω | (7.15) |
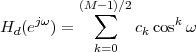 | (7.16) |
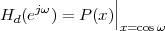 | (7.17) |
where P(x) is a polynomial of degree (M - 1)∕2 whose coefficients ck are derived as linear combinations of the original filter coefficients ak as illustrated in (7.15). For the other types of linear phase FIR, a similar representation can be obtained after a few trigonometric manipulations. The general expression is
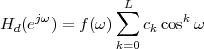 | (7.18) |
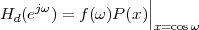 | (7.19) |
where the ck are still linear combinations of the original filter coefficients and where f(ω) is a weighting trigonometric function. Both f(ω) and the polynomial degree K vary as a function of the filter type.(4) In the following Sections, however, we will concentrate only on the design of Type I filters, so these details will be overlooked; in practice, since the design is always carried out using numerical packages, the appropriate formulation for the filter expression is taken care of automatically.
Polynomial Optimization. Going back to the filter design problem, we stipulate that the FIR filters are (generalized) linear phase, so we can concentrate on the real frequency response of the zero-centered filter, which is represented by the trigonometric polynomial (7.19). Moreover, since the impulse response is real and symmetric, the aforementioned real frequency response is also symmetric around ω = 0. The filter design procedure can thus be carried out only for values of ω over the interval [0,π], with the other half of the spectrum obtained by symmetry. For these values of ω, the variable x = cosω is mapped onto the interval [1,-1] and the mapping is invertible. Therefore, the filter design problem becomes a problem of polynomial approximation over intervals.
To illustrate the procedure by example, consider once more the set of filter specifications in Figure 7.1 and suppose we decide to use a Type I filter. Recall that we required the prototype filter to be lowpass, with a transition band from ωp = 0.4π to ωs = 0.6π; we further stated that the tolerances for the realized filter’s magnitude must not exceed 10% in the passband and 1% in the stopband. This implies that the maximum magnitude error between the prototype filter and the FIR filter response H(ejω) must not exceed δp = 0.1 in the interval [0,ωp] and must not exceed δs = 0.01 in the interval [ωs,π]. We can formulate this as follows: the frequency response of the desired filter is
![{
jω 1 ω ∈ [0,ωp]
HD (e ) =
0 ω ∈ [ωs,π]](livre822x.png) |
(note that HD(ejω) is not specified in the transition band). Since the tolerances on passband and stopband are different, they can be expressed in terms of a weighting function HW (ω) such that the tolerance on the error is constant over the two bands:
![(
{ 1 ω ∈ [0,ωp]
HW (ω) = ( δp
δs = 10 ω ∈ [ωs,π]](livre823x.png) | (7.20) |
With this notation, the filter specifications amount to the following:
![{ | jω jω |}
ω∈[0m,ωax]∪[ω ,π] HW (ω )|Hd (e )- HD (e )| ≤ δp = 0.1
p s](livre824x.png) | (7.21) |
and the question now is to find the coefficients for h[n] (their number M and their values) which minimize the above error. Note that we leave the transition band unconstrained (i.e. it does not affect the minimization of the error).
The next step is to use (7.19) to reformulate the above expression as a polynomial optimization problem. To do so, we replace the frequency response Hd(ejω) with its polynomial equivalent and set x = cosω; the passband interval [0,ωp] and the stopband interval [ωs,π] are mapped into the intervals for x:
| Ip | = [cosωp,1] | ||
| Is | = [-1,cosωs] |
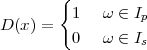 | (7.22) |
and the weighting function becomes:
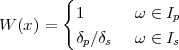 | (7.23) |
The new set of specifications are shown in Figure 7.12. Within this polynomial formulation, the optimization problem becomes:
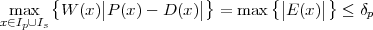 | (7.24) |
where P(x) is the polynomial representation of the FIR frequency response as in (7.19).
|
|
Alternation Theorem. The optimization problem stated by (7.24) can be solved by using the following theorem:
Theorem 7.1 Consider a set {Ik} of closed, disjoint intervals on the real axis and their union I = ⋃ kIk. Consider further:
Consider now the approximation error function
![E (x) = W (x )[D (x)- P (x)]](livre829x.png)
and the associated maximum approximation error over the set of closed intervals
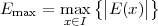
Then P(x) is the unique order-L polynomial which minimizes Emax if
and only if there exist at least L + 2 successive values xi in I such that
 E(xi)
E(xi) = Emax and
= Emax and
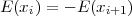
In other words, the error function must have at least L + 2 alternations between its maximum and minimum values. Such a function is called equiripple.
Going back to our lowpass filter example, assume we are trying to design a 9-tap optimal filter. This theorem tells us that if we found a polynomial P(x) of degree 4 such that the error function (7.24) over Ip and Is as is shown in Figure 7.13 (6 alternations), then the polynomial would be the optimal and unique solution. Note that the extremal points (i.e. the values of the error function at the edges of the optimization intervals) do count in the number of alternations since the intervals Ik are closed.
|
|
The above theorem may seem a bit far-fetched since it does not tell us how to find the coefficients but it only gives us a test to verify their optimality. This test, however, is at the core of an iterative algorithm which refines the polynomial from an initial guess to the point when the optimality condition is met. Before considering the optimization procedure more in detail, we will state without formal proof, three consequences of the alternation theorem as it applies to the design of Type I lowpass filters:
Optimization Procedure. Finally, by putting all the elements together, we are ready to state an algorithmic optimization procedure for the design of optimal minimax FIR filters; this procedure is usually called the Parks-McClellan algorithm. Remember, we are trying to determine a polynomial P(x) such that the approximation error in (7.24) is equiripple; for this, we need to determine both the degree of the polynomial and its coefficients. For a given degree L, for which the resulting filter has 2L + 1 taps, the L coefficients are found by an iterative procedure which successively refines an initial guess for the L + 2 alternation points xi until the error is equiripple.(5) After the iteration has converged, we need to check that the corresponding Emax satisfies the upper bound imposed by the specifications; when this is not the case, the degree of the polynomial (and therefore the length of the filter) must be increased and the procedure must be restarted. Once the conditions on the error are satisfied, the filter coefficients can be obtained by inverting the Chebyshev expansion.
As a final note, an initial guess for the number of taps can be obtained using the empirical formula by Kaiser; for an M-tap FIR h[n], n = 0,…, M - 1:
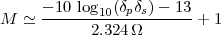
where δp is the passband tolerance, δs is the stopband tolerance and Ω = ωs - ωp is the width of the transition band.
The Final Design. We now summarize the design steps for the specifications in Figure 7.1. We use a Type I FIR. We start by using Kaiser’s formula to obtain an estimate of the number of taps: since δpδs = 10-3 and Ω = 0.2π, we obtain M = 12.6 which we round up to 13 taps. At this point we can use any numerical package for filter design to run the Parks-McClellan algorithm. In Matlab this would be
![[h, err] = remez(12, [0 0.4 0.6 1], [1 1 0 0], [1 10]);](livre836x.png)
The resulting frequency response is plotted in Figure 7.14; please note that we are plotting the frequency responses of the zero-centered filter hd[n], which is a real function of ω. We can verify that the filter has indeed (M - 1)∕2 = 6 alternation by looking at enlarged picture of the passband and the stopband, as in Figure 7.15.
|
|
The maximum error as returned by Matlab is however 0.102 which is larger than what our specifications called for, i.e. 0.1. We are thus forced to increase the number of taps; since we are using a Type I filter, the next choice is M = 15. Again, the error turns out to be larger than 0.1, since in this case we have Emax = 0.1006. The next choice, M = 17, finally yields an error Emax = 0.05, which exceeds the specifications by a factor of 2. It is the designer’s choice to decide whether the computational gains of a shorter filter (M = 15) outweigh the small excess error. The impulse response and the frequency response of the 17-tap filter are plotted in Figure 7.16 and Figure 7.17. Figure 7.18 shows the zero locations for the filter; note the typical linear-phase zero pattern as well as the zeros on the unit circle in the stopband.
Other Types of Filters. The Parks-McClellan optimal FIR design procedure can be made to work for arbitrary filter types as well, such as highpass and bandpass, but also for more sophisticated frequency responses. The constraints imposed by the zero locations as we saw on page § determine the type of filter to use; once the desired response HD(ejω) is expressed as a trigonometric function, the optimization algorithm can take its course. For arbitrary frequency responses, however, the fact that the transition bands are left unconstrained may lead to unacceptable peaks which render the filter useless. In these cases, visual inspection of the obtained response is mandatory and experimentation with different filter lengths and tolerance may improve the final result.
|
|
As we mentioned earlier, no optimal procedure exists for the design of IIR filters. The fundamental reason is that the optimization of the coefficients of a rational transfer function is a highly nonlinear problem and no satisfactory algorithm has yet been developed for the task. This, coupled with the impossibility of obtaining an IIR with linear phase response(6) makes the design of the IIR filter a much less formalized art. Many IIR designed techniques are described in the literature and their origin is usually in tried-and- true analog filter design methods. In the early days of digital signal processing, engineers would own voluminous books with exhaustive lists of capacitance and inductance values to be used for a given set of (analog) filter specifications. The idea behind most digital IIR filter design techniques was to be able to make use of that body of knowledge and to devise formulas which would translate the analog design into a digital one. The most common such method is known as bilinear transformation. Today, the formal step through an analog prototype has become unnecessary and numerical tools such as Matlab can provide a variety of routines to design an IIR.
Here we concentrate only on some basic IIR filters which are very simple and which are commonly used in practice.
There are a few applications in which simple IIR structures are the design of choice. These filters are so simple and so well behaved that they are a fundamental tool in the arsenal of any signal processing engineer.
DC Removal and Mean Estimation. The DC component of a signal is its mean value; a signal with zero mean is also called an AC signal. This nomenclature comes from electrical circuit parlance: DC is shorthand for direct current, while AC stands for alternating current;(7) you might be familiar with these terms in relation to the current provided by a battery (constant and hence DC) and the current available from a mains socket (alternating at 50 or 60 Hz and therefore AC).
For a given sequence x[n], one can always write
![x[n ] = xAC [n]+ xDC](livre842x.png)
where xDC is the mean of the sequence values. Please note the followings:
In most signal processing applications, where the input signal comes from an acquisition device (such as a sampler, a soundcard and so on), it is important to remove the DC component; this is because the DC offset is often a random offset caused by ground mismatches between the acquisition device and the associated hardware. In order to eliminate the DC component we need to first estimate it, i.e. we need to estimate the mean of the signal.
For finite-length signals, computation of the mean is straightforward since it involves a finite number of operations. In most cases, however, we do not want to wait until the end of the signal before we try to remove its mean; what we need is a way to perform DC removal on line. The approach is therefore to obtain, at each instant, an estimate of the DC component from the past signal values, with the assumption that the estimate converges to the real mean of the signal. In order to obtain such an estimate, i.e. in order to obtain the average value of the past input samples, both approaches detailed in Section 5.3 are of course valid (i.e. the Moving Average and the Leaky Integrator filters) . We have seen, however, that the leaky integrator provides a superior cost/benefit tradeoff and therefore the output of a leaky integrator with λ very close to one (usually 10-3) is the estimate of choice for the DC component of a signal. The closer λ is to one, the more accurate the estimation; the speed of convergence of the estimate however becomes slower and slower as λ → 1. This can easily be seen from the group delay at ω = 0, which is
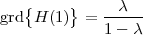
Resonator Filter. Let us look again at how the leaky integrator works. Consider its z-transform:
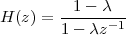
and notice that what we really want the filter to do is to extract the zero-frequency component (i.e. the frequency component that does not oscillate, that is, the DC component). To do so, we placed a pole near z = 1, which of course corresponds to z = ejω for ω = 0. Since the magnitude response of the filter exhibits a peak near a pole, and since the peak will be higher, the closer the pole is to the unit circle, we are in fact amplifying the zero-frequency component; this is apparent from the plot of the filter’s frequency response in Figure 5.9. The numerator, 1 - λ, is chosen such that the magnitude of the filter at ω = 0 is one; the net result is that the zero-frequency component will pass unmodified while all the other frequencies will be attenuated. The value of a filter’s magnitude at a given frequency is often called the gain.
The very same approach can now be used to extract a signal component at any frequency. We will use a pole whose magnitude is still close to one (i.e. a pole near the unit circle) but whose phase is that of the frequency we want to extract. We will then choose a numerator so that the magnitude is unity at the frequency of interest. The one extra detail is that, since we want a real-valued filter, we must place a complex conjugate pole as well. The resulting filter is called a resonator and a typical pole-zero plot is shown in Figure 7.19. The z-transform of a resonator at frequency ω0 is therefore determined by the pole p = λejω0 and by its conjugate:
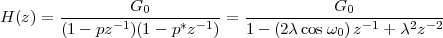 | (7.25) |
The numerator value G0 is computed so that the filter’s gain at ±ω0 is one;
since in this case  H(ejω0)
H(ejω0) =
=  H(e-jω0)
H(e-jω0) , we have
, we have
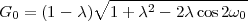
The magnitude and phase of a resonator with λ = 0.9 and ω0 = π∕3 are shown in Figure 7.20.
A simple variant on the basic resonator can be obtained by considering the fact that the resonator is just a bandpass filter with a very narrow passband. As for all bandpass filters, we can therefore place a zero at z = ±1 and sharpen its midband frequency response. The corresponding z-transform is now
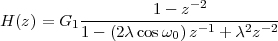
with
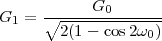
The corresponding magnitude response is shown in Figure 7.21.
We have seen in Section 5.7.2 a practical implementation of a constant-coefficient difference equation (written in C). That was just one particular way of translating Equation (5.46) into a numerical procedure; in this Section we explore other alternatives for both FIR and IIR and introduce the concept of computational efficiency for filters.
The cost of a numerical filter is dependent on the number of operations per output sample and on the storage (memory) required in the implementation. If we consider a generic CCDE, it is easy to see that the basic building blocks which make up the recipe for a realizable filter are:
By properly combining these elements and by exploiting the different possible decomposition of a filter’s rational transfer function, we can arrive at a variety of different working implementations of a filter. To study the possibilities at hand, instead of relying on a specific programming language, we will use self explanatory block diagrams.
Cascade Forms. Recall that a rational transfer function H(z) can always be written out as follows:
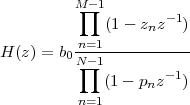 | (7.26) |
where the zn are the M - 1 (complex) roots of the numerator polynomial and the pn are the N - 1 (complex) roots of the denominator polynomial. Since the coefficients of the CCDE are assumed to be real, complex roots for both polynomials always appear in complex-conjugate pairs. A pair of first-order terms with complex-conjugate roots can be combined into a second-order term with real coefficients:
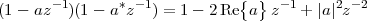 | (7.27) |
As a consequence, the transfer function can be factored into the product of first- and second-order terms in which the coefficients are all strictly real; namely:
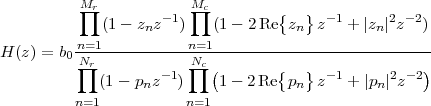 | (7.28) |
where Mr is the number of real zeros, Mc is the number of complex-conjugate zeros and Mr + 2Mc = M (and, equivalently, for the poles, Nr + 2Nc = N). From this representation of the transfer function we can obtain an alternative structure for a filter; recall that if we apply a series of filters in sequence, the overall transfer function is the product of the single transfer functions. Working backwards, we can interpret (7.28) as the cascade of smaller sections. The resulting structure is called a cascade and it is particularly important for IIR filters, as we will see later.
Parallel Forms. Another interesting rewrite of the transfer function is based on a partial fraction expansion of the type:
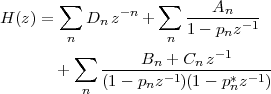 | (7.29) |
where the multiplicity of the three types of terms as well as the relative coefficients are dependent (in a non-trivial way) on the original filter coefficients. This generates a parallel structure of filters, whose outputs are summed together. The first branch corresponds to the first sum and it is an FIR filter; a further set of branches are associated to each term in the second sum, each one of them a first order IIR; the last set of branches is a collection of second order sections, one for each term of the third sum.
In an FIR transfer function all the denominator coefficients an other than a0 are zero; we have therefore:
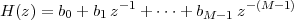
where, of course, the coefficients correspond to the nonzero values of the impulse response h[n], i.e. bn = h[n]. Using the constitutive elements outlined above, we can immediately draw a block diagram of an FIR filter as in Figure 7.22. In practice, however, additions are distributed as shown in Figure 7.23; this kind of implementation is called a transversal filter. Further, ad-hoc optimizations for FIR structures can be obtained in the the case of symmetric and antisymmetric linear phase filters; these are considered in the exercises.
For an IIR filter, all the an and bn in (5.46) are nonzero. One possible implementation based on the direct form of the transfer function is given in Figure 7.24. This implementation is called Direct Form I and it can immediately be seen that the C-code implementation in Section 5.7.2 realizes a Direct Form I algorithm. Here, for simplicity, we have assumed N = M but obviously we can set some an or bn to zero if this is not the case.
By the commutative properties of the z-transform, we can invert the order of computation to turn the Direct Form I structure into the structure shown in Figure 7.25 (shown for a second order section); we can then combine the parallel delays together to obtain the structure in Figure 7.26. This implementation is called Direct Form II; its obvious advantage is the reduced number of the required delay elements (hence of memory storage).
The second order filter
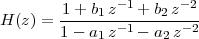
which gives rise to the second order section displayed in Figure 7.26, is particularly important in the case of cascade realizations. Consider the factored form of H(z) as in (7.28): if we combine the complex conjugate poles and zeros, and group the real poles and zeros in pairs, we can create a modular structure composed of second order sections. For instance, Figure 7.27 represents a 4th order system. Odd order systems can be obtained by setting some of the an or bn to zero.
A very important issue with digital filters is their numerical behavior for a given implementation. Two key questions are:
One important difference is that, in the first case, the system is at least guaranteed to be linear; in the second case, however, we can have non-linear effects such as overflows and limit cycles.
Precision and computational issues are very hard to analyze. Here, we will just note that the direct form implementation is more sensible to precision errors than the cascade form, which is why the cascade form is usually preferred in practice. Moreover, alternative filter structures such as the lattice are designed to provide robustness for systems with low numerical precision, albeit at a higher computational cost.
The filtering structures that we have shown up to now are general-purpose architectures which apply to the most general class of discrete-time signals, (infinite) sequences. We now consider the other two main classes of discrete-time signals, namely finite-length signals and periodic sequences, and show that specialized filtering algorithms can be advantageously put to use.
The convolution sum in (5.3) is defined for infinite sequences. For a finite-length signal of length N we may choose to write simply:
![N- 1
y[n] = H {x [n]} = ∑ x[k]h [n - k]
k=0](livre870x.png) | (7.30) |
i.e. we let the summation index span only the indices for which the
signal is defined. It can immediately be seen, however, that in so
doing we are actually computing y[n] =  [n] * h[n], where
[n] * h[n], where  [n] is the
finite support extension of x[n] as in (2.24)); that is, by using (7.30),
we are implicitly assuming a finite support extension for the input
signal.
[n] is the
finite support extension of x[n] as in (2.24)); that is, by using (7.30),
we are implicitly assuming a finite support extension for the input
signal.
Even when the input is finite-length, the output of an LTI system is not necessarily a finite-support sequence. When the impulse response is FIR, however, the output has finite support; specifically, if the input sequence has support N and the impulse response has support L, the support of the output is N + L - 1.
For periodic sequences, the convolution sum in (5.3) is well defined so there
is no special care to be taken. It is easy to see that, for any LTI system, an
N-periodic input produces an N-periodic output. A case of particular
interest is the following: consider a length-N signal x[n] and its N-periodic
extension 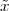 [n]. Consider then a filter whose impulse response is FIR with a
length-N support; if we call h[n] the length-N signal obtained by considering
only the values of the impulse response over its finite support, the
impulse response of the filter is
[n]. Consider then a filter whose impulse response is FIR with a
length-N support; if we call h[n] the length-N signal obtained by considering
only the values of the impulse response over its finite support, the
impulse response of the filter is 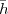 [n] (see (2.24)). In this case we can
write
[n] (see (2.24)). In this case we can
write
![∞∑ N∑-1 [ ]
y˜[n] = ˜x[k]¯h[n - k] = h[k ]˜x (n - k) mod N
k=-∞ k=0](livre875x.png) | (7.31) |
Note that in the last sum, only the first period of 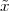 [n] is used; we can
therefore define the sum just in terms of the two N-point signals x[n] and
h[n]:
[n] is used; we can
therefore define the sum just in terms of the two N-point signals x[n] and
h[n]:
![N∑-1
˜y[n] = h[k]x[(n- k) mod N ]
k=0](livre877x.png) | (7.32) |
The above summation is called the circular convolution of x[n] and h[n] and is sometimes indicated as
![˜y[n] = x[n]⊛ h [n]](livre878x.png)
Note that, for periodic sequences, the convolution as defined in (5.8) and the circular convolution coincide. The circular convolution, just like the standard convolution operator, is associative and commutative:
| x[n] ⊛ h[n] = h[n] ⊛ x[n] | |||
 h[n] + f[n] h[n] + f[n] ⊛ x[n] = h[n] ⊛ x[n] + f[n] ⊛ x[n] ⊛ x[n] = h[n] ⊛ x[n] + f[n] ⊛ x[n] |
Consider now the output of the filter, expressed using the commutative property of the circular convolution:
![N∑-1
˜y[n] = x [k]h[(n - k) mod N ]
k=0](livre881x.png)
Since the output sequence ỹ[n] is itself N-periodic we can consider the finite-length signal y[n] = ỹ[n], n = 0,…,N - 1, i.e. the first period of the output sequence. The circular convolution can now be expressed in matrix form as
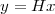 | (7.33) |
where y,x are the usual vector notation for the finite-length signals y[n],x[n] and where
![⌊ ⌋
| h[0] h[N - 1] h[N - 2] ... h[2 ] h[1]|
| h[1] h[0] h[N - 1] ... h[3 ] h[2]|
H = || . . . . . . ||
|⌈ .. .. .. .. .. .. |⌉
h[N - 1] h[N - 2] h[N - 3] ... h[1 ] h[0]](livre883x.png) | (7.34) |
The above matrix is called a circulant matrix, since each row is obtained by a right circular shift of the previous row. A fundamental result, whose proof is left as an exercise, is that the length-N DFT basis vectors w(k) defined in (4.3) are left eigenvectors of N × N circulant matrices:
![( )
w (k) TH = H [k]w(k)](livre884x.png)
where H[k] is the k-th DFT coefficient of the length-N signal h[n], n = 0,…,N - 1. If we now take the DFT of (7.33) then
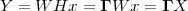
with
![Γ = diag(H [0],H [1],...,H[N - 1])](livre886x.png)
or, in other words
![Y [k] = H [k]X [k]](livre887x.png) | (7.35) |
We have just proven a finite-length version of the convolution theorem; to repeat the main points:
The importance of this particular case of filtering stems from the following fact: the matrix-vector product in (7.33) requires O(N2) operations. The same product can however be written as
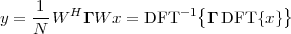
which, by using the FFT algorithm, requires approximately N + 2N log 2N operations and is therefore much more efficient even for moderate values of N. Practical applications of this idea are the overlap-save and overlap-add filtering methods, for a thorough description of which see [?]. The basic idea is that, in order to filter a long input sequence with an N-tap FIR filter, the input is broken into consecutive length-N pieces and each piece, considered as the main period of a periodic sequence, is filtered using the FFT strategy above. The difference between the two methods is in the subtle technicalities which allow the output pieces to bind together in order to give the correct final result.
Finally, we want to show that we could have quickly arrived at the same results just by considering the formal DTFTs of the sequences involved; this is an instance of the power of the DTFT formalism. From (4.43) and (4.44) we obtain:
| Y (ejω) | =  (ejω) (ejω) (ejω) (ejω) | ||
= ![(N -1 ( ))
∑ 2π-
H[k]Λ ω - N k
k=0](livre891x.png) ![( N- 1 ( ) )
-1 ∑ ˜ 2π-
N X [k]δ ω - N k
k=0](livre892x.png) | |||
= 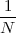 ∑
k=0N-1H[k]X[k] ∑
k=0N-1H[k]X[k]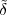 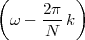 | (7.36) |
Example 7.1: The Goertzel filter
Consider the IIR structure shown in Figure 7.28; the filter is called a Goertzel filter, and its single coefficient (which is also the only pole of the system) is the k-th power of the N-th root of unity WN = e-j2π∕N. Note that, contrary to what we have seen so far, this is a complex-valued filter; the analysis of this type of structure however is identical to that of a normal real-valued scheme.
As we said, the only pole of the filter is on the unit circle, so the system is not stable. We can nevertheless compute its impulse response, a task which is trivial in the case of a one-pole IIR; we assume zero initial conditions and we use the difference equation directly: by setting x[n] = δ[n] in
![- k
y[n ] = x[n]+ W N y[n- 1 ]](livre896x.png)
and by working out the first few iterations, we obtain
![-kn
h[n] = W N u[n]](livre897x.png)
Note that the impulse response is N-periodic (a common trait of sequences whose poles are on the unit circle).
Assume now we have a length-N signal x[n] and we build a finite-support
extension 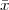 [n] so that
[n] so that 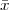 [n] = 0 for n < 0, n ≥ N and
[n] = 0 for n < 0, n ≥ N and 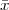 [n] = x[n] otherwise. If
we process such a signal with the Goertzel filter we have
[n] = x[n] otherwise. If
we process such a signal with the Goertzel filter we have
| y[0] | = x[0] | ||
| y[1] | = x[1] + WN-k x[0] | ||
| y[2] | = x[2] + WN-k x[1] + W N-2k x[0] | ||
| y[3] | = x[3] + WN-k x[2] + W N-2k x[1] + W N-3k x[0] | ||
 |
![N∑- 1 N∑- 1
y[N] = W -Nk(N-n)x [n ] = x[n]W nNk= X [k]
n=0 n=0](livre903x.png)
that is, the output at time n = N is the k-th DFT coefficient of x[n]. The Goertzel filter is therefore a little machine which allows us to obtain one specific Fourier coefficient without needing to compute the whole DFT. As a filter, its usage is nonstandard, since its delay element must be manually reset to zero initial conditions after each group of N iterations. Goertzel algorithm is used in digital detectors of DTMF tones.
Example 7.2: Filtering and numerical precision
Digital filters are implemented on general-purpose microprocessors; the precision of the arithmetics involved in computing the output values depends on the intrinsic word length in the digital architecture, i.e. in the number of bits used to represent both the data and the filter coefficients. To illustrate some of the issues related to numeric precision consider the case of an allpass filter. The magnitude response of an allpass filter is constant over the entire [-π,π] interval, hence the name. Such filters are often used in cascade with other filters to gain control on the overall phase response of the system.
Consider the filter described by the following difference equation:
![y[n] = αy [n - 1]- αx [n ]+ x[n - 1]](livre904x.png)
with 0 < α < 1. The transfer function H(z) is
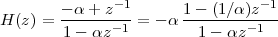
and the filter is indeed allpass since:
 H(z) H(z) 2 2 | = H(z)H*(z) | ||
= 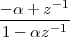 ⋅ ⋅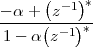 | |||
= 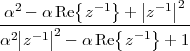 |
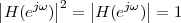
The filter can be implemented in Direct Form II as in Figure 7.29. Note that
the two coefficients of the filter are α and 1∕α so that, if α is small then 1∕α
will be big, and vice versa. This creates a problem in a digital architecture in
which the internal representation has only a small number of bits. Call
 {⋅} the operator which associates a real number to the closest value in the
architecture’s internal representation; the process is called quantization and
we will study it in more detail in Chapter 10. The transfer function with
quantized coefficients becomes
{⋅} the operator which associates a real number to the closest value in the
architecture’s internal representation; the process is called quantization and
we will study it in more detail in Chapter 10. The transfer function with
quantized coefficients becomes
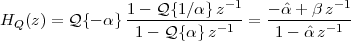
where β = {α}{1∕α}. If the quantization is done with too few bits, β 1
and the filter characteristic is no longer allpass. Suppose for instance that
the filter uses four bits to store its coefficients using an unsigned
fixed point 2.2 format; the 16 possible values are listed in Table 7.1.
1
and the filter characteristic is no longer allpass. Suppose for instance that
the filter uses four bits to store its coefficients using an unsigned
fixed point 2.2 format; the 16 possible values are listed in Table 7.1.
|
If α = 0.4 we have that {0.4} = 0010 = 0.5, {1∕0.4} = {2.5} = 1010 = 2.5
and therefore β = 0101 = 1.25 1.
1.
It is important to point out that the numerical stability of a filter is dependent on the chosen realization. If we rewrite the allpass difference equation as
![( )
y[n ] = α y[n - 1]- x[n] + x[n- 1]](livre916x.png)
we can a block diagram as in Figure 7.30 which, although a non-canonical form, implements the filter with no quantization issues independently of α. Note that the price we pay for robustness is the fact that we have to use two delays instead of one.
Example 7.3: A guitar synthesizer
We have encountered the Karplus-Strong algorithm in Example 2.2. A practical implementation of the algorithm is shown in Figure 7.31; it is a quite peculiar filter structure since it has no input! Indeed assume there are N delays in cascade and neglect for a moment the filter H(z); the structure forms a feedback loop in which the N values contained in the delay units at power-up are endlessly cycled at the output. By loading the N delay units with all sorts of finite-length sequences we can obtain a variety of different sounds; by changing N we can change the fundamental frequency of the note.
The detailed analysis of a waveform generated by the device in Figure 7.31 is
complicated by the fact that the filter does not have zero initial conditions.
Intuitively, however, we can easily appreciate that we can use the filter to
simulate a natural decay in the waveform; imagine H(z) = α with 0 < α < 1:
at each passage through the feedback loop the values in the delay line are
scaled down exponentially. More complicated filters can be used to simulate
different types of acoustic decay as long as  H(ejω)
H(ejω) < 1 over the entire
[-π,π] interval.
< 1 over the entire
[-π,π] interval.
Filter design has been a very popular topic in signal processing, with a large literature, a variety of software designs, and several books devoted to the topic. As examples, we can mention R. Hamming’s Digital Filters (Dover, 1997), and T. W. Parks and C. S. Burrus, Digital Filter Design (Wiley-Interscience, 1987), the latter being specifically oriented towards implementations on a digital signal processor (DSP). All classic signal-processing books cover the topic, for example Oppenheim and Schafer’s book Discrete-Time Signal Processing (Prentis Hall, 1999) gives both structures and design methods for various digital filters.
Exercise 7.1: Discrete-time systems and stability. Consider the system in the picture below. Assume a causal input (x[n] = 0 for n < 0) and zero initial conditions.
|
|
Exercise 7.2: Filter properties – I. Assume is a stable, causal IIR
filter with impulse response g[n] and transfer function G(z). Which of the
following statements is/are true for any choice of G(z)?
Exercise 7.3: Filter properties – II. Consider G(z), the transfer function of a causal stable LTI system. Which of the following statements is/are true for any such G(z)?
Exercise 7.4: Fourier transforms and filtering. Consider the following signal:
![{ ( )(n∕2)+1
x [n] = - 1 for n even
0 for n odd](livre922x.png)
![h[n ] = sinn
πn](livre923x.png)
and compute y[n] = x[n] * h[n].
Exercise 7.5: FIR filters. Consider the following set of complex numbers:

For M = 4,
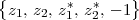
and write out explicitly the expression for H(z).
Is it lowpass, bandpass, highpass?
Is it equiripple?
Is this a “good” filter? (By “good” we mean a filter which is close to 1 in the passband, close to zero in the stopband and which has a narrow transition band.)
Exercise 7.6: Linear-phase FIR filter structure. Assume H(z) is a Type III FIR filter. One of the zeros of the filter is at z0 = 0.8 + 0.1j. You should be able to specify another five zero locations for the filter. Which are they?
Exercise 7.7: FIR filters analysis – I. Consider a causal FIR lowpass filter with the following transfer function:
| H(z) | = 0.005 + 0.03z-1 + 0.11z-2 + 0.22z-3 + 0.27z-4+ | ||
| + 0.22z-5 + 0.11z-6 + 0.03z-7 + 0.005z-8 |
|
|
while the following figure displays an enlarged view of the passband and stopband:
|
|
We will now explore some filters which can be obtained from H(z):
![g[n ] = {0.005, 0, - 0.11, 0, 0.27, 0, - 0.11, 0, 0.005}](livre928x.png)
(i.e. g[0] = 0.005, g[1] = 0, g[2] = -0.11, etc.)
We now want to obtain a linear phase highpass filter f[n] from h[n] and the following design is proposed:
|
|
However the design is faulty:
 F(ejω)
F(ejω) =
=  1 -|H(ejω)|
1 -|H(ejω)| (note the magnitude signs around
H(ejω)); this, however, is not the magnitude response of the above
system. Write out the actual magnitude response.
R, multiplied by a pure phase term.)
(note the magnitude signs around
H(ejω)); this, however, is not the magnitude response of the above
system. Write out the actual magnitude response.
R, multiplied by a pure phase term.)Now it is your turn to design a highpass filter:
Exercise 7.8: FIR filters analysis – II. Consider a generic N-tap Type I FIR filter. Since the filter is linear phase, its frequency response can be expressed as
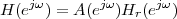
where Hr(ejω) is a real function of ω and A(ejω) is a pure phase term.
Now consider a specific N-tap Type-I FIR filter designed with the Parks-McClellan algorithm. The real part Hr(ejω) for the causal filter is plotted in the following figure.
|
|
We now modify the causal filter H(ejω) to obtain a new causal filter H1(ejω); the real part of the new frequency response is plotted as follows:
|
|
Exercise 7.9: IIR filtering. Consider a causal IIR filter with the following transfer function:
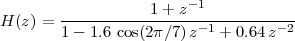
Exercise 7.10: Generalized linear phase filters. Consider the filter given by H(z) = 1 - z-1.
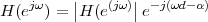
Give the corresponding group delay d and the phase factor α.
![∑ h[n]sin(ω (n - d) + α) = 0
n](livre939x.png)
for all ω.
![∑ ( )
h[n]sin ω (n - d) + α = 0
n](livre940x.png)
for all ω. The above expression is, thus, a necessary condition for a filter to be generalized linear phase.
Exercise 7.11: Echo cancellation. In data communication systems over phone lines (such as voiceband modems), one of the major problems is represented by echos. Impedance mismatches along the analog line create delayed and attenuated replicas of the transmitted signal. These replicas are added to the original signal and represent one type of distortion.
Assume a simple situation where a single echo is created; the transmitted signal is x[n] and, because of the echo, the received signal is
![y[n] = x [n]- αx [n- D ]](livre941x.png)
where α is the attenuation factor (with 0 < α < 1) and D is the echo delay (assume D is an integer).
 H(ejω)
H(ejω) 2.
2.Now assume we have a good estimate of α and D; we want to design a causal echo cancellation filter, i.e. a filter with causal impulse response g[n] such that y[n] * g[n] = x[n].
Exercise 7.12: FIR filter design – I. Is it a good idea to use a Type III FIR to design a lowpass filter? Briefly explain.
Exercise 7.13: FIR filter design – II. Suppose you want to design a linear phase FIR approximation of a Hilbert filter. Which FIR type would you use? Why? Discuss advantages and disadvantages.
| © Presses polytechniques et universitaires romandes, 2008 All rights reserved |
In the previous Chapters, the signals we considered were all deterministic signals in the sense that they could either be expressed in analytic form (such as x[n] = (1 - λ)λn) or they could be explicitly described in terms of their samples, such as in the case of finite-length signals. When designing a signal processing system, however, it is very rare that we know exactly the expression for the set of all the possible input signals (in some sense, if we did, we would not need a processing system at all.) Fortunately, very often this set can be characterized in terms of the statistical properties of its member signals; this entails leaving the domain of deterministic quantities and entering the world of stochastic processes. A detailed and rigorous treatment of statistical signal processing is beyond the scope of this book; here, we only consider elementary concepts and restrict ourselves to the discrete-time case. We will be able to derive that, fundamentally, in the case of stationary random signals, the standard signal processing machinery that we have seen so far (and especially the usual filter design techniques) is still applicable with very intuitive results. To establish a coherent notation, we start by briefly reviewing some elementary concepts of probability theory.
Probability Distribution. Consider a real-valued random variable X taking values over R. The random variable(1) is characterized by its cumulative distribution function FX (cdf) which is defined as
![FX (α) = P[X ≤ α ], α ∈ R-](livre944x.png)
that is, FX(α) measures the probability that X takes values less than or equal to α. The probability density function (pdf) is related to the cdf (assuming that FX is differentiable) as
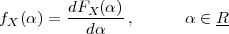
and thus
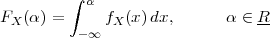
Expectation and Second Order Statistics. For random variables, a fundamental concept is that of expectation, defined as follows:
![∫
∞
E [X ] = -∞ xfX (x)dx](livre947x.png)
The expectation operator is linear; given two random variables X and Y , we have
![E[aX + bY ] = aE [X ]+ bE[Y ]](livre948x.png)
Furthermare, given a function g : R R, we have
R, we have
![[ ] ∫ ∞
E g(X ) = g (x )fX (x)dx
-∞](livre950x.png)
The expectation of a random variable is called its mean, and we will indicate it by mX. The expectation of the product of two random variables defines their correlation:
![RXY = E [XY ]](livre951x.png)
The variables are uncorrelated if
![E[XY ] = E[X ]E[Y]](livre952x.png)
Sometimes, the “centralized” correlation, or covariance, is used, namely
| KXY | = E (X - mX)(Y - mY ) (X - mX)(Y - mY )![]](livre954x.png) | ||
| = E[XY ] - E[X]E[Y ] |
The variance of a random variable X, denoted by σX2, is defined as
![[ ]
σ2X = E (X - mX )2](livre955x.png)
The square root of the variance, σX, is often called the standard deviation of X.
Example: Gaussian Random Variable. A Gaussian random variable is described by the probability density function:
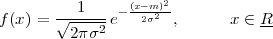 | (8.1) |
which is known as the normal distribution. Clearly, the mean of the
Gaussian variable is m, while its variance is σ2. The normalization factor
1∕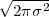 ensures that, as for all random variables, the integral of the pdf
over the entire real line is equal to one.
ensures that, as for all random variables, the integral of the pdf
over the entire real line is equal to one.
Probability Distribution. A random vector X is a collection of N
random variables ![[X X ... X ]T
0 1 N- 1](livre958x.png) , with a cumulative distribution
function FX given by
, with a cumulative distribution
function FX given by
![FX (α ) = P [Xi ≤ αi, i = 0,1,...,N - 1]](livre959x.png)
where ![α = [α α ... α ]T ∈ RN
0 1 N- 1](livre960x.png) . The pdf is obtained, assuming
differentiability, as
. The pdf is obtained, assuming
differentiability, as
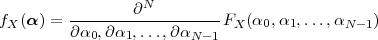
With respect to vector random variables, two key notions are:
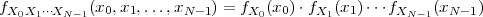 | (8.2) |

Random vectors represent the generalization of finite-length, discrete-time signals to the space of random signals.
Expectation and Second Order Statistics. For random vectors, the definitions given, in the case of random variables, extend immediately to the multidimensional case. The mean of a N-element random vector X is simply the N-element vector:
![E [X ] = [ ]T = [ ]T = m
E[X0]E[X1]...E [XN - 1] mX0mX1 ... mXN -1 X](livre964x.png) |
The correlation of two N-element random vectors is the N × N matrix:
![T
RXY = E[XY ]](livre965x.png)
where the expectation operator is applied individually to all the elements of the matrix XY T . The covariance is again:
![[ T]
KXY = E (X - mX )(Y - mY )](livre966x.png)
and it coincides with the correlation for zero-mean random vectors. Note that the general element RXY (k,l) indicates the correlation between the k-th element of X and the l-th element of Y . In particular, RXX(k,l) indicates the correlation between elements of the random vector X; if the elements are uncorrelated, then the correlation matrix is diagonal.
Example: Jointly Gaussian Random Vector. An important type of vector random variable is the Gaussian random vector of dimension N. To define its pdf, we need a length-N vector m and a positive definite matrix Λ of size N × N. Then, the N-dimensional Gaussian pdf is given by
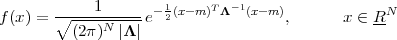 | (8.3) |
where |Λ| is the determinant of Λ. Clearly, m is the vector of the means of the single elements of the Gaussian vector while Λ is the autocorrelation matrix. A diagonal matrix implies the decorrelation of the random vector’s elements; in this case, since all the elements are Gaussian variables, this also means that the elements are independent. Note how, for N = 1 and Λ = σ2, this reduces to the usual Gaussian distribution of (8.1).
Probability Distribution. Intuitively, a discrete-time random process is
the infinite-dimensional generalization of a vector random variable, just like a
discrete-time sequence is the infinite generalization of a finite-length signal. For
a random process (also called a stochastic process) we use the notation X[n]
to indicate the n-th random variable which is the n-th value (sample) of the
sequence.(3)
Note however that the pdf associated to the random process is the joint
distribution of the entire set of samples in the sequence; in general, therefore,
the statistical properties of each sample depend on the global stochastic
description of the process and this accounts for local and long-range
dependencies in the random data. In fact, consider a random process
 X[n], n Z
X[n], n Z ; any finite subset of random variables from X[n] is a vector
random variable
; any finite subset of random variables from X[n] is a vector
random variable ![[ ]T
X = X [i0] X [i1] ... X [ik- 1]](livre970x.png) , k N. The
statistical description of a random process involves specifying the joint pdf
for X for all k-tuples of time indices ik and all k N, i.e. all the pdfs of the
form
, k N. The
statistical description of a random process involves specifying the joint pdf
for X for all k-tuples of time indices ik and all k N, i.e. all the pdfs of the
form
![fX [i0]X [i1]⋅⋅⋅X [ik-1](x0,x1,...,xk- 1)](livre971x.png) | (8.4) |
Clearly, the most general form of random process possesses a statistical
description which is difficult to use. At the other extreme, the simplest form
of stochastic process is the i.i.d. process. For an i.i.d. process we have that
the elements of X are i.i.d. for all k-tuples of time indices ik and all k N,
that is
![k-1
f (x ,x ,...,x ) = ∏ f(x )
X[i0]X[i1]⋅⋅⋅X[ik-1] 0 1 k-1 i
i=0](livre972x.png) | (8.5) |
where f(x) is called the pdf of the i.i.d. process.
Second Order Description. The mean of a process X[n], n Z is simply
E X[n]
X[n]![]](livre974x.png) which, in general, depends on the index n. The correlation (also
called the autocorrelation) of X[n] is defined as
which, in general, depends on the index n. The correlation (also
called the autocorrelation) of X[n] is defined as
![RX [l,k] = E [X [lX [k]], l,k ∈ Z-](livre975x.png)
while its covariance (also called autocovariance)(4) is
| KX[l,k] | = E![[( )( )]
X [l]- mX [l] X [k] - mY [k]](livre976x.png) | ||
| = RX[l,k] - mX[l]mX[k] , l,k Z |
![[ ]
RXY [l,k] = E X [l]Y [k ]](livre977x.png) | (8.6) |
Mean and variance of a random process represent a second order description of the process since their computation requires knowledge of only the second order joint pdf of the process (i.e. of the pdfs in (8.4) involving only two indices ik). A second order description is physically meaningful since it can be associated to the mean value and mean power of the random process, as we will see.
Stationary Processes. A very important class of random processes are the stationary processes, for which the probabilistic behavior is constant over time. Stationarity, in the strict sense, implies that the full probabilistic description of the process is time-invariant; for example, any i.i.d. process is also a strict-sense stationary process. Stationarity can be restricted to n-th order stationarity, meaning that joint distributions (and therefore expectations) involving up to n samples are invariant with respect to a time shift. The case n = 2 is particulary important and it is called wide-sense stationarity (WSS). For a WSS process, the mean and the variance are constant over time:
E X[n] X[n]![]](livre979x.png) | = mX , n Z | (8.7) |
E![[( ) ]
X [n]- mX 2](livre980x.png) | = σX2 , n Z | (8.8) |
| RX[l,k] | = rX[l - k], l,k Z | (8.9) |
| KX[l,k] | = kX[l - k], l,k Z | (8.10) |
![RXY [l,k] = rXY [l - k ]](livre981x.png)
Ergodicity. In the above paragraphs, it is important to remember that
expectations are taken with respect to an ensemble of realizations of the
process under analysis. To visualize the concept, imagine having a black box
which, at the turn of a switch, can generate a realization of a discrete-time
random process X[n]. In order to estimate the mean of the process at
time n0, i.e. E X[n0]
X[n0]![]](livre983x.png) , we need to collect as many realizations as
possible and then estimate the mean at time n0 by averaging the values
of the process at n0 across realizations. For stationary processes, it
may seem intuitive that instead of averaging across realizations, we
can average across successive samples of the same realization. This
is not true in the general case, however. Consider for instance the
process
, we need to collect as many realizations as
possible and then estimate the mean at time n0 by averaging the values
of the process at n0 across realizations. For stationary processes, it
may seem intuitive that instead of averaging across realizations, we
can average across successive samples of the same realization. This
is not true in the general case, however. Consider for instance the
process
![X [n] = α](livre984x.png)
where α is a random variable. Clearly the process is stationary since each realization of this process is a constant discrete-time signal, but the value of the constant changes for each realization. If we try to estimate the mean of the process from a single realization, we obtain no information on the distribution of α; that can be achieved only by looking at several independent realizations.
The class of processes for which it is legitimate to estimate expectations from a single realization is the class of ergodic processes. For ergodic processes we can, for instance, take the time average of the samples of a single realization and this average converges to the ensemble average or, in other words, it represents a precise estimate of the true mean of the stochastic process. The same can be said for expectations involving the product of process samples, such as in the computation of the variance or of the correlation.
Ergodicity is an extremely useful concept in the domain of stochastic signal processing since it allows us to extract useful statistical information from a single realization of the process. More often than not, experimental data is difficult or expensive to obtain and it is not practical to repeat an experiment over and over again to compute ensemble averages; ergodicity is the way out this problem, and it is often just assumed (sometimes without rigorous justification).
Example: Gaussian Random Processes. A Gaussian random process is one for which any set of samples is a jointly Gaussian random vector. A fundamental property of a Gaussian random process is that, if it is wide-sense stationary, then it is also stationary in the strict sense. This means that second order statistics are a sufficient representation for Gaussian random processes.
Given a stationary random process, we are interested in characterizing its “energy distribution” in the frequency domain. Note that we have used quotes around the term energy: since a stationary process does not decay in time (because of stationarity), it is rather intuitive that its energy is infinite (very much like a periodic signal). In other words, the sum:
![M∑
X2 [n ]
n= -M](livre985x.png)
diverges in expectation. Signals which are not square-summable are not absolutely summable either, and therefore their Fourier transform does not exist in the standard sense. In order to derive a spectral representation for a random process we thus need to look for an alternative point of view.
In Section 2.1.6 we introduced the notion of a power signal, particularly in relation to the class of periodic sequences; while the total energy of a power signal may be infinite, its energy over any finite support is always finite and it is proportional to the length of the support. In this case, the limit:
![1 ∑M | |2
Mlim→∞ 2M--+-1 |x[n]|
n=-M](livre986x.png)
is finite and it represents the signal’s average power (in time). Stationary random processes are themselves power signals if their variance is finite; indeed (assuming a zero-mean process), we have
E![[ ]
1 M∑
------- X2 [n ]
2M + 1n= -M](livre987x.png) | = 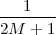 ∑
n=-MME ∑
n=-MME X2[n] X2[n]![]](livre990x.png) | ||
= 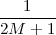 ∑
n=-MMσ2 ∑
n=-MMσ2 | |||
| = σ2 |
For signals (stochastic or not) whose power is finite but whose energy is not, a meaningful spectral representation is obtained by considering the so-called power spectral density (PSD). We know that, for a square-summable sequence, the square magnitude of the Fourier transform represents the global spectral energy distribution. Since the energy of a power signal is finite over a finite-length observation window, the truncated Fourier transform
![∑M
XM (ejω) = x[n ]e- jωn
n=-M](livre992x.png) | (8.11) |
exists, is finite, and its magnitude is the energy distribution of the signal over the time interval [-M,M]. The power spectral density is defined as
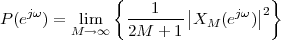 | (8.12) |
and it represents the distribution of power in frequency (and therefore its physical dimensionality is expressed as units of energy over units of time over units of frequency). Obviously, the PSD is a 2π-periodic real and non-negative function of ω.
It can be shown that the PSD of an N-periodic stationary signal 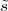 [n] is
given by the formula:
[n] is
given by the formula:
![N∑ -1 ( )
P (ejω ) = ||S˜[k]||2 ˜δ ω - 2π-k
k=0 N](livre995x.png)
where all the 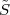 [k] are the N DFS coefficients of s[n]; this is rather intuitive
since, for a periodic signal, the power is distributed only over the
harmonics of the fundamental frequency. Conversely, the PSD of a
finite-energy deterministic signal is obviously zero since its power is
zero.
[k] are the N DFS coefficients of s[n]; this is rather intuitive
since, for a periodic signal, the power is distributed only over the
harmonics of the fundamental frequency. Conversely, the PSD of a
finite-energy deterministic signal is obviously zero since its power is
zero.
For stationary random processes the situation is rather interesting. If we rewrite (8.11) for the WSS random process X[n], the quantity:
![| |2
| |2 ||∑M ||
|XM (ejω)| = || X [n ]e-jωn||
n= -M](livre997x.png)
which we could call a “local energy distribution”, is now a random variable itself parameterized by ω. We can therefore consider its mean value and we have
E![[|| jω ||2]
XM (e )](livre998x.png) | = E XM*(ejω)X
M(ejω) XM*(ejω)X
M(ejω)![]](livre1000x.png) | ||
= E![[ ∑M ∑M ]
X [n ]ejωn X [m ]e-jωm
n= -M m=- M](livre1001x.png) | |||
= ∑
n=-MM ∑
m=-MME X[n]X[m] X[n]X[m]![]](livre1003x.png) e-jω(m-n) e-jω(m-n) | |||
| = ∑ n=-MM ∑ m=-MMr X[m - n]e-jω(m-n) |
![[| jω |2] 2∑M ( ) -jωk
E |XM (e )| = 2M + 1 - |k| rX [k]e
k= -2M](livre1004x.png)
The power spectral density is obtained by plugging the above expression into (8.12), which gives
| PX(ejω) | = lim
M→∞![{ }
1 [| jω |2]
2M--+-1 E |XM (e )|](livre1005x.png) | ||
= limM→∞∑
k=-2M2M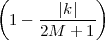 ![( )
rX [k]e-jωk](livre1007x.png) | |||
| = limM→∞∑ k=-∞∞w k(M)rX[k]e-jωk | (8.13) |
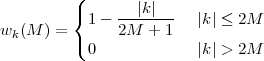 | (8.14) |
Since  wk(M)rX[k]e-jωk
wk(M)rX[k]e-jωk ≤
≤ rX[k]
rX[k] , if the autocorrelation is absolutely
summable then the sum (8.13) converges uniformly to a continuous function
of M. We can therefore move the limiting operation inside the sum; now the
key observation is that the weighting term wk(M), considered as a function
of k parametrized by M, converges in the limit to the constant one (Eq.
(8.14)):
, if the autocorrelation is absolutely
summable then the sum (8.13) converges uniformly to a continuous function
of M. We can therefore move the limiting operation inside the sum; now the
key observation is that the weighting term wk(M), considered as a function
of k parametrized by M, converges in the limit to the constant one (Eq.
(8.14)):
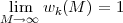
![∞
jω ∑ -jωk
PX (e ) = rX[k]e
k=- ∞](livre1014x.png) | (8.15) |
This fundamental result means that the power spectral density of a WSS process is the discrete-time Fourier transform of its autocorrelation. Similarly, we can define the cross-power spectral density between two WSS processes X[n] and Y [n] as
![jω ∑∞ -jωk
PX Y(e ) = rXY[k]e
t=- ∞](livre1015x.png) | (8.16) |
|
|
A WSS random process W[n] whose mean is zero and whose samples are uncorrelated is called white noise. The autocorrelation of a white noise process is therefore:
![rW [n] = σ2W δ[n ]](livre1017x.png) | (8.17) |
where σW 2 is the variance (i.e. the expected power) of the process. The power spectral density of a white noise process is simply:
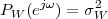 | (8.18) |
Please note:
In stochastic signal processing, we are considering the outcome of a filtering operation which involves a random process; that is, given a linear time-invariant filter with impulse response h[n], we want to describe the output signal as follows:
![∞
Y [n] = ∑ h[k]X [n - k]
k=-∞](livre1019x.png)
Note that Y [n] and X[n] denote random variables and are thus capitalized, while h[n] is a deterministic impulse response and is therefore lowercase. In the following, we will assume a stable LTI filter and a wide-sense stationary (WSS) input process.
Time-Domain Analysis. The expected value of the filter’s output is
| mY [n] | = E Y [n] Y [n]![]](livre1021x.png) = E = E![[ ]
∑∞
h[k]X [n - k]
k=0](livre1022x.png) | ||
= ∑
k=-∞∞h[k]E X[n - k] X[n - k]![]](livre1024x.png) | |||
| = ∑ k=-∞∞h[k]m n-k | (8.19) |
 X[n]
X[n]![]](livre1026x.png) = mX
for all n, and therefore the output has a constant expected value:
= mX
for all n, and therefore the output has a constant expected value:
![∑∞
mY = mX h[k] = mX H (ej0)
k=- ∞](livre1027x.png)
If the input is WSS, it is fairly easy to show that the output is also WSS; in other words, LTI filtering preserves wide-sense stationarity. The autocorrelation of the output process Y [n] depends only on the time difference:
![R [n, m] = r [n- m]
Y Y](livre1028x.png)
and it can be shown that:
![∑∞ ∑∞
rY[n] = h[k]h[i]rY [n - i+ k ]
k=- ∞i=- ∞](livre1029x.png)
or, more concisely,
![rY [n] = h[n]*h [- n]* rX[n]](livre1030x.png) | (8.20) |
Similarly, the cross-correlation between input and output is
![rXY [n] = h[n]* rX[n]](livre1031x.png) | (8.21) |
Frequency-Domain Analysis. It is immediately obvious from (8.20) that the power spectral density of the output process Y [n] is
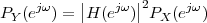 | (8.22) |
where H(ejω) is, as usual, the frequency response of the filter. Similarly, from (8.21) we obtain
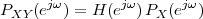 | (8.23) |
The above result is of particular interest in the practical problem of
estimating the characteristics of an unknown filter; this is a particular
instance of a spectral estimation problem. Indeed, if we inject white noise of
known variance σ2 into an unknown LTI system , equation (8.23)
becomes:
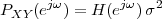
By numerically computing the cross-correlation between input and output, we can therefore derive an estimation of the frequency response of the system.
The total power of a stochastic process X[n] is the variance of the process itself, σX2 = rX[0]; from the PSD, this can be obtained by the usual DTFT inversion formula as
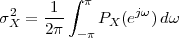 | (8.24) |
which, for a filtered process, specializes to
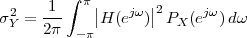 | (8.25) |
Example 8.1: Intuition behind power spectra
The empirical average for a random variable X is the simple average:
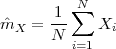
where x1,x2,…,xN are N independent “trials” (think coin tossing). Similarly, we can obtain an estimation for the variance as
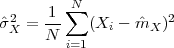
For an ergodic process, we can easily obtain a similar empirical estimate for the covariance: we replace the N trials with N successive samples of the process so that (assuming zero mean):
![N∑
ˆrX [n] = -1 X [i]X [i- n]
N i=1](livre1039x.png)
The empirical autocorrelation has the form of an inner product between two displaced copies of the same sequence. We saw in Section 5.2 that this represents a measure of self-similarity. In white processes the samples are so independent that for even the smallest displacement (n = 1) the process is totally “self-dissimilar”. Consider now a process with a lowpass power spectrum; this means that the autocorrelation varies slowly with the index and we can deduce that the process possesses a long-range self-similarity, i.e. it is smooth. Similarly, a highpass power spectrum implies a jumping autocorrelation, i.e. a process whose self-similarity varies in time.
Example 8.2: Top secret filters
Stochastic processes are a fundamental tool in adaptive signal processing, a more advanced type of signal processing in which the system changes over time to better match the input in the pursuit of a given goal. A typical example is audio coding, for instance, in which the signal is compressed by algorithms which are modified as a function of the type of content. Another prototypical application is denoising, in which we try to remove spurious noise from a signal. Since these systems are adaptive, they are best described as a function of a probabilistic model for the input.
In this book stochastic processes will be used mainly as a tool to study the effects of quantization (hence the rather succinct treatment heretofore). We can nonetheless try and “get a taste” of adaptive processing by considering one of the fundamental results in the art of denoising, namely the Wiener filter. This filter was developed by Norbert Wiener during World War II as a tool to smooth out the tracked trajectories of enemy airplanes and aim the antiaircraft guns at the most likely point the target would pass by next. Because of this sensitive application, the theory behind the filter remained classified information until well after the end of the war.
The problem, in its essence, is shown in Figure 8.2 and it begins with a signal corrupted by additive noise:
![X [n ] = S[n]+ W [n]](livre1041x.png)
both the clean signal S[n] and the noise W[n] are assumed to be zero-mean stationary processes; assume further that they are jointly stationary and independent. We want to design a filter h[n] to clean up the signal as much as possible; if the filter’s output is
![ˆS[n] = h[n]* X [n ]](livre1042x.png)
then the error between the original and the estimation can be expressed as
![ˆ
Δ [n] = S [n] - S[n]](livre1043x.png)
It can be shown that the minimization of the expected square error corresponds to an orthogonality condition between the error and the filter’s input:(5) :
![[ ]
E Δ [n ]X [m ] = 0](livre1046x.png) | (8.26) |
intuitively this means that anything contained in the error could not have been predicted from the input, so the filter is doing the absolute best it can. From the orthogonality condition we can derive the optimal filter; from (8.26), we have
![E [S[n]X [m ]] = E [ˆS[n]X [m ]]](livre1047x.png)
and, by using (8.21),
![rSX [n ] = h[n]* rX[n]](livre1048x.png) | (8.27) |
By invoking the independence of signal and noise and their zero mean we have
| rSX[n] | = rS[n] | ||
| rX[n] | = rS[n] + rW [n] |
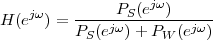 | (8.28) |
the frequency response attenuates the input where the noise is powerful while the signal is not, and it leaves the input almost unchanged otherwise, hence the data-dependence of its expression.
The optimal filter above was derived for an arbitrary infinite two-sided impulse response. Wiener’s contribution was mainly concerned with the design of a causal response; the derivation is a little complicated and we will not detail it here. A third, interesting design choice is imposing that the impulse response be an N-tap FIR. In this case (8.27) becomes
![N∑ -1
h[k]rX[n - k] = rS[n]
k=0](livre1050x.png)
and by picking N successive values for n we can build the system of equations:
![⌊ ⌋ ⌊ ⌋ ⌊ ⌋
r [0] r [1] ... r [N - 1] h[0] r [0]
| X X X | | | | S |
|| rX[1] rX[0] ... rX [N - 2]|| || h[1] || || rS[1] ||
|| r [2] r [1] ... r [N - 3]|| || h[2] || = || r [2] ||
|| X. X. X . || || . || || S. ||
|⌈ .. .. ... .. |⌉ |⌈ .. |⌉ |⌈ .. |⌉
rX[N - 1] rX[N - 2] ... rX [0] h[N - 1] rS[N - 1]](livre1051x.png)
where the Toeplitz nature of the matrix comes from the fact that rX[-n] = rX[n]. This is a classical Yule-Walker system of equations and it is a fundamental staple of adaptive signal processing.
A good introductory reference on the subject is E. Parzen’s classic Stochastic Processes (Society for Industrial Mathematics, 1999). For adaptive signal processing, see P. M. Clarkson’s Optimal and Adaptive Signal Processing (CRC Press, 1993). For an introduction to probability, see the textbook: D. P. Bertsekas and J. N. Tsitsiklis, Introduction to Probability (Athena Scientific, 2002). The classic book by A. Papoulis, Probability, Random Variables, and Stochastic Processes (McGraw Hill, 2002) still serves as a good, engineering-oriented introduction. A more contemporary treatment of stochastic processes can be found in P. Thiran’s excellent class notes for the course “Processus Stochastiques pour les Communications”, given at the Swiss Federal Institute of Technology (EPFL) in Lausanne.
Exercise 8.1: Filtering a random process – I. Consider a zero-mean white random process X[n] with autocorrelation function rx[m] = σ2 δ[m]. The process is filtered with a 2-tap FIR filter whose impulse response is h[0] = h[1] = 1. Compute the values of the autocorrelation for the output random process Y [n] = X[n] * h[n] from n = -3 to n = 3.
Exercise 8.2: Filtering a random process – II. Consider a zero-mean white random process X[n] with autocorrelation function rX[m] = σ2 δ[m]. The process is filtered with leaky integrator (H(z) = (1 - λ)∕(1 - λz-1)) producing the signal Y [n] = X[n] * h[n]. Compute the values of the input-output cross-correlation from n = -3 to n = 3.
Exercise 8.3: Power spectral density. Consider the stochastic process defined by
![Y [n] = X [n]+ βX [n - 1]](livre1052x.png)
where β R and X[n] is a zero-mean wide-sense stationary process with
autocorrelation function given by
![2 |k|
RX [k] = σ α](livre1053x.png)
for |α| < 1.
Exercise 8.4: Filtering a sequence of independent random variables. Let X[n] be a real signal modeled as the outcome of a sequence of i.i.d. real random variables that are Gaussian, centered (zero mean), with variance σX2 = 3. We wish to process this sequence with the following filter:
![1- 1- 1-
h[1] = 2 , h[2] = 4 , h[3] = 4 , h [n] = 0 ∀ n ⁄= 1,2,3](livre1054x.png)
Moreover, at the output of the filter, we add a white Gaussian noise Z[n] with unitary variance. The system is shown in the following diagram:

Consider now an input signal of length N.
| © Presses polytechniques et universitaires romandes, 2008 All rights reserved |
Signals (in signal processing) are nothing but mathematical models capturing the essence of a flow of information. Discrete-time signals are the model of choice in two archetypal processing situations: the first, which encompasses the long-established tradition of observing physical phenomena, captures the process of repeatedly measuring the value of a physical quantity at successive instants in time for analysis purposes (precipitation levels, stock values, etc.). The second, which is much more recent and dates back to the first digital processors, is the ability to synthesize discrete-time signals by means of iterative numerical algorithms (mathematical simulations, computer music, etc.). Discrete-time is the mechanized playground of digital machines.
Continuous-time signals, on the other hand, leverage on a view of the world in which physical phenomena have, potentially, an infinitely small granularity, in the sense that measurements can be arbitrarily dense. In this continuous-time paradigm, real-world phenomena are modeled as functions of a real variable; the definition of a signal over the real line allows for infinitely small subdivisions of the function’s domain and, therefore, infinitely precise localization of its values. Whether philosophically valid(1) or physically valid,(2) the continuous-time paradigm is an indispensable model in the analysis of analog signal processing systems.
We will now study the mathematical description of the (porous) interface between continuous-time and discrete time. The tools that we will introduce, will allow us to cross this boundary, back and forth, with little or no loss of information for the signals involved.
Interpolation. Interpolation comes into play when discrete-time signals need to be converted to continuous-time signals. The need arises at the interface between the digital world and the analog world; as an example, consider a discrete-time waveform synthesizer which is used to drive an analog amplifier and loudspeaker. In this case, it is useful to express the input to the amplifier as a function of a real variable, defined over the entire real line; this is because the behavior of analog circuitry is best modeled by continuous-time functions. We will see that at the core of the interpolation process is the association of a physical time duration Ts to the intervals between samples of the discrete-time sequence. The fundamental questions concerning interpolation involve the spectral properties of the interpolated function with respect to those of the original sequence.
Sampling. Sampling is the method by which an underlying continuous-time phenomenon is “reduced” to a discrete-time sequence. The simplest sampling system just records the value of a physical variable at repeated instants in time and associates the value to a point in a discrete-time sequence; in the following, we refer to this scheme as the “naive” sampling operator. Other sampling methods exist (and we will see the most important one) but, in all cases, a correspondence is established between time instants in continuous time and points in the discrete-time sequence. In the following, we only consider uniform sampling, in which the time instants are uniformly spaced Ts seconds apart. Ts is called the sampling period and its inverse, Fs is called the sampling frequency of a sampling system. The fundamental question of sampling is whether any information is lost in the sampling process. If the answer is in the negative (at least for a given class of signals), this means that all the processing tools developed in the discrete-time domain can be applied to continuous-time signals as well, after sampling.
|
Notation. In the rest of this Chapter we will encounter a series of variables which are all interrelated and whose different forms will be used interchangeably according to convenience. They are summarized as a quick reference in Table 9.1.
Interpolation and sampling constitute the bridges between the discrete- and continuous-time worlds. Before we proceed to the core of the matter, it is useful to take a quick tour of the main properties of continuous-time signals, which we simply state here without formal proofs.
Continuous-time signals are modeled by complex functions of a real variable t which usually represents time (in seconds) but which can represent other physical coordinates of interest. For maximum generality, no special requirement is imposed on functions modeling signals; just as in the discrete-time case, the functions can be periodic or aperiodic, or they can have a finite support (in the sense that they are nonzero over a finite interval only). A common condition, on an aperiodic signal, is that its modeling function be square integrable; this corresponds to the reasonable requirement that the signal have finite energy.
Inner Product and Convolution. We have already encountered some examples of continuous-time signals in conjunction with Hilbert spaces; in Section 3.2.2, for instance, we introduced the space of square integrable functions over an interval and we will shortly introduce the space of bandlimited signals. For inner product spaces, whose elements are functions on the real line, we use the following inner product definition:
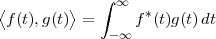 | (9.1) |
The convolution of two real continuous-time signals is defined as usual from the definition of the inner product; in particular:
| (f * g)(t) | =  f(t - τ),g(τ) f(t - τ),g(τ) | (9.2) |
| = ∫ -∞∞f(t - τ)g(τ)dτ | (9.3) |
Frequency-Domain Representation of Continuous-Time Signals.
The Fourier transform of a continuous-time signal x(t) and its inversion formula are
defined as(3)
| X(jΩ) = ∫ -∞∞x(t)e-jΩt dt | (9.4) | |
x(t) =  ∫
-∞∞X(jΩ)ejΩt dΩ ∫
-∞∞X(jΩ)ejΩt dΩ | (9.5) |
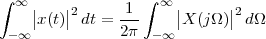
The FT representation can be formally extended to signals which are not square summable by means of the Dirac delta notation as we saw in Section 4.4.2. In particular we have
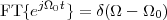 | (9.6) |
from which the Fourier transforms of sine, cosine, and constant functions can easily be derived. Please note that, in continuous-time, the FT of a complex sinusoid is not a train of impulses but just a single impulse.
The Convolution Theorem. The convolution theorem for continuous-time signal exactly mirrors the theorem in Section 5.4.2; it states that if h(t) = (f * g)(t) then the Fourier transforms of the three signals are related by H(jΩ) = F(jΩ)G(jΩ). In particular we can use the convolution theorem to compute
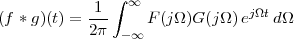 | (9.7) |
A signal whose Fourier transform is nonzero only, over a finite frequency interval, is called bandlimited. In other words, the signal x(t) is bandlimited if there exists a frequency ΩN such that:(4)

Such a signal will be called ΩN-bandlimited and ΩN is often called the Nyquist frequency. It may be useful to mention that, symmetrically, a continuous-time signal which is nonzero, over a finite time interval only, is called a time-limited signal (or finite-support signal). A fundamental theorem states that a bandlimited signal cannot be time-limited, and vice versa. While this can be proved formally and quite easily, here we simply give the intuition behind the statement. The time-scaling property of the Fourier transform states that:
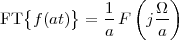 | (9.8) |
so that the more “compact” in time a signal is, the wider its frequency support becomes.
The Sinc Function. Let us now consider a prototypical ΩN-bandlimited signal φ(t) whose Fourier transform is a real constant over the interval [-ΩN,ΩN] and zero everywhere else. If we define the rect function as follows (see also Section 5.6):
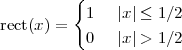
we can express the Fourier transform of the prototypical ΩN-bandlimited signal as
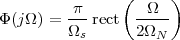 | (9.9) |
where the leading factor is just a normalization term. The time-domain expression for the signal is easily obtained from the inverse Fourier transform as
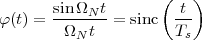 | (9.10) |
where we have used Ts = π∕ΩN and defined the sinc function as
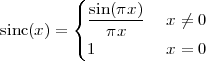
The sinc function is plotted in Figure 9.6. Note the following:
Interpolation is a procedure whereby we convert a discrete-time sequence x[n] to a continuous-time function x(t). Since this can be done in an arbitrary number of ways, we have to start by formulating some requirements on the resulting signal. At the heart of the interpolating procedure, as we have mentioned, is the association of a physical time duration Ts to the interval between the samples in the discrete-time sequence. An intuitive requirement on the interpolated function is that its values at multiples of Ts be equal to the corresponding points of the discrete-time sequence, i.e.
![|
x(t)|| = x[n]
t=nTs](livre1069x.png)
The interpolation problem now reduces to “filling the gaps” between these instants.
The simplest interpolation schemes create a continuous-time function x(t) from a discrete-time sequence x[n], by setting x(t) to be equal to x[n] for t = nTs and by setting x(t) to be some linear combination of neighboring sequence values when t lies in between interpolation instants. In general, the local interpolation schemes can be expressed by the following formula:
![∞ ( )
∑ t--nTs-
x (t) = x[n]I Ts
n=-∞](livre1070x.png) | (9.11) |
where I(t) is called the interpolation function (for linear functions the notation IN(t) is used and the subscript N indicates how many discrete-time samples, besides the current one, enter into the computation of the interpolated values for x(t)). The interpolation function must satisfy the fundamental interpolation properties:
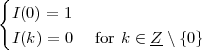 | (9.12) |
where the second requirement implies that, no matter what the support of I(t) is, its values should not affect other interpolation instants. By changing the function I(t), we can change the type of interpolation and the properties of the interpolated signal x(t).
Note that (9.11) can be interpreted either simply as a linear combination of shifted interpolation functions or, more interestingly, as a “mixed domain” convolution product, where we are convolving a discrete-time signal x[n] with a continuous-time “impulse response” I(t) scaled in time by the interpolation period Ts.
Zero-Order Hold. The simplest approach for the interpolating function is the piecewise-constant interpolation; here the continuous-time signal is kept constant between discrete sample values, yielding
![( 1) ( 1)
x(t) = x[n], for n - -- Ts ≤ t < n + -- Ts
2 2](livre1072x.png)
and an example is shown in Figure 9.1; it is apparent that the resulting function is far from smooth since the interpolated function is discontinuous. The interpolation function is simply:
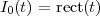
and the values of x(t) depend only on the current discrete-time sample value.
|
|
First-Order Hold. A linear interpolator (sometimes called a first-order hold) simply connects the points corresponding to the samples with straight lines. An example is shown in Figure 9.2; note that now x(t) depends on two consecutive discrete-time samples, across which a connecting straight line is drawn. From the point of view of smoothness, this interpolator already represents an improvement over the zero-order hold: indeed the interpolated function is now continuous, although its first derivative is not. The first-order hold can be expressed in the same notation as in (9.11) by defining the following triangular function:
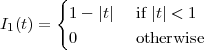
which is shown in Figure 9.3.(5) It is immediately verifiable that I1(t) satisfies the interpolation properties (9.12).
|
|
|
|
Higher-Order Interpolators. The zero- and first-order interpolators are widely used in practical circuits due to their extreme simplicity. Note that the interpolating functions I0(t) and I1(t) are alsol knows as the B-spline functions of order zero and one respectively. These schemes can be extended to higher order interpolation functions and, in general, IN(t) is a N-th order polynomial in t. The advantage of the local interpolation schemes is that, for small N, they can easily be implemented in practice as causal interpolation schemes (locality is akin to FIR filtering); their disadvantage is that, because of the locality, their N-th derivative is discontinuous. This discontinuity represents a lack of smoothness in the interpolated function; from a spectral point of view this corresponds to a high frequency energy content, which is usually undesirable.
The lack of smoothness of local interpolations is easily eliminated when we need to interpolate just a finite number of discrete-time samples. In fact, in this case the task becomes a classic polynomial interpolation problem for which the optimal solution has been known for a long time under the name of Lagrange interpolation. Note that a polynomial interpolating a finite set of samples is a maximally smooth function in the sense that it is continuous, together with all its derivatives.
Consider a length (2N + 1) discrete-time signal x[n], with n = -N,…,N.
Associate to each sample an abscissa tn = nTs; we know from basic algebra
that there is one and only one polynomial P(t) of degree 2N which passes
through all the 2N + 1 pairs  tn,x[n]
tn,x[n] and this polynomial is the Lagrange
interpolator. The coefficients of the polynomial could be found by solving the
set of 2N + 1 equations:
and this polynomial is the Lagrange
interpolator. The coefficients of the polynomial could be found by solving the
set of 2N + 1 equations:
![{ }
P(tn) = x[n ] n= -N,...,N](livre1081x.png) | (9.13) |
but a simpler way to determine the expression for P(t) is to use the set of 2N + 1 Lagrange polynomials of degree 2N:
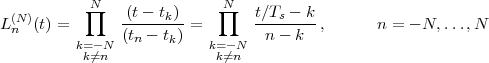 | (9.14) |
The polynomials Ln(N)(t) for Ts = 1 and N = 2 (i.e. interpolation of 5 points) are plotted in Figure 9.4. By using this notation, the global Lagrange interpolator for a given set of abscissa/ordinate pairs can now be written as a simple linear combination of Lagrange polynomials:
![N∑ (N )
P(t) = x[n]L n (t)
n=-N](livre1083x.png) | (9.15) |
and it is easy to verify that this is the unique interpolating polynomial of degree 2N in the sense of (9.13). Note that each of the Ln(N)(t) satisfies the interpolation properties (9.12) or, concisely (for Ts = 1):
![(N)
Ln (m ) = δ[n - m]](livre1084x.png)
The interpolation formula, however, cannot be written in the form
of (9.11) since the Lagrange polynomials are not simply shifts of a single
prototype function. The continuous time signal x(t) = P(t) is now a global
interpo-lating function for the finite-length discrete-time signal x[n], in the
sense that it depends on all samples in the signal; as a consequence, x(t) is
maximally smooth (x(t) C∞). An example of Lagrange interpolation for
N = 2 is plotted in Figure 9.5.
|
|
The beauty of local interpolation schemes lies in the fact that the interpolated function is simply a linear combination of shifted versions of the same prototype interpolation function I(t); unfortunately, this has the disadvantage of creating a continuous-time function which lacks smoothness. Polynomial interpolation, on the other hand, is perfectly smooth but it only works in the finite-length case and it requires different interpolation functions with different signal lengths. Yet, both approaches can come together in a convenient mathematical way and we are now ready to introduce the maximally smooth interpolation scheme for infinite discrete-time signals.
Let us take the expression for the Lagrange polynomial of degree N in (9.14) and consider its limit for N going to infinity. We have
| limN→∞Ln(N)(t) | = ∏
k=-∞
k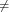 n ∞ n ∞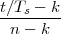 = ∏
m=-∞
m = ∏
m=-∞
m 0 ∞ 0 ∞ | ||
= ∏
m=-∞
m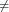 0 ∞ 0 ∞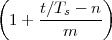 | |||
= ∏
m=1∞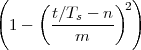 | (9.16) |
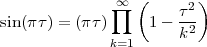
(whose derivation is in the appendix) to finally obtain
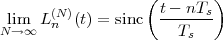 | (9.17) |
The convergence of the Lagrange polynomial L0(N)(t) to the sinc function is illustrated in Figure 9.6. Note that, now, as the number of points becomes infinite, the Lagrange polynomials converge to shifts of the same prototype function, i.e. the sinc; therefore, the interpolation formula can be expressed as in (9.11) with I(t) = sinc(t); indeed, if we consider an infinite sequence x[n] and apply the Lagrange interpolation formula (9.15), we obtain:
![∑∞ (t - nTs)
x(t) = x[n]sinc ---T---
n= -∞ s](livre1096x.png) | (9.18) |
Spectral Properties of the Sinc Interpolation. The sinc interpolation of a discrete-time sequence gives rise to a strictly bandlimited continuous-time function. If the DTFT X(ejω) of the discrete-time sequence exists, the spectrum of the interpolated function X(jΩ) can be obtained as follows:
![∫ ∞ ∞∑ ( t- nTs) - jΩt ∑∞ ∫ ∞ ( t- nTs ) - jΩt
X (jΩ ) = x[n]sinc --T---- e dt = x[n ] sinc --T---- e dt
- ∞ n=-∞ s n=- ∞ -∞ s](livre1098x.png) |
Now we use (9.9) to obtain the Fourier Transform of the scaled and shifted sinc:
![∞∑ ( π ) ( Ω ) -jnT Ω
X (jΩ) = x[n] Ω--- rect 2Ω--- e s
n=-∞ N N](livre1099x.png) |
and use the fact that, as usual, Ts = π∕ΩN:
![(
( ) ( ) ∑∞ { -π--X(ejπΩ∕ΩN ) for |Ω| ≤ ΩN
X (jΩ ) = -π-- rect -Ω--- x [n]e- jπ(Ω∕ΩN)n = ΩN
ΩN 2ΩN n=-∞ ( 0 otherwise](livre1100x.png) |
In other words, the continuous-time spectrum is just a scaled and stretched version of the DTFT of the discrete-time sequence between -π and π. The duration of the interpolation interval Ts is inversely proportional to the resulting bandwidth of the interpolated signal. Intuitively, a slow interpolation (Ts large) results in a spectrum concentrated around the low frequencies; conversely, a fast interpolation (Ts small) results in a spread-out spectrum (more high frequencies are present).(6)
We have seen in the previous Section that the “natural” polynomial interpolation scheme leads to the so-called sinc interpolation for infinite discrete time sequences. Another way to look at the previous result is that any square summable discrete-time signal can be interpolated into a continuous-time signal which is smooth in time and strictly bandlimited in frequency. This suggests that the class of bandlimited functions must play a special role in bridging the gap between discrete and continuous time and this deserves further investigation. In particular, since any discrete-time signal can be interpolated exactly into a bandlimited function, we now ask ourselves whether the converse is true: can any bandlimited signal be transformed into a discrete-time signal with no loss of information?
The Space of Bandlimited Signals. The class of ΩN-bandlimited functions of finite energy forms a Hilbert space, with the inner product defined in (9.1). An orthogonal basis for the space of ΩN-bandlimited functions can easily be obtained from the prototypical bandlimited function, the sinc; indeed, consider the family:
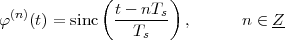 | (9.19) |
where, once again, Ts = π∕ΩN. Note that we have φ(n)(t) = φ(0)(t-nTs) so that each basis function is simply a translated version of the prototype basis function φ(0). Orthogonality can easily be proved as follows: first of all, because of the symmetry of the sinc function and the time-invariance of the convolution, we can write
 φ(n)(t),φ(m)(t) φ(n)(t),φ(m)(t) | =  φ(0)(t - nT
s),φ(0)(t - mT
s) φ(0)(t - nT
s),φ(0)(t - mT
s) | ||
=  φ(0)(nT
s - t),φ(0)(mT
s - t) φ(0)(nT
s - t),φ(0)(mT
s - t) | |||
= (φ(0) * φ(0)) (n - m)T
s (n - m)T
s |
 φ(n)(t),φ(m)(t) φ(n)(t),φ(m)(t) | =  ∫
-∞∞ ∫
-∞∞ 2ejΩ(n-m)Ts
dΩ 2ejΩ(n-m)Ts
dΩ | ||
= 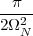 ∫
-ΩNΩN
ejΩ(n-m)Ts
dΩ ∫
-ΩNΩN
ejΩ(n-m)Ts
dΩ | |||
= 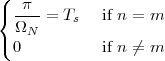 |
 φ(n)(t)
φ(n)(t) nZ is orthogonal with normalization factor ΩN∕π (or,
equivalently, 1∕Ts).
nZ is orthogonal with normalization factor ΩN∕π (or,
equivalently, 1∕Ts).
In order to show that the space of ΩN-bandlimited functions is indeed a Hilbert space, we should also prove that the space is complete. This is a more delicate notion to show(7) and here it will simply be assumed.
Sampling as a Basis Expansion. Now that we have an orthogonal basis, we can compute coefficients in the basis expansion of an arbitrary ΩN-bandlimited function x(t). We have
 φ(n)(t),x(t) φ(n)(t),x(t) | =  φ(0)(t - nT
s),x(t) φ(0)(t - nT
s),x(t) | (9.20) |
=  φ(0) * x φ(0) * x (nT
s) (nT
s) | (9.21) | |
= 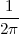 ∫
-∞∞ ∫
-∞∞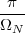 rect rect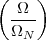 X(jΩ)ejΩnTs
dΩ X(jΩ)ejΩnTs
dΩ | (9.22) | |
= 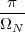 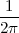 ∫
-ΩNΩN
X(jΩ)ejΩnTs
dΩ ∫
-ΩNΩN
X(jΩ)ejΩnTs
dΩ | (9.23) | |
| = Ts x(nTs) | (9.24) |
Reconstruction of x(t) from its projections can now be achieved via the orthonormal basis reconstruction formula (3.40); since the sinc basis is just orthogonal, rather than orthonormal, (3.40) needs to take into account the normalization factor and we have
| x(t) | = 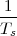 ∑
n=-∞∞ ∑
n=-∞∞ φ(n)(t),x(t) φ(n)(t),x(t) φ(n)(t) φ(n)(t) | ||
= ∑
n=-∞∞x(nT
s)sinc 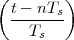 | (9.25) |
The Sampling: Theorem. If x(t) is a ΩN-bandlimited continuous-time signal, a sufficient representation of x(t) is given by the discrete-time signal x[n] = x(nTs), with Ts = π∕ΩN. The continuous time signal x(t) can be exactly reconstructed from the discrete-time signal x[n] as
![( )
∑∞ t---nTs
x(t) = x[n]sinc Ts
n= -∞](livre1133x.png)
The proof of the theorem is inherent to the properties of the Hilbert space of bandlimited functions, and is trivial once having proved the existence of an orthogonal basis. Now, call Ωmax the largest nonzero frequency of a bandlimited signal.(8) Such a signal is obviously ΩN-bandlimited for all ΩN > Ωmax. Therefore, a bandlimited signal x(t) is uniquely represented by all sequences x[n] = x(nT) for which T ≤ Ts = π∕Ωmax; Ts is the largest sampling period which guarantees perfect reconstruction (i.e. we cannot take fewer than 1∕Ts samples per second to perfectly capture the signal; we will see in the next Section what happens if we do). Another way to state the above point is to say that the minimum sampling frequency Ωs for perfect reconstruction is exactly twice the signal’s maximum frequency, or that the Nyquist frequency must coincide to the highest frequency of the bandlimited signal; the sampling frequency Ω must therefore satisfy the following relationship:
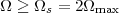
or, in hertz,
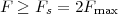
The “naive” notion of sampling, as we have seen, is associated to the very practical idea of measuring the instantaneous value of a continuous-time signal at uniformly spaced instants in time. For bandlimited signals, we have seen that this is actually equivalent to an orthogonal decomposition in the space of bandlimited functions, which guarantees that the set of samples x(nTs) uniquely determines the signal and allows its perfect reconstruction. We now want to address the following question: what happens if we simply sample an arbitrary continuous time signal in the “naive” sense (i.e. in the sense of simply taking x[n] = x(nTs)) and what can we reconstruct from the set of samples thus obtained?
Given a sampling period of Ts seconds, the sampling theorem ensures that there is no loss of information by sampling the class of ΩN-bandlimited signals, where as usual ΩN = π∕Ts. If a signal x(t) is not ΩN-bandlimited (i.e. its spectrum is nonzero at least somewhere outside of [-ΩN,ΩN]) then the approximation properties of orthogonal bases state that its best approximation in terms of uniform samples Ts seconds apart is given by the samples of its projection over the space of ΩN-bandlimited signals (Sect. 3.3.2). This is easily seen in (9.23), where the projection is easily recognizable as an ideal lowpass filtering operation on x(t) (with gain Ts) which truncates its spectrum outside of the [-ΩN,ΩN] interval.
Sampling as the result of a sinc basis expansion automatically includes this lowpass filtering operation; for a ΩN-bandlimited signal, obviously, the filtering is just a scaling by Ts. For an arbitrary signal, however, we can now decompose the sinc sampling as in Figure 9.7, where the first block is a continuous-time lowpass filter with cutoff frequency ΩN and gain Ts = π∕ΩN. The discrete time sequence x[n] thus obtained is the best discrete-time approximation of the original signal when the sampling is uniform.
|
|
Now let us go back to the naive sampling scheme in which simply x[n] = x(nTs), with Fs = 1∕Ts, the sampling frequency of the system; what is the error we incur if x(t) is not bandlimited or if the sampling frequency is less than twice the maximum frequency? We can develop the intuition by starting with the simple case of a single sinusoid before moving on to a formal demonstration of the aliasing phenomenon.
Sampling of Sinusoids. Consider a simple continuous-time signal(9) such as x(t) = ej2πf0t and its sampled version x[n] = ej2π(f0∕Fs)n = ejω0n with
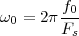 | (9.26) |
Clearly, since x(t) contains only one frequency, it is Ω-bandlimited for all
Ω > 2π|f0|. If the frequency of the sinusoid satisfies |f0| < Fs∕2 = FN, then
ω0 (-π,π) and the frequency of the original sinusoid can be univocally
determined from the sampled signal. Now assume that f0 = FN = Fs∕2; we
have
![jπn -jπn
x[n] = e = e](livre1138x.png)
In other words, we encounter a first ambiguity with respect to the direction of rotation of the complex exponential: from the sampled signal we cannot determine whether the original frequency was f0 = FN or f0 = -FN. If we increase the frequency further, say f0 = (1 + α)FN, we have
![x[n] = ej(1+α)πn = e- jα πn](livre1139x.png)
Now the ambiguity is both on the direction and on the frequency value: if we try to infer the original frequency from the sampled sinusoid from (9.26), we cannot discriminate between f0 = (1 + α)FN or f0 = -αFN. Matters get even worse if f0 > Fs. Suppose we can write f0 = Fs + fb with fb < Fs∕2; we have
![x [n] = ej(2πFsTs+2 πfbTs)n = ej(2π+ ωb)n = ejωbn](livre1140x.png)
so that the sinusoid is completely indistinguishable from a sinusoid of frequency fb sampled at Fs; the fact that two continuous-time frequencies are mapped to the same discrete-time frequency is called aliasing. An example of aliasing is depicted in Figure 9.8.
In general, because of the 2π-periodicity of the discrete-time complex exponential, we can always write
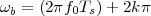
and choose k Z so that ωb falls in the [-π,π] interval. Seen the other way,
all continuous-time frequencies of the form
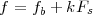
with fb < FN are aliased to the same discrete-time frequency ωb.
|
|
Consider now the signal y(t) = Aej2πfbt + Bej2π(fb+Fs)t, with fb < FN. If we sample this signal with sampling frequency Fs we obtain:
| x[n] | = Aej2π(fb∕Fs)n + B ej2π(fb∕Fs+1)nTs | ||
| = Aejωbn + B ejωbnej2πn | |||
| = (A + B)ejωbn |
Energy Folding of the Fourier Transform. To understand what happens to a general signal, consider the interpretation of the Fourier transform as a bank of (infinitely many) complex oscillators initialized with phase and amplitude, each contributing to the energy content of the signal at their respective frequency. Since, in the sampled version, any two frequencies Fs apart are indistinguishable, their contributions to the discrete-time Fourier transform of the sampled signal add up. This aliasing can be represented as a spectral superposition: the continuous-time spectrum above FN is cut, shifted back to -FN, summed over [-FN,FN], and the process is repeated again and again; the same applies for the spectrum below -FN. This process is nothing but the familiar periodization of a signal:
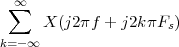
as we will prove formally in the next Section.
In the following, we consider the relationship between the DTFT of a sampled signal x[n] and the FT of the originating continuous-time signal xc(t). For clarity, we add the subscript “c” to all continuous-time quantities so that, for instance, we write x[n] = xc(nTs). Moreover, we use the usual tilde notation for periodic functions.
Consider X(ejω), the DTFT of the sampled sequence (with, as usual, Ts = (1∕Fs) = (π∕ΩN)). The inversion formula states:
![∫
-1- π jω jωn
x[n ] = 2π -π X (e ) e dω](livre1145x.png) | (9.27) |
We will use this result later. We can also arrive at an expression for x[n] from Xc(jΩ), the Fourier transform of the continuous-time function xc(t); indeed, by writing the formula for the inverse continuous-time Fourier transform computed in nTs we can state that:
![1 ∫ ∞
x[n] = xc(nTs ) =--- Xc(jΩ )ejΩ nTs dΩ
2π - ∞](livre1146x.png) | (9.28) |
The idea is to split the integration interval in the above expression as the sum of non-overlapping intervals whose width is equal to the sampling bandwidth Ωs = 2ΩN; this stems from the realization that, in the inversion process, all frequencies Ωs apart give indistinguishable contributions to the discrete-time spectrum. We have
![∞ ∫ (2k+1)Ω
x[n ] =-1- ∑ NX (jΩ)ejΩ nTs dΩ
2π (2k-1)ΩN c
k=-∞](livre1147x.png) |
which, by exploiting the Ωs-periodicity of ejΩ nTs (i.e. ej(Ω+kΩs)nTs = ejΩnTs), becomes
![∑∞ ∫ ΩN
x [n] = -1- Xc(jΩ - jkΩs) ejΩ nTs dΩ
2π k=-∞ - ΩN](livre1148x.png) | (9.29) |
Now we interchange the order of integration and summation (this can be done under fairly broad conditions for xc(t)):
![{ }
1 ∫ ΩN ∑∞ jΩnT
x[n ] = 2π Xc(jΩ - jkΩs) e s dΩ
- ΩN k=- ∞](livre1149x.png) | (9.30) |
and if we define the periodized function:
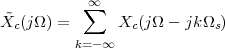
![∫ ΩN
x[n ] =-1- X˜c (jΩ)ejΩ nTs dΩ
2π -ΩN](livre1151x.png) | (9.31) |
after which, finally, we operate the change of variable θ = ΩTs:
![1 ∫ π 1 ( θ )
x[n] =--- ---X˜c j --- ejθn dθ
2 π -πTs Ts](livre1152x.png) | (9.32) |
It is immediately verifiable that 
 j(θ∕Ts)
j(θ∕Ts) is now 2π-periodic in θ. If
we now compare (9.32) to (9.27) we can easily see that (9.32) is nothing but
the DTFT inversion formula for the 2π-periodic function (1∕Ts)
is now 2π-periodic in θ. If
we now compare (9.32) to (9.27) we can easily see that (9.32) is nothing but
the DTFT inversion formula for the 2π-periodic function (1∕Ts) (jθ∕Ts);
since the inversion formulas (9.32) and (9.27) yield the same result (namely,
x[n]) we can conclude that:
(jθ∕Ts);
since the inversion formulas (9.32) and (9.27) yield the same result (namely,
x[n]) we can conclude that:
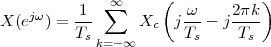 | (9.33) |
which is the relationship between the Fourier transform of a continuous-time function and the DTFT of its sampled version, with Ts being the sampling period. The above result is a particular version of a more general result in Fourier theory called the Poisson sum formula. In particular, when xc(t) is ΩN-bandlimited, the copies in the periodized spectrum do not overlap and the (periodic) discrete-time spectrum between -π and π is simply
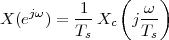 | (9.34) |
Figures 9.9 to 9.12 illustrate several examples of the relationship between the
continuous-time spectrum and the discrete-time spectrum. For all figures, the
top panel shows the continuous-time spectrum X(jΩ), with labels indicating
the Nyquist frequency and the sampling frequency. The middle panel shows
the periodized function 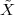 c(jΩ); the single copies are plotted with a
dashed line (they are not be visible if there is no overlap) and their
sum is plotted in gray, with the main period highlighted in black.
Finally, the last panel shows the DTFT after sampling over the [-π,π]
interval.
c(jΩ); the single copies are plotted with a
dashed line (they are not be visible if there is no overlap) and their
sum is plotted in gray, with the main period highlighted in black.
Finally, the last panel shows the DTFT after sampling over the [-π,π]
interval.
Oversampling. Figure 9.9 shows the result of sampling a bandlimited signal with a sampling frequency in excess of the minimum (in this case, ΩN = 3Ωmax∕2); in this case we say that the signal has been oversampled. The result is that, in the periodized spectrum, the copies do not overlap and the discrete-time spectrum is just a scaled version of the original spectrum (with even a narrower support than the full [-π,π] range because of the oversampling; in this case ωmax = 2π∕3).
|
|
Critical Sampling. Figure 9.10 shows the result of sampling a bandlimited signal with a sampling frequency exactly equal to twice the maximum frequency; in this case we say that the signal has been critically sampled. In the periodized spectrum, again the copies do not overlap and the discrete-time spectrum is a scaled version of the original spectrum occupying the whole [-π,π] range.
Undersampling (Aliasing). Figure 9.11 shows the result of sampling a bandlimited signal with a sampling frequency less than twice the maximum frequency. It this case, copies do overlap in the periodized spectrum and the resulting discrete-time spectrum is an aliased version of the original; the original spectrum cannot be reconstructed from the sampled signal. Note, in particular, that the original lowpass shape is now a highpass shape in the sampled domain (energy at ω = π is larger than at ω = 0).
|
|
Sampling of Non-Bandlimited Signals. Finally, Figure 9.12 shows the result of sampling a non-bandlimited signal with a sampling frequency which is chosen as a tradeoff between alias and number of samples per second. The idea is to disregard the low-energy “tails” of the original spectrum so that their alias does not exceedingly corrupt the discrete-time spectrum. In the periodized spectrum, the copies do overlap and the resulting discrete-time spectrum is an aliased version of the original, which is similar to the original; however, the original spectrum cannot be reconstructed from the sampled signal. In a practical sampling scenario, the correct design choice would have been to lowpass filter (in the continuous-time domain) the original signal so as to eliminate the spectral tails beyond ± ΩN.
Example 9.1: Another way to aliasing
Consider a real function f(t) for which the Fourier transform is well defined:
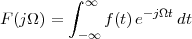 | (9.35) |
Suppose that we only possess a sampled version of f(t), that is, we only know the numeric value of f(t) at times multiples of a sampling interval Ts and that we want to obtain an approximation of the Fourier transform above.
Assume we do not know about the DTFT; an intuitive (and standard) place to start is to write out the Fourier integral as a Riemann sum:
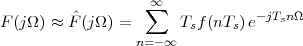 | (9.36) |
indeed, this expression only uses the known sampled values of f(t). In order to understand whether (9.36) is a good approximation consider the periodization of F(jΩ):
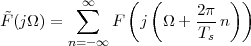 | (9.37) |
in which F(jΩ) is repeated with overlap with period 2π∕Ts. We will show that:
that is, the Riemann approximation is equivalent to a periodization of the original Fourier transform; in mathematics this is known as a particular form of the Poisson sum formula.
To see this, consider the periodic nature of  (jΩ) and remember
that any periodic function f(x) of period L admits a Fourier series
expansion:
(jΩ) and remember
that any periodic function f(x) of period L admits a Fourier series
expansion:
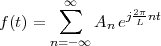 | (9.38) |
where
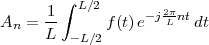 | (9.39) |
Here’s the trick: we regard  (jΩ) as an anonymous periodic complex
function and we compute its Fourier series expansion coefficients. If we
replace L by 2π∕Ts in (9.39) we can write
(jΩ) as an anonymous periodic complex
function and we compute its Fourier series expansion coefficients. If we
replace L by 2π∕Ts in (9.39) we can write
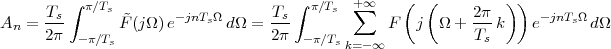 |
By inverting integral and summation, which we can do if the Fourier transform (9.36) is well defined:
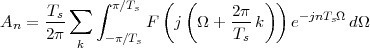 |
and, with the change of variable Ω′ = Ω + (2π∕Ts)k,
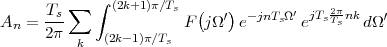 |
where ejTs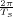 nk = 1. The integrals in the sum are on contiguous and
non-overlapping intervals, therefore:
nk = 1. The integrals in the sum are on contiguous and
non-overlapping intervals, therefore:
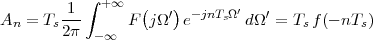 |
so that by replacing the values for all the An in (9.38) we obtain
 (jΩ) =
(jΩ) =  (jΩ).
(jΩ).
What we just found is another derivation of the aliasing formula. Intuitively, there is a duality between the time domain and the frequency domain in that a discretization of the time domain leads to a periodization of the frequency domain; similarly, a discretization of the frequency domain leads to a periodization of the time domain (think of the DFS and see also Exercise 9.9).
Example 9.2: Time-limited vs. bandlimited functions
The trick of periodizing a function and then computing its Fourier series expansion comes very handy in proving that a function cannot be bandlimited and have a finite support at the same time. The proof is by contradiction and goes as follows: assume f(t) has finite support

assume that f(t) has a well-defined Fourier transform:
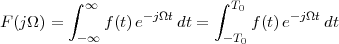
and that it is also bandlimited so that:

Now consider the periodized version:
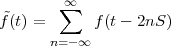
since f(t) = 0 for |t| > T0, if we choose S > T0 the copies in the sum do not
overlap, as shown in Figure 9.13. If we compute the Fourier series
expansion (9.39) for the 2S-periodic 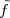 (t) we have
(t) we have
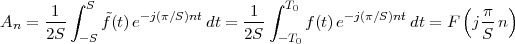 |
Since we assumed that f(t) is bandlimited, it is
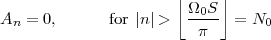
and therefore we can write the reconstruction formula (9.38):
Now consider the complex-valued polynomial of degree 2N0 + 1
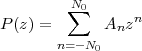
obviously P ej(π∕S)t
ej(π∕S)t =
= 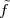 (t) but we also know that
(t) but we also know that  (t) is identically zero
over the [T0 , 2S -T0] interval (Fig. 9.13). Now, a finite-degree polynomial
P(z) has only a finite number of roots and therefore it cannot be identically
zero over an interval unless it is zero everywhere (see also Example 6.2).
Hence, either f(t) = 0 everywhere or f(t) cannot be both bandlimited and
time-limited.
(t) is identically zero
over the [T0 , 2S -T0] interval (Fig. 9.13). Now, a finite-degree polynomial
P(z) has only a finite number of roots and therefore it cannot be identically
zero over an interval unless it is zero everywhere (see also Example 6.2).
Hence, either f(t) = 0 everywhere or f(t) cannot be both bandlimited and
time-limited.
The goal is to prove the product expansion
 | (9.40) |
We present two proofs; the first was proposed by Euler in 1748 and, while it certainly lacks rigor by modern standards, it has the irresistible charm of elegance and simplicity in that it relies only on basic algebra. The second proof is more rigorous, and is based on the theory of Fourier series for periodic functions; relying on Fourier theory, however, hides most of the convergence issues.
Euler’s Proof. Consider the N roots of unity for N odd. They comprise z = 1 plus N - 1 complex conjugate roots of the form z = e±jωNk for k = 1,…, (N - 1)∕2 and ωN = 2π∕N. If we group the complex conjugate roots pairwise we can factor the polynomial zN - 1 as
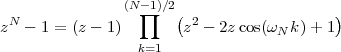
The above expression can immediately be generalized to
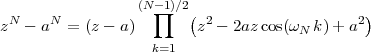
Now replace z and a in the above formula by z = (1 + x∕N) and a = (1 - x∕N); we obtain the following:
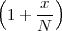 N - N -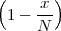 N = N = | |||
= 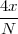 ∏
k=1(N-1)∕2 ∏
k=1(N-1)∕2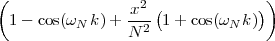 | |||
= 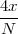 ∏
k=1(N-1)∕2 ∏
k=1(N-1)∕2 1 - cos(ω
Nk) 1 - cos(ω
Nk) 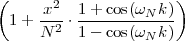 | |||
= Ax∏
k=1(N-1)∕2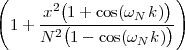 |
 1 - cos(ωNk)
1 - cos(ωNk) . The
value A is also the coefficient for the degree-one term x in the right-hand side
and it can be easily seen from the expansion of the left hand-side that A = 2
for all N; actually, this is an application of Pascal’s triangle and it was
proven by Pascal in the general case in 1654. As N grows larger we have
that:
. The
value A is also the coefficient for the degree-one term x in the right-hand side
and it can be easily seen from the expansion of the left hand-side that A = 2
for all N; actually, this is an application of Pascal’s triangle and it was
proven by Pascal in the general case in 1654. As N grows larger we have
that:
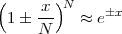
and at the same time, if N is large, then ωN = 2π∕N is small and, for small values of the angle, the cosine can be approximated as
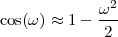
so that the denominator in the general product term can, in turn, be approximated as
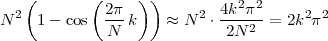
By the same token, for large N, the numerator can be approximated as 1 + cos((2π∕n)k) ≈ 2 and therefore (by bringing A = 2 over to the left-hand side) the above expansion becomes
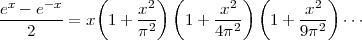
Finally, we replace x by jπt to obtain:
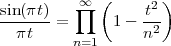
Rigorous Proof. Consider the Fourier series expansion of the even function f(x) = cos(τx) periodized over the interval [-π,π]. We have
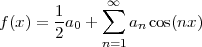
with
| an | =  ∫
-ππ cos(τx)cos(nx)dx ∫
-ππ cos(τx)cos(nx)dx | ||
=  ∫
0π ∫
0π  dx dx | |||
=  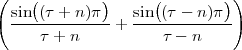 | |||
= 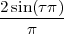 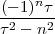 |
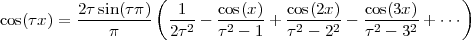
In particular, for x = π we have
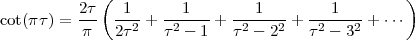
which we can rewrite as
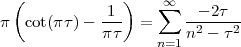
If we now integrate between 0 and t both sides of the equation we have
![∫ ( ) | [ ]
t -1- sin(πτ)||t sin(πt-)
0 cot(π τ)- π τ dπτ = ln πτ | = ln πt
0](livre1234x.png)
and
![∫ ∞ ∞ [ ] [ ∞ ( )]
t ∑ --- 2τ- ∑ t2- ∏ t2-
0 n2 - τ2 d τ = ln 1 - n2 = ln 1 - n2
n=1 n=1 n=1](livre1235x.png)
from which, finally,
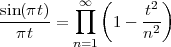
The sampling theorem is often credited to C. Shannon, and indeed it appears with a sketchy proof in his foundational 1948 paper “A Mathematical Theory of Communication”, Bell System Technical Journal, Vol. 27, 1948, pp. 379-423 and pp. 623-656. Contemporary treatments can be found in all signal processing books, but also in more mathematical texts, such as S. Mallat’s A Wavelet Tour of Signal Processing (Academic Press, 1998), or the soon to be published The World of Fourier and Wavelets by M. Vetterli, J. Kovacevic and V. Goyal. These more modern treatments take a Hilbert space point of view, which allows the generalization of sampling theorems to more general spaces than just bandlimited functions.
Exercise 9.1: Zero-order hold. Consider a discrete-time sequence x[n] with DTFT X(ejω). Next, consider the continuous-time interpolated signal
![∑∞
x0(t) = x[n]rect(t- n)
n=-∞](livre1237x.png)
i.e. the signal interpolated with a zero-centered zero-order hold and T = 1 sec.
![∑
x (t) = x[n]sinc(t- n)
n∈Z-](livre1238x.png)
Comment on the result: you should point out two major problems.
So, as it appears, interpolating with a zero-order hold introduces a distortion in the interpolated signal with respect to the sinc interpolation in the region -π ≤ Ω ≤ π. Furthermore, it makes the signal non-bandlimited outside the region -π ≤ Ω ≤ π. The signal x(t) can be obtained from the zero-order hold interpolation x0(t) as x(t) = x0(t) * g(t) for some filter g(t).
Exercise 9.2: A bizarre interpolator. Consider the local interpolation scheme of the previous exercise but assume that the characteristic of the interpolator is the following:

This is a triangular characteristic with the same support as the zero-order hold. If we pick an interpolation interval Ts and interpolate a given discrete-time signal x[n] with I(t), we obtain a continuous-time signal:
![( )
x (t) = ∑ x[n]I t--nTs-
Ts
n](livre1240x.png)
which looks like this:
|
|
Assume that the spectrum of x[n] between -π and π is
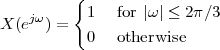
(with the obvious 2π-periodicity over the entire frequency axis).
Exercise 9.3: Another view of sampling. One of the standard ways of describing the sampling operation relies on the concept of “modulation by a pulse train”. Choose a sampling interval Ts and define a continuous-time pulse train p(t) as
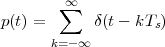
The Fourier Transform of the pulse train is
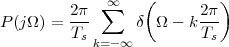
This is tricky to show, so just take the result as is. The “sampled” signal is simply the modulation of an arbitrary-continuous time signal x(t) by the pulse train:
Note that, now, this sampled signal is still continuous time but, by the properties of the delta function, is non-zero only at multiples of Ts; in a sense, xs(t) is a discrete-time signal brutally embedded in the continuous time world. Here is the question: derive the Fourier transform of xs(t) and show that if x(t) is bandlimited to π∕Ts then we can reconstruct x(t) from xs(t).
Exercise 9.4: Aliasing can be good! Consider a real, continuous-time signal xc(t) with the following spectrum Xc(jΩ):
|
|
Exercise 9.5: Digital processing of continuous-time signals. For your birthday, you receive an unexpected present: a 4 MHz A/D converter, complete with anti-aliasing filter. This means you can safely sample signals up to a frequency of 2 MHz; since this frequency is above the AM radio frequency band, you decide to hook up the A/D to your favorite signal processing system and build an entirely digital radio receiver. In this exercise we will explore how to do so.
Simply, assume that the AM radio spectrum extends from 1 Mhz to 1.2 Mhz and that in this band you have ten channels side by side, each one of which occupies 20 KHz.
The first thing that you need to do is to find a way to isolate the channel you want to listen to and to eliminate the rest. For this, you need a bandpass filter centered on the band of interest. Of course, this filter must be tunable in the sense that you must be able to change its spectral location when you want to change station. An easy way to obtain a tunable bandpass filter is by modulating a lowpass filter with a sinusoidal oscillator whose frequency is controllable by the user:
Now that you know how to select a channel, all that is left to do is to demodulate the signal and feed it to a D/A converter and to a loudspeaker.
The whole receiver now works at a rate of 4 MHz; since it outputs audio signals, this is clearly a waste.
Exercise 9.6: Acoustic aliasing. Assume x(t) is a continuous-time pure sinusoid at 10 KHz. It is sampled with a sampler at 8 KHz and then interpolated back to a continuous-time signal with an interpolator at 8 KHz. What is the perceived frequency of the interpolated sinusoid?
Exercise 9.7: Interpolation subtleties. We have seen that any discrete-time sequence can be sinc-interpolated into a continuous-time signal which is ΩN-bandlimited; ΩN depends on the interpolation interval Ts via the relation ΩN = π∕Ts.
Consider the continuous-time signal xc(t) = e-t∕Ts and the discrete-time sequence x[n] = e-n. Clearly, xc(nTs) = x[n]; but, can we also say that xc(t) is the signal we obtain if we apply sinc interpolation to the sequence x[n] = e-n with interpolation interval Ts? Explain in detail.
Exercise 9.8: Time and frequency. Consider a real continuous-time signal x(t). All you know about the signal is that x(t) = 0 for |t| > t0. Can you determine a sampling frequency Fs so that when you sample x(t), there is no aliasing? Explain.
Exercise 9.9: Aliasing in time? Consider an N-periodic discrete-time
signal  [n], with N an even number, and let
[n], with N an even number, and let 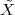 [k] be its DFS:
[k] be its DFS:
![N∑-1 2π-
˜X[k] = x˜[n]e- jN nk , k ∈ Z-
n=0](livre1249x.png)
Let Ỹ[m] =  [2m], i.e. a “subsampled” version of the DFS coefficients;
clearly this defines a (N∕2)-periodic sequence of DFS coefficients. Now
consider the (N∕2)-point inverse DFS of Ỹ[m] and call this (N∕2)-periodic
signal ỹ[n]:
[2m], i.e. a “subsampled” version of the DFS coefficients;
clearly this defines a (N∕2)-periodic sequence of DFS coefficients. Now
consider the (N∕2)-point inverse DFS of Ỹ[m] and call this (N∕2)-periodic
signal ỹ[n]:
![N∕2-1
-2 ∑ ˜ j 2Nπ∕2nk
˜y[n] = N Y [k]e , n ∈ Z-
k=0](livre1251x.png)
Express ỹ[n] in terms of 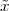 [n] and describe in a few words what has
happened to
[n] and describe in a few words what has
happened to  [n] and why.
[n] and why.
| © Presses polytechniques et universitaires romandes, 2008 All rights reserved |
The word “digital” in “digital signal processing” indicates that, in the representation of a signal, both time and amplitude are discrete quantities. The necessity to discretize the amplitude values of a discrete-time signal comes from the fact that, in the digital world, all variables are necessarily represented with a finite precision. Specifically, general-purpose signal processors are nothing but streamlined processing units which address memory locations whose granularity is an integer number of bits. The conversion from the “real world” analog value of a signal to its discretized digital counterpart is called analog-to-digital (A/D) conversion. Analogously, a transition in the opposite direction is shorthanded as a D/A conversion; in this case, we are associating a physical analog value to a digital internal representation of a signal sample. Note that, just as was the case with sampling, quantization and its inverse lie at the boundary between the analog and the digital world and, as such, they are performed by actual pieces of complex, dedicated hardware.
The sampling theorem described in Chapter 9 allowed us to represent a
bandlimited signal by means of a discrete-time sequence of samples taken at
instants multiple of a sampling period Ts. In order to store or process this
sequence of numbers x[n] = x(nTs), n Z, we need to transform the real
values x[n] into a format which fits the memory model of a computer; two
such formats are, for instance, finite-precision integers or finite-precision
floating point numbers (which are nothing but integers associated to a scale
factor). In both cases, we need to map the real line or an interval thereof
(i.e. the range of x(t)) onto a countable set of values. Unfortunately, because
of this loss of dimensionality, this mapping is irreversible, which leads
to approximation errors. Consider a bandlimited input signal x(t),
whose amplitude is known to vary between the values A and B. After
sampling, each sample x[n] will have to be stored as a R-bit integer,
i.e. as one out of K = 2R possible values. An intuitive solution is to
divide the [A,B] interval into K non-overlapping subintervals Ik such
that
![K- 1
⋃ I = [A, B]
k
k=0](livre1254x.png)
The intervals are defined by K + 1 points ik so that for each interval we can write
![Ik = [ik,ik+1], k = 0,1,...,K - 1](livre1255x.png)
So i0 = A, iK = B, and i0 < i1 < … < iK-1 < iK. An example of this subdivision for R = 2 is shown in Figure 10.1 in which, arbitrarily. In order to map the input samples to a set of integers, we introduce the following quantization function:
![{ } { || }
Q x[n] = k x[n ] ∈ Ik](livre1256x.png) | (10.1) |
In other words, quantization associates to the sample value x[n], the integer index of the interval onto which x[n] “falls”. One of the fundamental questions in the design of a good quantizer is how to choose the splitting points ik for a given class of input signals as well as the reconstruction values.
|
|
Quantization Error. Since all the (infinite) values falling onto the interval Ik are mapped to the same index, precious information is lost. This introduces an error in the quantized representation of a signal which we analyze in detail in the following and which we will strive to minimize. Note that quantization is a highly nonlinear operation since, in general,
![{ } { } { }
Q x[n ]+ y[n ] ⁄= Q x[n] + Q y [n]](livre1259x.png)
This is related to the quantization error since, if a Ik and a + b Ik then
{a + b} = {a}; small perturbations in the signal are lost in quantization.
On the other hand, consider a constant signal x[n] = im for some m < K
(i.e. the value of the signal coincides with the lower limit of one of the
quantization intervals); consider now a small “perturbation” noise sequence
ε[n], with uniform distribution over [-U,U] and U arbitrarily small. The
quantized signal:
![{
Q{x [n]+ ε[n]} = k - 1 if ε[n ] ≤ 0
k if ε[n ] > 0](livre1260x.png)
In other words, the quantized signal will oscillate randomly with 50% chance between two neighboring quantization levels. This can create disruptive artifacts in a digital signal, and it is counteracted by special techniques called dithering for which we refer to the bibliography.
Reconstruction. The output of a quantizer is an abstract internal
representation of a signal, where actual values are replaced by (binary)
indices. In order to process or interpolate back such a signal, we need to
somehow “undo” the quantization and, to achieve this, we need to
associate back a physical value to each of the quantizer’s indices.
Reconstruction is entirely dependent on the original quantizer and,
intuitively, it is clear that the value 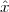 k which we associate to index k should
belong to the interval Ik. For example, in the absence of any other
information on x[n], it is reasonable to choose the interval’s midpoint as
the representative value. In any case, the reconstructed signal will
be
k which we associate to index k should
belong to the interval Ik. For example, in the absence of any other
information on x[n], it is reasonable to choose the interval’s midpoint as
the representative value. In any case, the reconstructed signal will
be
![{ { }}
ˆx[n] = xˆk, k = Q x[n]](livre1262x.png) | (10.2) |
and the second fundamental question in quantizer design is how to choose
the representative values 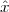 k so that the quantization error is minimized. The
error introduced by the whole quantization/reconstruction chain can
therefore be written out as
k so that the quantization error is minimized. The
error introduced by the whole quantization/reconstruction chain can
therefore be written out as
![e[n] = E (x[n ]) = (ˆx[n]- x[n])](livre1264x.png) | (10.3) |
For a graphical example see Figure 10.2. Note that, often, with an abuse of notation, we will use the term “quantized signal” to indicate the sequence
of reconstruction values associated to the sequence of quantization indices as produced by the quantizer. In other words, we will often imply, for short,
![{ }
ˆx[n] = Q x[n]](livre1266x.png)
Quantization, as we mentioned, is a non-linear operation and it is therefore quite difficult to analyze in general; the goal is to obtain some statistical description of the quantization error for classes of stochastic input signals. In order to make the problem tractable and solvable, and thus gain some precious insight on the mathematics of quantization, simplified models are often used. The simplest such model is the uniform scalar quantization scenario. By scalar quantization, we indicate that each input sample x[n] is quantized independently; more sophisticated techniques would take advantage of the correlation between neighboring samples to perform a joint quantization which goes under the name of “vector quantization”. By uniform quantization, we indicate the key design choices for quantization and reconstruction: given a budget of R bits per sample (known as the rate of the digital signal), we will be able to quantize the input signal into K = 2R distinct levels; in order to do so we need to split the range of the signal into K intervals. It is immediately clear that such intervals should be disjoint (as to have a unique quantized value for each input value) and they should cover the whole range of the input. In the case of uniform quantization the following design is used:
R.
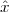 k is chosen to be the midpoint of the
corresponding interval Ik.
k is chosen to be the midpoint of the
corresponding interval Ik.An example of the input/output characteristic of a uniform quantizer is shown in Figure 10.3 for a rate of 3 bits/sample and a signal limited between -1 and 1.
Uniform Quantization of a Uniformly Distributed Input. In order to precisely evaluate the distortion introduced by a quantization and reconstruction chain we need to formulate some assumption on the statistical properties of the input signal. of the input signal. Let us start with a discrete-time signal x[n] with the following characteristics:
|
|
While simple, this signal model manages to capture the essence of many real-world quantization problems. For a uniformly distributed input signal, the design choices of a uniform quantizer turn out to be optimal with respect to the minimization of the power of the quantization error Pe. If we consider the expression for the power
![[| | ] ∫ B
Pe = E |e[n]|2 = ---1-- E2(x)dx
A B - A](livre1270x.png) | (10.4) |
and we remark that the error function localizes over the quantization intervals as
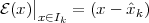
then we can split the above integral as
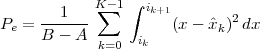 | (10.5) |
where ik = A + kΔ, xk = ik + Δ∕2 and Δ = (B - A)∕K. In order
to show that the quantizer is optimal, we need to show that these
values for ik and  k lie at a minimum for the error function Pe or,
in other words, that they are a solution to the following system of
equations:
k lie at a minimum for the error function Pe or,
in other words, that they are a solution to the following system of
equations:
 | (10.6) |
By plugging (10.5) into the first equation in (10.6) we have
 |
The same can easily be verified for the second equation in (10.6).
Finally, we can determine the power of the quantization error:
| Pe | = ∑
k=0K-1E![[( )2 || ]
x[n]- xk | x [n] ∈ Ik](livre1276x.png) P P x[n] Ik x[n] Ik![]](livre1278x.png) | ||
= ∫
-Δ∕2Δ∕2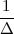 x2 dx x2 dx | |||
= 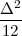 | (10.7) |
 x[n] Ik
x[n] Ik![]](livre1282x.png) = 1∕K for all k. If we consider the average power (i.e. the
variance) of the input signal:
= 1∕K for all k. If we consider the average power (i.e. the
variance) of the input signal:
![2 [ 2 ] (B---A-)2
σx = E x [n] = 12](livre1283x.png)
and we use the fact that Δ = (B - A)∕K = (B - A)∕2R, we can write
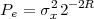 | (10.8) |
This exponential decay of the error, as a function of the rate, is a key concept, not only with respect to quantization but, much more generally, with respect to data compression. Finally, if we divide by the power of the input signal, we can arrive at a convenient and compact expression for the signal to noise ratio of the digital signal:
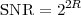 | (10.9) |
If we express the SNR in dB, the above equation becomes:
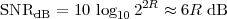 | (10.10) |
This provides us with an extremely practical rule of thumb for the distortion caused by quantization: each additional bit per sample improves the SNR by 6 dB. A compact disk, for instance, which uses a quantization of 16 bits per sample, has an SNR (or maximum dynamic range) of approximately 96 dB. Remember, however, that the above expression has been derived under very unrealistic assumptions for the input signal, the most limiting of which is that input samples are uncorrelated, which makes the quantization error uncorrelated as well. This, is of course, far from true in any non-noise signal so that the 6 dB/bit rule must be treated as a rough estimate.
Uniform Quantization of Normally Distributed Input. Consider now a more realistic distribution for the input signal x[n], namely the Gaussian distribution; the input signal is now assumed to be white Gaussian noise of variance σ2. Suppose we fix the size of the quantization interval Δ; since, in this case, the support of the probability density function is infinite, we either need an infinite number of bins (and therefore an infinite rate), or we need to “clip” x[n] so that all values fall within a finite interval. In the purely theoretical case of an infinite number of quantization bins, it can be proven that the error power for a zero-mean Gaussian random variable of variance σ2 quantized into bins of size Δ is
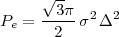 | (10.11) |
In a practical system, when a finite number of bins is used, x[n] is clipped outside of an [A,B] interval, which introduces an additional error, due to the loss of the tails of the distribution. It is customary to choose B = -A = 2σ; this is an instance of the so-called “4σ rule”, stating that over 99.5% of the probability mass of a zero-mean Gaussian variable with variance σ2 is comprised between -2σ and 2σ. With this choice, and with a rate of R bits per sample, we can build a uniform quantizer with Δ = 4σ∕2R. The total error power increase because of clipping but not by much; essentially, the behavior is still given by an expression similar to (10.11) which, expressed as a function of the rate, can be written as
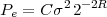 | (10.12) |
where C is a constant larger but of the same order as 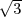 π∕2 = 2.72 in
(10.11). Again, the signal to noise ratio turns out to be an exponentially
increasing function of the rate
π∕2 = 2.72 in
(10.11). Again, the signal to noise ratio turns out to be an exponentially
increasing function of the rate
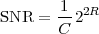
with only a constant to reduce performance with respect to the uniformly distributed input. Again, the 6 dB/bit rule applies, with the usual caveats.
The Lloyd-Max algorithm is a procedure to design an optimal quantizer for an input signal with an arbitrary (but known) probability density function. The starting hypotheses for the Lloyd-Max procedure are the following:
Under these assumptions the idea is to solve a system of equations similar to (10.6) where, in this case, the pdf for the input is explicit in the error integral. The solution defines the optimal quantizer for the given input distribution, i.e. the quantizer which minimizes the associated error.
The error can be expressed as
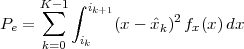 | (10.13) |
where now the only known parameters are K, i0 = A and iK = B and we must solve
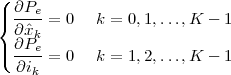 | (10.14) |
The first equation can be efficiently solved noting that only one term
in (10.13) depends on 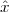 k for a given value of k. Therefore:
k for a given value of k. Therefore:
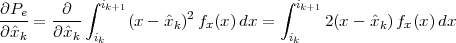 |
which gives the optimal value for  k as
k as
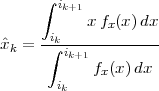 | (10.15) |
Note that the optimal value is the center of mass of the input distribution
over the quantization interval: 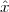 k = E[x|ik ≤ x ≤ ik+1]. Similarly, we can
determine the boundaries of the quantization intervals as
k = E[x|ik ≤ x ≤ ik+1]. Similarly, we can
determine the boundaries of the quantization intervals as
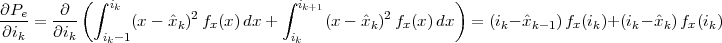 |
from which
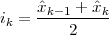 | (10.16) |
i.e. the optimal boundaries are the midpoints between optimal quantization points. The system of Equations (10.15) and (10.16) can be solved (either exacly or, more often, iteratively) to find the optimal parameters. In practice, however, the SNR improvement introduced by a Lloyd-Max quantizer does not justify an ad-hoc hardware design effort and uniform quantizers are used almost exclusively in the case of scalar quantization.
The process which transforms an analog continuous-time signal into a digital discrete-time signal is called analog-to-digital (A/D) conversion. Again, it is important to remember that A/D conversion is the operation that lies at the interface between the analog and the digital world and, therefore, it is performed by specialized hardware which encode the instantaneous voltage values of an electrical signal into a binary representation suitable for use on a general-purpose processor. Once a suitable sampling frequency Fs has been chosen, the process is composed of four steps in cascade.
Analog Lowpass Filtering. An analog lowpass with cutoff Fs∕2 is a necessary step even if the analog signal is virtually bandlimited because of the noise: we need to eliminate the high-frequency noise which, because of sampling, would alias back into the signal’s bandwidth. Since sharp analog lowpass filters are “expensive”, the design usually allows for a certain amount of slack by choosing a sampling frequency higher than the minimum necessary.
Sample and Hold. The input signal is sampled by a structure similar to
that in Figure 10.4. The FET T1 acts as a solid-state switch and it is driven
by a train of pulses k(t) generated by a very stable crystal oscillator. The
pulses arrive Fs times per second and they cause T1 to close briefly so that
the capacitor C1 is allowed to charge to the instantaneous value of the
input signal xc(nTs) (in Volts); the FET then opens immediately
and the capacitor remains charged to xc(nTs) over the time interval
 nTs,(n + 1)Ts
nTs,(n + 1)Ts![]](livre1301x.png) . The key element of the sample-and-hold circuit is
therefore the capacitor, acting as an instantaneous memory element
for the input signal’s voltage value, while the op-amps provide the
necessary high-impedance interfaces to the input signal and to the
capacitor. The continuous-time signal produced by this structure
looks like the output of a zero-order hold interpolator (Fig. 9.1);
availability of a piecewise-constant signal between sampling instants is
necessary to allow the next steps in the chain to reach a stable output
value.
. The key element of the sample-and-hold circuit is
therefore the capacitor, acting as an instantaneous memory element
for the input signal’s voltage value, while the op-amps provide the
necessary high-impedance interfaces to the input signal and to the
capacitor. The continuous-time signal produced by this structure
looks like the output of a zero-order hold interpolator (Fig. 9.1);
availability of a piecewise-constant signal between sampling instants is
necessary to allow the next steps in the chain to reach a stable output
value.
Clipping. Clipping limits the range of the voltages which enter the quantizer. The limiting function can be a hard threshold or, as in audio applications, a function called compander where the signal is leveled towards a maximum via a smooth function (usually a sigmoid).
Quantization. The quantizer, electrically connected (via the clipper) to the output of the sample-and-hold, is a circuit which follows the lines of the schematics in Figure 10.6. This is called a flash (or parallel) quantization scheme because the input sample is simultaneously compared to all of the quantization thresholds ik. These are obtained via a voltage divider realized by the cascade of equally-valued resistors shown on the left of the circuit. In this simple example, the signal is quantized over the [-V 0,V 0] interval with 2 bits per sample and therefore four voltage levels are necessary. To use the notation of Section 10.1 we have that i0 = -V 0, i1 = -0.5V 0, i2 = 0, i3 = 0.5V 0, and i4 = V 0. These boundary voltages are fed to a parallel structure of op-amps acting as comparators; all the comparators, for which the reference voltage is less than the input voltage, will have a high output and the logic (XOR gates and diodes) will convert these high outputs into the proper binary value (in this case, a least significant and most significant bit (LSB and MSB)). Because of their parallel structure, flash quantizers exhibit a very short response time which allows their use with high sampling frequencies. Unfortunately, they require an exponentially increasing number of components per output bit (the number of comparators is on the order of 2B where B is the rate of the signal in bits per sample). Other architectures are based on iterative conversion techniques; while they require fewer components, they are typically slower.
In the simplest case, digital-to-analog (D/A) conversion is performed by a circuit which translates the binary internal representation of the samples into a voltage output value; the voltage is kept constant between interpolation times, thereby producing a zero-order-hold interpolated signal. Further analog filtering may be employed to reduce the artifacts of the interpolation (Sect. 11.4.2).
A typical example of D/A circuitry is shown in Figure 10.6.
The op-amp is configured as a voltage adder and is connected
to a standard R/2R ladder. The ladder has as many “steps” as
the number of bits B used to encode each sample of the digital
signal.(1)
Each bit is connected to a non-inverting buffer which acts as a switch: for
each “1” bit, the voltage V 0 is connected to the associated step of the ladder,
while for each “0” bit the step is connected to the ground. By repeatedly
applying Thevenin’s theorem to each step in the ladder it is easy to show
that a voltage of V 0 appearing at the k-th bit position (with k = 0 indicating
the LSB and k = B - 1 indicating the MSB) is equivalent to a voltage of
V 0∕2B-k applied to the inverting input of the op-amp with an impedance of
2R. By the property of superposition (applied here to the linear ladder
circuit), the output voltage over the time interval  nTs,(n + 1)Ts
nTs,(n + 1)Ts![]](livre1305x.png) is
is
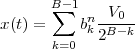
where bB-1nbB-2n b1nb0n is the B-bit binary representation of the sample
x[n]. Note that 0 ≤ x(t) < V 0; for a reconstruction interval between -V 0 and
V 0, one can halve the value of the feedback resistor in the adder and add an
offset of -V 0 Volts to the output.
b1nb0n is the B-bit binary representation of the sample
x[n]. Note that 0 ≤ x(t) < V 0; for a reconstruction interval between -V 0 and
V 0, one can halve the value of the feedback resistor in the adder and add an
offset of -V 0 Volts to the output.
Example 10.1: Nonuniform quantization
All signal processing systems have an intrinsic range of admissible input values; in analog systems, for instance, the nominal range corresponds to the voltage excursion for which the system behaves linearly. In a digital system the internal range is determined by the numerical precision used in representing both the samples and the filter coefficients, while the input range is fixed by the A/D converter, again in terms of maximum and minimum voltages. If the analog samples exceed the specifications, the system introduces some type of nonlinear distortion:
In order to avoid distortion, a possible approach is to normalize the input signal so that it never exceeds the nominal range. The dynamic range of a signal measures the ratio between its highest- and lowest-energy sections; in the case of audio, the dynamic range measures how loud a signal gets with respect to silence. If an audio signal contains some amplitude peaks which exceed the nominal range but is otherwise not very loud, a normalization procedure would “squish” most of the signal to inaudible levels. This is for instance the case of speech, in which plosive sounds constitute high-energy bursts; if speech is normalized uniformly (i.e. if its amplitude is multiplied by a factor so that the peaks are within the range) softer sounds such as sibilants and some vowels end up being almost unintelligible. The solution is to use nonuniform dynamic range compression, also known as companding.
The μ-law compander, commonly used in both analog and digital voice communication devices, performs an instantaneous nonlinear transformation of a signal according to the input-output relation:
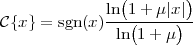 | (10.17) |
where it is assumed that |x| < 1; the parameter μ controls the shape of the resulting curve and it is usually μ = 255. The transformation is shown in Figure 10.7 and we can see that it compresses the large-amplitude range while steeply expanding the low-amplitude range (hence the name “compander”); in so doing a previously peak-normalized signal regains power in the low-amplitude regions.
If the companded signal is needed in quantized form, instead of running the analog values through an analog compander and then quantize uniformly we can directly design a nonuniform quantizer which follows the μ-law characteristic. The method is shown in Figure 10.8 for a 3-bit quantizer with only the positive x-axis displayed. The uniform subdivision of the compander’s output defines four unequal quantization intervals; the splitting points are obtained using the inverse μ-law transformation as
![-k -1[ |2-k- 1| ]
ik = sgn(2 - 1)μ (1+ μ) - 1](livre1311x.png)
Usually, μ-law companding is used for voice signals in conjunction with 8-bit quantization. The dynamic range compression allows to represent a wider dynamic range at a lower SNR than with uniform quantization. To obtain a quantitative measure of the gain, consider that over 8 bits the smallest quantization interval is
![[ ]
Δ = 1-(1 + μ)1∕128 - 1 ≈ 1.7⋅10- 4
μ](livre1313x.png)
To obtain the same resolution with a uniform quantizer we should use
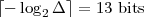
so that the SNR gain is approximately 30 dBs.
Quantization is a key topic both in A/D and D/A conversion and in signal compression. Yet it is often overlooked in standard texts. The book by A. Gersho and R. M. Gray, Vector Quantization and Signal Compression (Springer, 1991) provides a good discussion of the topic. An excellent overview of quantization is given in R. M. Gray and D. L. Neuhof’s article “Quantization”, in IEEE Transactions on Information Theory (October 1998).
Exercise 10.1: Quantization error – I. Consider a stationary i.i.d.
random process x[n] whose samples are uniformly distributed over
the [-1,1] interval. Consider a quantizer {⋅} with the following
characteristic:
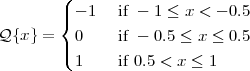
The quantized process y[n] =  x[n]
x[n] is still i.i.d.; compute its power
spectral density Py(ejω)
is still i.i.d.; compute its power
spectral density Py(ejω)
Exercise 10.2: Quantization error – II. Consider a stationary i.i.d.
random process x[n] whose samples are uniformly distributed over the [-1,2]
interval. The process is quantized with a 1-bit quantizer {⋅} with the
following characteristic:
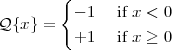
Compute the signal to noise ratio at the output of the quantizer.
Exercise 10.3: More samples or more bits? You have a continuous-time signal (for example, a music source), which you want to store on a digital medium such as a memory card. Assume, for simplicity, that the signal has already been sampled (but not quantized) with a sampling frequency Fs = 32,000 Hz with no aliasing. Assume further that the sampled signal can be modeled as a white process x[n] with power spectral density
and that the pdf of each sample is uniform on the [-1,1] interval.
Now you need to quantize and store the signal. Your constraints are the following:
You come up with two possible schemes:
Clearly both schemes fulfill your constraints. Question: which is the configuration which minimizes the overall mean square error between the original signal and the digitized signal? Show why. As a guideline, note that the MSE will be composed of two independent parts: the one introduced by the quantizers and, for the second scheme, the one which is introduced by the lowpass filter before the downsampler. For the quantizer error, you can assume that the downsampled process still remains a uniform, i.i.d. process.
| © Presses polytechniques et universitaires romandes, 2008 All rights reserved |
The sampling theorem in Chapter 9 provided us with a tool to map a continuous-time signal to a sequence of discrete-time samples taken at a given sampling rate. By choosing a different sampling rate, the same continuous-time signal can be mapped to an arbitrary number of different discrete-time signals. What is the relationship between these different discrete-time sequences? Can they be transformed into each other entirely from within the discrete-time world? These are the questions that multirate theory sets out to answer.
The conversion from one sampling rate to another can always take the “obvious” route via continuous time, i.e. via interpolation and resampling. This is clearly disadvantageous, both from the point of view of the needed equipment and from the point of view of the quality loss which always takes place upon quitting the digital discrete-time domain. That was the rationale, for instance, of an infamous engineering decision taken by the audio industry in the early 90’s. In those years, after compact disk players had been around for about a decade, digital cassette players started to appear in the market under the name of DAT. The decision was to use a different and highly incompatible sampling rate for the DAT with respect to the CD (48 Khz vs. 44.1 Khz) so as to make it difficult to obtain perfect digital copies of existing CDs.(1) Multirate signal processing rendered that strategy moot, as we will see.
More generally, multirate signal processing not only comes to help whenever a conversion between different standards is needed, but it is also a full-fledged signal processing tool in its own right with many fruitful applications in the design of efficient filtering schemes and of telecommunication systems. Finally, multirate theory is at the cornerstone of advanced processing techniques which go under the name of time-frequency analysis.
Downsampling by N (also called subsampling or
decimation(2) )
creates a lower-rate sequence by keeping only one out of N samples in
the original signal. If we call N the downsampling operator, we
have
![{ }
xND [n] = DN x[n] = x[nN ]](livre1320x.png) | (11.1) |
Downsampling effectively discards N - 1 out of N samples and, as such, may cause a loss of information in the original sequence; to understand when and how this happens, we need to arrive at a frequency domain representation of the downsampled sequence.
Let us consider, as an example, the downsampling by 2 operator 2
and let us write out explicitly its effect; if x2D[n] = 2 x[n]
x[n] we
have
we
have
| x[n] | = …, x[-2], x[-1], x[0], x[1], x[2], … | ||
| x2D[n] | = …, x[-4], x[-2], x[0], x[2], x[4], … |
![{ }
D2 x[n + 1] = ..., x[- 5], x[- 3], x [1], x[3], x[5], ...](livre1324x.png)
as, according to the definition, 2 x[n + 1]
x[n + 1] = x[2n + 1]. We have just
shown that the downsampling operator is not time-invariant. More precisely,
the downsampling operator is defined as periodically time-varying since, if
xND[n] = N
= x[2n + 1]. We have just
shown that the downsampling operator is not time-invariant. More precisely,
the downsampling operator is defined as periodically time-varying since, if
xND[n] = N x[n]
x[n] , then:
, then:
![{ }
DN x [n - kN ] = xND [n - k]](livre1329x.png) | (11.2) |
It is trivial to show that the downsampling operator is indeed a linear operator.
One of the fundamental consequences of the lack of time-invariance is that, now, one of the key properties of LTI systems no longer holds for the downsampling operator; indeed, complex sinusoids are no longer eigensequences. As an example, consider x[n] = (-1)n = ejπn, which is the highest-frequency discrete-time sinusoid. After downsampling by 2, we obtain:
![( )
x2D[n] = x [2n] = - 1 2n = 1](livre1330x.png) | (11.3) |
which is the lowest-frequency sinusoid in discrete time. This is one instance of the information loss inherent to downsampling and to understand how it operates we need to move to the frequency domain.
In order to obtain a frequency-domain representation of a downsampling by N, first consider the z-transform of the downsampled signal:
![∑∞
XND (z) = x[nN ]z-n
n=-∞](livre1331x.png) | (11.4) |
Now consider an “auxiliary” z-transform Xa(z) defined as
![∑∞ -nN
Xa (z) = x[nN ]z
n=- ∞](livre1332x.png) | (11.5) |
The interest of Xa(z) lies with the fact that, if we can obtain a closed-form expression for it, we can then write out XND(z) simply as
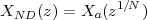 | (11.6) |
Clearly, Xa(z) can be derived from X(z), the z-transform of the original signal, by “killing off” all the terms in the z-transform sum whose index is not a multiple of N; in other words we can write
![∞
∑ - n
Xa (z) = ξN[n]x[n ]z
n= -∞](livre1334x.png) | (11.7) |
where ξN[n] is a “selector” sequence defined as
![{
ξN [n ] = 1 for n multiple of N
0 otherwise](livre1335x.png)
The question now is to find an expression for such a sequence; to this end, let us recall a very early result about the orthogonality of the roots of unity (see Equation (4.4)), which we can rewrite as follows:
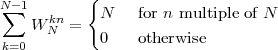 | (11.8) |
where, as per usual, WN = e-j . Clearly, we can define our desired selector
sequence as
. Clearly, we can define our desired selector
sequence as
![N∑- 1
ξN[n] = 1- W kNn
N k=0](livre1338x.png)
and we can therefore write
![∑∞ N∑-1 N∑-1 ∑∞ ( ) N∑-1
Xa (z) = 1- W kNnx[n]z- n = 1- x[n ]W kN z-1 n = 1- X (W kN z)
N n=- ∞ k=0 N k=0 n=- ∞ N k=0](livre1339x.png) |
so that finally:
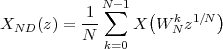 | (11.9) |
The Fourier transform of the downsampled signal is obtained by evaluating XND(z) on the unit circle; explicitly, we have
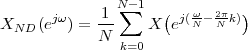 | (11.10) |
The resulting spectrum is, therefore, the scaled sum of N superimposed copies of the original spectrum X(ejω); each copy is shifted in frequency by a multiple of 2π∕N and the result is stretched by a factor of N. We are, in many ways, in a situation similar to that of equation (9.33) where sampling created a periodization of the underlying spectrum; here the spectra are already inherently 2π-periodic, and downsampling creates N - 1 additional interleaved copies. Because of the superposition, aliasing can take place; this is a consequence of the potential loss of information that occurs when samples are discarded. It is easy to verify that in order for the spectral copies in (11.9) not to overlap, the maximum (positive) frequency ωM of the original spectrum(3) must be less than π∕N; this is the non-aliasing condition for the downsampling operator. Conceptually, fulfillment of the non-aliasing condition indicates that the discrete-time representation of the original signal is intrinsically redundant; (N - 1)∕N of the information can be safely discarded and this is mirrored by the fact that only 1∕N of the spectral frequency support is nonzero. We will see shortly that, in this case, the original signal can be perfectly reconstructed with an upsampling and filtering operation.
In the following graphical examples (Figs 11.2 to 11.6) the top panel shows the original spectrum X(ejω); the second panel shows the same spectrum but plotted over a larger frequency interval so as to make its periodic nature explicit; the third panel shows (in different shades of gray) the individual components of the sum in (11.9) before scaling and stretching by N, i.e. the N copies X(WNkejω) for k = 0,1,…,N - 1; the fourth panel shows the final XND(ejω), with the individual components of the sum plotted with a dashed line; finally, the last panel shows XND(ejω) over the usual [-π,π] interval.
Downsampling by 2. If the downsampling factor is 2, the corresponding two roots of unity are just ±1 and we have
![1[ ] 1 [ ( ω ) ( ω )]
X2D (z) = --X (z)+ X (- z) X2D (ejω) = -- X ej 2 + X ej(2-π)
2 2](livre1342x.png) |
Figure 11.2 shows an example of downsampling by 2 for a lowpass signal whose maximum frequency is ωM = π∕2 (i.e. a half-band signal). The non-aliasing condition is fulfilled and, in the superposition, the two shifted versions of the spectrum do not overlap. As the frequency axis expands by a factor of 2, the original half-band signal becomes full band.
|
|
Figure 11.3 shows an example in which the non-aliasing condition is violated. In this case, ωM = 2π∕3 > π∕2 and the spectral copies do overlap. We can see that, as a consequence, the downsampled signal loses its lowpass characteristics. Information is irretrievably lost and the original signal cannot be reconstructed. We will see in the next Section the customary way of dealing with this situation.
|
|
Downsampling by 3. If the downsampling factor is 3 we have
![jω 1-[ ( jω) ( j(ω- 2π)) (j(ω- 4π-))]
X3D (e ) = 3 X e 3 + X e 3 3 + X e 3 3](livre1353x.png) |
Figure 11.4 shows an example in which the non-aliasing condition is violated (ωM = 2π∕3 > π∕3). In particular, the superposition of the three spectral copies is such that the resulting spectrum is flat.
|
|
Downsampling of a Highpass Signal. Figure 11.5 shows an example of downsampling by 2 of a half-band highpass signal. Since the signal occupies only the upper half of the [0,π] frequency band (and, symmetrically, only the lower half of the [-π,0] interval), the interleaved copies do not overlap and, technically, there is no aliasing. The shape of the signal, however, is changed by the downsampling operation and what started out as a highpass signal is transformed into a lowpass signal. The details of the transformation are clearer if, for the sake of example, we consider a complex half-band highpass signal in which the positive and negative parts of the spectrum are different. The steps involved in the downsampling of such a signal are detailed in Figure 11.6 and it is apparent how the low and high parts of the spectrum are interchanged. In both cases the original signal can be exactly reconstructed (since there is no destructive overlap between spectral copies) but the required procedure (which we will study in the exercises) is more complex than a simple upsampling.
|
|
|
|
Because of aliasing, it is customary to filter a signal prior to downsampling. The filter should be designed to eliminate aliasing by removing the high frequency components which fold back onto the lower frequencies (remember how the (-1)n signal ended up as the constant 1). For a downsampling by N, this is accomplished by a lowpass filter with cutoff frequency ωc = π∕N, and the resulting structure is depicted in Figure 11.7.
|
|
An example of the processing chain is shown in Figure 11.8 for a downsampling factor of 2; a half-band lowpass filter is used to truncate the signal’s spectrum outside of the [-π∕2,π∕2] interval and then downsampling proceeds as usual with non-overlapping spectral copies. Clearly, some information is lost and the original signal cannot be recovered exactly but the distortion is controlled and less disruptive than foldover aliasing.
|
|
Upsampling by N produces a higher-rate sequence by creating N samples
out of every sample in the original signal. The upsampling operation consists
simply in inserting N - 1 zeros between every two input samples; if we call
 N the upsampling operator, we have
N the upsampling operator, we have
![{
{ } x[k] for n = kN, k ∈ Z
xNU [n] = UN x[n] = 0 otherwise](livre1375x.png) | (11.11) |
Upsampling is a much “nicer” operation than downsampling since no information is lost and the original signal can always be exactly recovered by downsampling:
![{ { }}
DN UN x[n] = x[n]](livre1376x.png) | (11.12) |
Furthermore, the spectral description of upsampling is extremely simple; in the z-transform domain we have
![∞
X (z) = ∑ x [n]z-n
NU n=-∞ NU
∞
= ∑ x[k]z-kN = X (zN )
k=-∞](livre1377x.png) | (11.13) |
and therefore
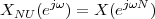 | (11.14) |
so that upsampling is simply a contraction of the frequency axis by a factor of N. The inherent 2π-periodicity of the spectrum must be taken into account so that, in this contraction, the periodic repetitions of the base spectrum are “drawn in” the [-π,π] interval. The effects of upsampling are shown graphically for a simple signal in Figures 11.9 to 11.11; in all figures the top panel shows the original spectrum X(ejω) over [-π,π]; the middle panel shows the same spectrum over a wider range to make the 2π- periodicity explicitly; the last panel shows the upsampled spectrum XNU(ejω), highlighting the rescaling of the [-Nπ,Nπ] interval.
However simple, an upsampled signal suffers from two drawbacks. In the time domain, the upsampled signal does not look “natural” since there are N - 1 zeros between every sample drawn from the input. Thus, a “smooth”(4) input signal no longer looks smooth after upsampling, as shown in the top two panels of Figure 11.13. A solution would be to try to interpolate the original samples in order to “fill in” the gaps. In the frequency domain, on the other hand, the repetitions of the base spectrum, which are drawn in by the upsampling, do not look as if they belong to the [-π,π] interval and it seems natural to try to remove them. These two problems are actually one and the same and they can be solved by an appropriate filter.
|
|
The problem of filling the gaps between nonzero samples in an upsampled sequence is, in many ways, similar to the discrete- to continuous-time interpolation problem of Section 9.4, except that now we are operating entirely in discrete-time. If we adapt the interpolation schemes that we have already studied, we can describe the following cases:
|
|
Zero-Order Hold. In this discrete-time interpolation scheme, also known as piecewise-constant interpolation, after upsampling by N, we use a filter with impulse response:
![{
h0[n ] = 1 n = 0,1,...,N - 1
0 otherwise](livre1393x.png) | (11.15) |
which is shown in Figure 11.14. This interpolation filter simply repeats the original input samples N times, giving a staircase approximation as shown for example in the third panel of Figure 11.13.
First-Order Hold. In this discrete-time interpolation scheme, we obtain a piecewise linear interpolation after upsampling by N by using
![({ |n|
h [n] = 1 - -N- |n | < N
1 (0 otherwise](livre1394x.png) | (11.16) |
The impulse response is the familiar triangular function(5) shown in Figure 11.14. An example of the resulting interpolation is shown in Figure 11.13.
Sinc Interpolation. We know that, in continuous time, the smoothest interpolation is obtained by using a sinc function. This holds in discrete-time as well, and the resulting interpolation filter is a discrete-time sinc:
![( n )
h [n] = sinc --
N](livre1399x.png) | (11.17) |
Note that the sinc above is equal to one for n = 0 and is equal to zero at all integer multiples of N, n = kN; this fulfills the interpolation condition that, after interpolation, the output equals the input at multiples of N (i.e. (h * xNU)[n] = x[n] for n = kN).
The three impulse responses above are all lowpass filters; in particular, the sinc interpolator is an ideal lowpass with cutoff frequency ωc = π∕N while the others are approximations of the same. As a consequence, the effect of the interpolator in the frequency domain is the removal of the N - 1 repeat spectra which have been drawn in the [-π,π] interval. An example is shown in Figure 11.15 where the signal in Figure 11.11 is filtered by an ideal lowpass filter with cutoff π∕4. It turns out that the smoothest possible interpolation in the time domain corresponds to the removal of the spectral repetitions in the frequency domain. An interpolation by the zero-order, or first-order holds, only attenuates the replicas instead of performing a full removal, as we can readily see by considering their frequency responses. Since we are in discrete-time, however, there are no difficulties associated to the design of a digital lowpass filter which performs extremely well. This is in contrast to the design of discrete—to continuous—time interpolators, which are analog designs. That is why sampling rate changes are much more attractive in the discrete-time domain.
So far we have examined methods which change (multiply or divide) the implicit rate of a discrete-time signal by an integer factor. By combining upsampling and downsampling, we can achieve arbitrary rational sampling rate changes. Typically, a rate change by N∕M is obtained by cascading an upsampler by N, a lowpass filter and a downsampler by M. The filter’s cutoff frequency is the minimum of {π∕N,π∕M}; this follows from the fact that upsampling and downsampling require lowpass filters with cutoff frequencies of π∕N and π∕M respectively, and the minimum cutoff frequency dominates in the cascade. A block diagram of this system is shown in Figure 11.16.
|
|
The order of the upsampling and downsampling operators is crucial since, in general, the operators are not commutative. It is easy to appreciate this fact by means of a simple example; for a given sequence x[n] it is
2![(U (x[n]))
2](livre1405x.png) | = x[n] | ||
2![( ( ))
D2 x[n]](livre1406x.png) | = ![{
x[n ] for n even
0 for n odd](livre1407x.png) |
![( ( )) ( ( ))
DN UM x[n] = UM DN x[n]](livre1408x.png) | (11.18) |
The proof of this property is left as an exercise. This property can be put to use in a rational sampling rate converter to minimize the number of operations, per sample in the middle filter.
As an example, we are now ready to solve the audio conversion problem which was quoted at the beginning of the Chapter. To convert an audio file sampled at 44 Khz (“CD-quality”) into an audio file which can be played back at 48 Khz (“DVD-quality”) a rate change of 12∕11 is necessary; this can be achieved with the system shown at the top of Figure 11.17. Conversely, DVD to CD conversion can be performed with a 11∕12 rate changer, shown at the bottom of Figure 11.17.(6)
|
|
Manipulating the sampling rate is useful a many more ways beyond simple conversions between audio standards: oversampling is a case in point. The term “oversampling” describes a situation in which a signal’s sampling rate is made to be deliberately higher than the minimum required by the sampling theorem. Oversampling is used to improve the performance of A/D and D/A converters.
If a continuous-time signal x(t) is bandlimited, the sampling theorem guarantees that we can choose a sampling period Ts such that no error is introduced by the sampling operation. The only source of error in A/D conversion remains the distortion due to quantization; oversampling, in this case, allows us to reduce this error by increasing the underlying sampling rate. Under certain assumptions on the statistical properties of the input signal, the quantization error associated to A/D conversion has been modeled in Section 10.1.1 as an additive noise source. If x(t) is a ΩN-bandlimited signal and Ts = π∕ΩN, we can write:
![ˆx[n ] = x(nTs) + e[n ]](livre1410x.png)
with e[n] a white process of variance
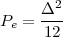
where Δ is the quantization interval. This is represented pictorially in the top panel of Figure 11.18 which shows the power spectral densities for an arbitrary critically sampled signal and for the associated quantization noise.(7) The bottom panel of Figure 11.18 shows the same quantities for the case in which the input signal has been oversampled by a factor of four, i.e. for the signal
![x [n] = x(nT ), T = T ∕4
u u u s](livre1412x.png)
The scale change between signal and noise comes from equation (9.34) but note that the signal-to-noise ratio of the oversampled signal is still the same. However, now we are in the digital domain and it is easy to build a discrete-time filter which removes the quantization error outside of the support of the signal (i.e. outside of the [-π∕4,π∕4] interval) and this improves the SNR.
|
|
Once the out-of-band noise is removed, we can use a downsampler by 4 to obtain a critically sampled signal for which the signal to noise ratio has improved by a factor of 4 (or, alternatively, by 6 dB). The processing chain is shown in Figure 11.19 for a generic oversampling factor N; as a rule of thumb, the signal-to-noise ratio is improved by about 3 dB per octave of oversampling, that is, each doubling of the sampling rate reduces the noise variance by a factor of two, which is 20 log 10 (2) ≃ 3 dB.
The above example is deliberately lacking rigor in the derivations since it turns out that a precise analysis of A/D oversampling is very difficult. It is intuitively clear that some of the quantization noise will be rejected by this procedure, but the fundamental assumption that the input signal is white (and therefore that the quantization noise is uncorrelated) does not hold in reality. In fact, as the sampling rate increases, successive samples exhibit a higher and higher degree of correlation and most of the quantization noise power ends up falling within the band of the signal.
The sampling theorem states that, under the hypothesis of a bandlimited input, sampling is invertible via a sinc interpolation. The sinc filter is an ideal filter and therefore it is not realizable either in the digital or in the analog domain. The analog sinc, therefore, must be approximated by some realizable interpolation filter. Recall that, once the interpolation period Ts is chosen, the continuous-time signal created by the interpolator is the mixed-domain convolution (9.11), which we rewite here:
![∑∞ ( )
xc(t) = x [n]I t--nTs-
n=-∞ Ts](livre1417x.png)
In the frequency domain this becomes
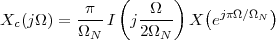 | (11.19) |
with, as usual, ΩN = π∕Ts. The above expression is the product of two terms; the last is the periodic digital spectrum, stretched so as to be 2ΩN-periodic and the first is the frequency response of the analog interpolation filter, again stretched by 2ΩN. In the case of sinc interpolation, the frequency response is a rect with cutoff frequency ΩN, which “kills off” all the repetitions except for the baseband period of the periodic spectrum. The result of sinc interpolation is represented in Figure 11.20; the top panel shows the spectrum of an arbitrary discrete-time signal, the middle panel shows the two terms of Equation (11.19) with the sinc response dashed in gray, and the bottom panel shows the resulting analog spectrum. In both the middle and bottom panels only the positive frequency axis is shown since all signals are assumed to be real and, consequently, the magnitude spectra are symmetric.
|
|
With a realizable interpolator, the stopband of the interpolation filter cannot be uniformly zero and its transition band cannot be infinitely sharp. As a consequence, the spectral copies to the left and right of the baseband will “leak through” in the reconstructed analog signal. It is important to remark at this point that the interpolator filter is an analog filter and, as such, quite delicate to design. Without delving into too many details, there are no FIR filters in the continuous-time domain so that all analog filters are affected by stability problems and by design complexities associated to the passive and active electronic components. In short, a good interpolator is difficult to design and expensive to produce; so much so, in fact, that most of the interpolators used in practical circuitry are just zero-order holds. Unfortunately, the frequency response of the zero-order hold is quite poor; it is indeed easy to show that:
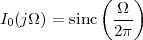
and that this response, while lowpass in nature, decays only as 1∕Ω. The results of zero-order hold D/A conversion are shown in Figure 11.21; the top panel shows the original digital spectrum and the middle panel shows the two terms of Equation (11.19) with the magnitude response of the interpolator dashed in gray. The spectrum of the interpolated signal (shown in the bottom panel) exhibits several non-negligible instances of high-frequency
|
|
leakage centered around the multiples of twice the Nyquist frequency.(8) These are particularly undesirable in audio applications (such as in a CD player). Rather than using expensive and complex analog filters, the performance of the D/A converter can be dramatically improved if we are willing to perform the conversion at a higher rate than the strict minimum. This is achieved by oversampling the signal in the digital domain and the block diagram of the operation is shown in Figure 11.22. Note that this is a paradigmatic instance of cheap and easy discrete-time processing solving an otherwise difficult analog design: the lowpass filter used in discrete-time oversampling is an FIR with arbitrarily high performance, a filter which is much easier to design than an analog lowpass and has no stability problems. The only price paid is an increase in the working frequency of the converter.
Figure 11.23 details an example of D/A conversion with an oversampling factor of two. The top panel shows the spectrum of the oversampled discrete-time signal, together with the associated repetitions in the [-π,π] interval which are going to be filtered out by a lowpass filter with cutoff π∕2. The discrete-time filter response is dashed in gray in the top panel and, while the displayed characteristic is that of an ideal lowpass, note that in the discrete-time domain, we can approximate a very sharp filter rather easily. The two terms of Equation (11.19) (with the magnitude response of the interpolator dashed in gray) are shown in the middle panel; now the interpolation frequency is ΩN,O = 2ΩN, i.e. twice the frequency used in the previous example, in which the signal was critically sampled. Shrinking the spectrum in the digital domain and stretching in the analog makes sure that the analog spectrum is unchanged around the baseband. The final spectrum of the interpolated signal is shown in the bottom panel and we can notice how the first high frequency leakage occurs at twice the frequency of the previous example and is smaller in amplitude. An oversampling of N with N > 2 will push the leakage even higher up in frequency; at this point a very simple analog lowpass (with a very large transition band) will suffice to remove all undesired frequency components.
|
|
Example 11.1: Radio over the phone
In the heyday of radio (up to the 50’s), a main station would often have the necessity of providing audio content ahead of time to the ancillary broadcasters in its geographically distributed network. Before digital signal processing even existed, and before high-bandwidth communication lines became a possibility, most point-to-point real-time communications were over a standard telephone line and audio distribution was no exception. However, since telephone lines have a much smaller bandwidth than good quality audio, the idea was to play the content at lower speed so that the resulting bandwidth could be made to fit into the telephone band. At the other end, a tape would record the signal and then the signal could be sped up to normal pitch. In the continuous-time world, we know that (see (9.8)):
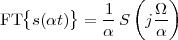
so that a slowing down factor of two (α = 1∕2) would halve the spectral occupancy of the signal.
Today, with digital signal processing at our disposal, we have many more choices and here we will explore the difference between a discrete-time version of the analog scheme of yore and a full-fledged digital communication system such as the one we will study in detail in Chapter 12. Assume we have a DVD-quality audio signal s[n]; the signal is finite-length and it corresponds to 30 minutes of playback time. Recall that “DVD-quality” means that the audio is sampled at 48 KHz with 24 bits per sample and using 24 bits means that practically we can neglect the SNR introduced by the quantization. We want to send this signal over a telephone line knowing that the line is bandlimited to 3840 Hz and that the impairment introduced by the transmission can be modeled as a source of noise which brings down the SNR of the received signal to 40 dB.
Consider the transmission scheme in Figure 11.24; since the D/A is fixed by design (it is difficult to tune the frequency of a converter), we need to shrink the spectrum of the audio signal using multirate processing. The (positive) bandwidth of the DVD-audio signal is 24 KHz, while the telephone channel is limited to 3840 Hz. We have that
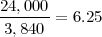
and this is the factor by which we need to upsample; this can be achieved with a combination of a 25-times upsampler followed by a 4-times down-sampler as in Figure 11.25 where LTX(z) is a lowpass filter with cutoff frequency π∕25 and gain L0 = 4∕25. At the receiver the chain is inverted, with an upsampler by four, followed by a lowpass filter with cutoff frequency π∕4 and gain L0 = 25∕4 followed by a 25-times downsampler.
Because of the upsampling (which translates to a slowed-down signal) it will take a little over three hours to send the audio (6.25 × 30 = 187.5 minutes). The quality of the received signal is determined by the SNR of the telephone line; the in-band noise is unaffected by the multirate processing and so the final audio will have an overall SNR of 40 dBs.
Now let us compare the above solution to a fully digital communication scheme. For a telephone line with the bandwidth and the SNR specified above a commercially available digital modem can reliably achieve a throughput of 32 kbits per second. The 30-minute DVD-audio file contains (30 × 60 × 48,000 × 24) bits. At 32 kbps, we will need approximately 18 hours to transmit the signal! The upside, however, is that the received audio will indeed be identical to the source, i.e. DVD-quality. Alternatively, we can sacrifice quality for time: if we quantize the original signal at 8 bits per sample, so that the SRN is approximately 48 dB, the transmission time reduces to 6 hours. Clearly, a modern audio transmission system would employ some advanced data compression scheme to reduce the necessary throughput.
Example 11.2: Spectral cut and paste
By using a suitable combination of upsampling and downsampling we can implement some nice tricks, such as swapping the upper and lower parts of a signal’s spectrum. Consider a discrete-time signal x[n] with the spectrum as in Figure 11.26. If we process the signal with the network in Figure 11.27 where the filters L(z) and H(z) are half-band lowpass and highpass respectively, the output spectrum will be swapped as in Figure 11.28.
Historically, the topic of different sampling rates in signal processing was first treated in detail in R. E. Crochiere and L. R. Rabiner’s, Multirate Digital Signal Processing (Prentice-Hall, 1983). With the advent of filter banks and wavelets, more recent books give a detailed treatment as well, such as P. P. Vaidyanathan, Multirate Systems and Filter Banks (Prentice Hall, 1992), and M. Vetterli and J. Kovacevic’s, Wavelets and Subband Coding (Prentice Hall, 1995). Please note that the latter is now available in open access, see http://www.waveletsandsubbandcoding.org.
Exercise 11.1: Multirate identities. Prove the following two identities:
Exercise 11.2: Multirate systems. Consider the input-output relations of the following multirate systems. Remember that, technically, one cannot talk of “transfer functions” in the case of multirate systems since sampling rate changes are not time invariant. It may happen, though, that by carefully designing the processing chain, this said relation does indeed implement a transfer function.

|
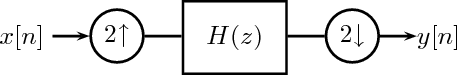
|
| H(z)G(z) + H(-z)G(-z) = 2 | |||
| H(z)F(z) + H(-z)F(-z) = 0 |
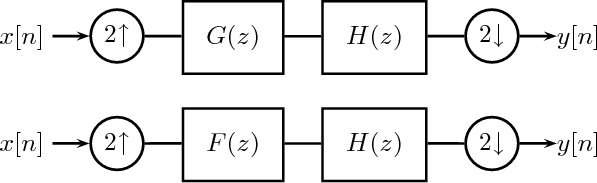
|
Exercise 11.3: Multirate Signal Processing. Consider a discrete-time signal x[n] with the following spectrum:
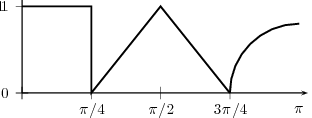
Now consider the following multirate processing scheme in which L(z) is an ideal lowpass filter with cutoff frequency π∕2 and H(z) is an ideal highpass filter with cutoff frequency π∕2:
|
|
Plot the four spectra Y 1(ejω), Y 2(ejω), Y 3(ejω), Y 4(ejω).
Exercise 11.4: Digital processing of continuous-time signals. In your grandmother’s attic you just found a treasure: a collection of super-rare 78 rpm vinyl jazz records. The first thing you want to do is to transfer the recordings to compact discs, so you can listen to them without wearing out the originals. Your idea is obviously to play the record on a turntable and use an A/D converter to convert the line-out signal into a discrete-time sequence, which you can then burn onto a CD. The problem is, you only have a “modern” turntable, which plays records at 33 rpm. Since you’re a DSP wizard, you know you can just go ahead, play the 78 rpm record at 33 rpm and sample the output of the turntable at 44.1 KHz. You can then manipulate the signal in the discrete-time domain so that, when the signal is recorded on a CD and played back, it will sound right.
Design a system which performs the above conversion. If you need to get on the right track, consider the following:
Answer the following questions:

Exercise 11.5: Multirate is so useful! Consider the following block diagram:
|
|
and show that this system implements a fractional delay (i.e. show that the transfer function of the system is that of a pure delay, where the delay is not necessarily an integer).
To see a practical use of this structure, consider now a data transmission system over an analog channel. The transmitter builds a discrete-time signal s[n]; this is converted to an analog signal sc(t) via an interpolator with period Ts, and finally sc(t) is transmitted over the channel. The signal takes a finite amount of time to travel all the way to the receiver; say that the transmission time over the channel is t0 seconds: the received signal ŝc(t) is therefore just a delayed version of the transmitted signal,
At the receiver, ŝc(t) is sampled with a sampler with period Ts so that no aliasing occurs to obtain ŝ[n].
N has the smallest possible value (assume an
ideal lowpass filter in the multirate structure).Exercise 11.6: Multirate filtering. Assume H(z) is an ideal lowpass filter with cutoff frequency π∕10. Consider the system described by the following block diagram:
|
|
Exercise 11.7: Oversampled sequences. Consider a real-value sequence x[n] for which:
 |
One sample of x[n] may have been corrupted and we would like to
approximately or exactly recover it. We denote n0 the time index of the
corrupted sample and 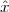 [n] the corresponding corrupted sequence.
[n] the corresponding corrupted sequence.
 [n] if n0 is known.
[n] if n0 is known.
What is the condition that X(ejω) must satisfy to be able to exactly recover x[n]? Specify the algorithm.
| © Presses polytechniques et universitaires romandes, 2008 All rights reserved |
The power of digital signal processing can probably be best appreciated in the enormous progresses which have been made in the field of telecommunications. These progresses stem from three main properties of digital processing:
The fruits of such powerful communication systems are readily enjoyable in everyday life and it suffices here to mention the fast ADSL connections which take the power of high data rates into the home. ADSL is actually a quantitative evolution of a humbler, yet extraordinarily useful device: the voiceband modem. Voiceband modems, transmitting data at a rate of up to 56 Kbit/sec over standard telephone lines, are arguably the crown achievement of discrete-time signal processing in the late 90’s and are still the cornerstone of most wired telecommunication devices such as laptops and fax machines.
In this Chapter, we explore the design and implementation of a voiceband modem as a paradigmatic example of applied digital signal processing. In principle, the development of a fully-functional device would require the use of concepts which are beyond the scope of this book, such as adaptive signal processing and information theory. Yet we will see that, if we neglect some of the impairments that are introduced by real-world telephone lines, we are able to design a working system which will flawlessly modulates and demodulates a data sequence.
A telecommunication system works by exploiting the propagation of electromagnetic waves in a medium. In the case of radio transmission, the medium is the electromagnetic spectrum; in the case of land-line communications such as those in voiceband or ADSL modems, the medium is a copper wire. In all cases, the properties of the medium determine two fundamental constraints around which any communication system is designed:
These constraints define a communication channel and the goal, in the design of a communication system, is to maximize the amount of information which can be reliably transmitted across a given channel. In the design of a digital communication system, the additional goal is to operate entirely in the discrete-time domain up to the interface with the physical channel; this means that:
A classic example of a regulated electromagnetic channel is commercial radio.
Bandwidth constraints in the case of the electromagnetic spectrum are
rigorously put in place because the spectrum is a scarce resource which needs
to be shared amongst a multitude of users (commercial radio, amateur radio,
cellular telephony, emergency services, military use, etc). Power constraints
on radio emissions are imposed for human safety concerns. The AM band, for
instance, extends from 530 kHz to 1700 kHz; each radio station is allotted
an 8 kHz frequency slot in this range. Suppose that a speech signal
x(t), obtained with a microphone, is to be transmitted over a slot
extending from fmin = 650 kHz to fmax = 658 kHz. Human speech
can be modeled as a bandlimited signal with a frequency support of
approximately 12 kHz; speech can, however, be filtered through a lowpass
filter with cutoff frequency 4 kHz with little loss of intelligibility so
that its bandwidth can be made to match the 8 kHz bandwidth of
the AM channel. The filtered signal now has a spectrum extending
from -4 kHz to 4 kHz; multiplication by a sinusoid at frequency
fc = (fmax + fmin)∕2 = 654 KHz shifts its support according to the
continuous-time version of the modulation theorem: if x(t) X(jΩ)
then:
X(jΩ)
then:
![1 [ ]
x(t)cos(Ωct) ←FT→ --X (jΩ - jΩc) + X (jΩ + jΩc)
2](livre1450x.png) | (12.1) |
where Ωc = 2πfc. This is, of course, a completely analog transmission system, which is schematically displayed in Figure 12.1.
The telephone channel is basically a copper wire connecting two users. Because of the enormous number of telephone posts in the world, only a relatively small number of wires is used and the wires are switched between users when a call is made. The telephone network (also known as POTS, an acronym for “Plain Old Telephone System”) is represented schematically in Figure 12.2. Each physical telephone is connected via a twisted pair (i.e. a pair of plain copper wires) to the nearest central office (CO); there are a lot of central offices in the network so that each telephone is usually no more than a few kilometers away. Central offices are connected to each other via the main lines in the network and the digits dialed by a caller are interpreted by the CO as connection instruction to the CO associated to the called number.
To understand the limitations of the telephone channel we have to step back to the old analog times when COs were made of electromechanical switches and the voice signals traveling inside the network were boosted with simple operational amplifiers. The first link of the chain, the twisted pair to the central office, actually has a bandwidth of several MHz since it is just a copper wire (this is the main technical fact behind ADSL, by the way). Telephone companies, however, used to introduce what are called loading coils in the line to compensate for the attenuation introduced by the capacitive effects of longer wires in the network. A side effect of these coils was to turn the first link into a lowpass filter with a cutoff frequency of approximately 4 kHz so that, in practice, the official passband of the telephone channel is limited between fmin = 300 Hz and fmax = 3000 Hz, for a total usable positive bandwidth W = 2700 Hz. While today most of the network is actually digital, the official bandwidth remains in the order of 8 KHz (i.e. a positive bandwidth of 4 KHz); this is so that many more conversations can be multiplexed over the same cable or satellite link. The standard sampling rate for a telephone channel is nowadays 8 KHz and the bandwidth limitations are imposed only by the antialiasing filters at the CO, for a maximum bandwidth in excess of W = 3400 Hz. The upper and lower ends of the band are not usable due to possible great attenuations which may take place in the transmission. In particular, telephone lines exhibit a sharp notch at f = 0 (also known as DC level) so that any transmission scheme will have to use bandpass signals exclusively.
The telephone channel is power limited as well, of course, since telephone companies are quite protective of their equipment. Generally, the limit on signaling over a line is 0.2 V rms; the interesting figure however is not the maximum signaling level but the overall signal-to-noise ratio of the line (i.e. the amount of unavoidable noise on the line with respect to the maximum signaling level). Nowadays, phone lines are extremely high-quality: a SNR of at least 28 dB can be assumed in all cases and one of 32-34 dB can be reasonably expected on a large percentage of individual connections.
Data transmission over a physical medium is by definition analog; modern communication systems, however, place all of the processing in the digital domain so that the only interface with the medium is the final D/A converter at the end of the processing chain, following the signal processing paradigm of Section ??.
In order to develop a digital communication system over the telephone channel, we need to re-cast the problem in the discrete-time domain. To this end, it is helpful to consider a very abstract view of the data transmitter, as shown in Figure 12.3. Here, we neglect the details associated to the digital modulation process and concentrate on the digital-to-analog interface, represented in the picture by the interpolator I(t); the input to the transmitter is some generic binary data, represented as a bit stream. The bandwidth constraints imposed by the channel can be represented graphically as in Figure 12.4. In order to produce a signal which “sits” in the prescribed frequency band, we need to use a D/A converter working at a frequency Fs ≥ 2fmax. Once the interpolation frequency is chosen (and we will see momentarily the criteria to do so), the requirements for the discrete-time signal s[n] are set. The bandwidth requirements become simply
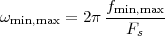
and they can be represented as in Figure 12.5 (in the figure, for instance, we have chosen Fs = 2.28fmax).
We can now try to understand how to build a suitable s[n] by looking more in detail into the input side of the transmitter, as shown in Figure 12.6. The input bitstream is first processed by a scrambler, whose purpose is to randomize the data; clearly, it is a pseudo-randomization since this operation needs to be undone algorithmically at the receiver. Please note how the implementation of the transmitter in the digital domain allows for a seamless integration between the transmission scheme and more abstract data manipulation algorithms such as randomizers. The randomized bitstream could already be transmitted at this point; in this case, we would be implementing a binary modulation scheme in which the signal s[n] varies between the two levels associated to a zero and a one, much in the fashion of telegraphic communications of yore. Digital communication devices, however, allow for a much more efficient utilization of the available bandwidth via the implementation of multilevel signaling. With this strategy, the bitstream is segmented in consecutive groups of M bits and these bits select one of 2M possible signaling values; the set of all possible signaling values is called the alphabet of the transmission scheme and the algorithm which associates a group of M bits to an alphabet symbol is called the mapper. We will discuss practical alphabets momentarily; however, it is important to remark that the series of symbols can be complex so that all the signals in the processing chain up to the final D/A converter are complex signals.
Spectral Properties of the Symbol Sequence. The mapper produces a sequence of symbols a[n] which is the actual discrete-time signal which we need to transmit. In order to appreciate the spectral properties of this sequence consider that, if the initial binary bitstream is a maximum-information sequence (i.e. if the distribution of zeros and ones looks random and “fifty-fifty”), and with the scrambler appropriately randomizing the input bitstream, the sequence of symbols a[n] can be modeled as a stochastic i.i.d. process distributed over the alphabet. Under these circumstances, the power spectral density of the random signal a[n] is simply
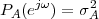
where σA depends on the design of the alphabet and on its distribution.
Choice of Interpolation Rate. We are now ready to determine a suitable rate Fs for the final interpolator. The signal a[n] is a baseband, fullband signal in the sense that it is centered around zero and its power spectral density is nonzero over the entire [-π,π] interval. If interpolated at Fs, such a signal gives rise to an analog signal with nonzero spectral power over the entire [-Fs∕2,Fs∕2] interval (and, in particular, nonzero power at DC level). In order to fulfill the channel’s constraints, we need to produce a signal with a bandwidth of ωw = ωmax - ωmin centered around ωc = ±(ωmax + ωmin)∕2. The “trick” is to upsample (and interpolate) the sequence a[n], in order to narrow its spectral support.(1) Assuming ideal discrete-time interpolators, an upsampling factor of 2, for instance, produces a half-band signal; an upsampling factor of 3 produces a signal with a support spanning one third of the total band, and so on. In the general case, we need to choose an upsampling factor K so that:
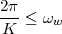
Maximum efficiency occurs when the available bandwidth is entirely occupied by the signal, i.e. when K = 2π∕ωw. In terms of the analog bandwidth requirements, this translates to
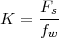 | (12.2) |
where fw = fmax - fmin is the effective positive bandwidth of the transmitted signal; since K must be an integer, the previous condition implies that we must choose an interpolation frequency which is a multiple of the positive passband width fw. The two criteria which must be fulfilled for optimal signaling are therefore:
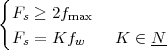 | (12.3) |
The Baseband Signal. The upsampling by K operation, used to narrow the spectral occupancy of the symbol sequence to the prescribed bandwidth, must be followed by a lowpass filter, to remove the multiple copies of the upsampled spectrum; this is achieved by a lowpass filter which, in digital communication parlance, is known as the shaper since it determines the time domain shape of the transmitted symbols. We know from Section 11.2.1 that, ideally, we should use a sinc filter to perfectly remove all repeated copies. Since this is clearly not possible, let us now examine the properties that a practical discrete-time interpolator should possess in the context of data communications. The baseband signal b[n] can be expressed as
![∑
b[n] = aKU [m]g[n - m ]
m](livre1463x.png)
where aKU[n] is the upsampled symbol sequence and g[n] is the lowpass filter’s impulse response. Since aKU[n] = 0 for n not a multiple of K, we can state that:
![∑
b[n] = a[i]g[n- iK ]
i](livre1464x.png) | (12.4) |
It is reasonable to impose that, at multiples of K, the upsampled sequence b[n] takes on the exact symbol value, i.e. b[mK] = a[m]; this translates to the following requirement for the lowpass filter:
![{
1 m = 0
g[mK ] =
0 m ⁄= 0](livre1465x.png) | (12.5) |
This is nothing but the classical interpolation property which we saw in Section 9.4.1. For realizable filters, this condition implies that the minimum frequency support of G(ejω) cannot be smaller than [-π∕K,π∕K].(2) In other words, there will always be a (controllable) amount of frequency leakage outside of a prescribed band with respect to an ideal filter.
To exactly fullfill (12.5), we need to use an FIR lowpass filter; FIR approximations to a sinc filter are, however, very poor, since the impulse response of the sinc decays very slowly. A much friendlier lowpass characteristic which possesses the interpolation property and allows for a precise quantification of frequency leakage, is the raised cosine. A raised cosine with nominal bandwidth ωw (and therefore with nominal cutoff ωb = ωw∕2) is defined over the positive frequency axis as
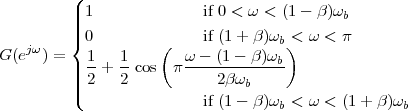 | (12.6) |
and is symmetric around the origin. The parameter β, with 0 < β < 1, exactly defines the amount of frequency leakage as a percentage of the passband. The closer β is to one, the sharper the magnitude response; a set of frequency responses for ωb = π∕2 and various values of β are shown in Figure 12.8. The raised cosine is still an ideal filter but it can be shown that its impulse response decays as 1∕n3 and, therefore, good FIR approximations can be obtained with a reasonable amount of taps using a specialized version of Parks-McClellan algorithm. The number of taps needed to achieve a good frequency response obviously increases as β approaches one; in most practical applications, however, it rarely exceeds 50.
|
|
The Bandpass Signal. The filtered signal b[n] = g[n] * aKU[n] is now a baseband signal with total bandwidth ωw. In order to shift the signal into the allotted frequency band, we need to modulate(3) it with a sinusoidal carrier to obtain a complex bandpass signal:
![jω n
c[n] = b[n ]e c](livre1468x.png)
where the modulation frequency is the center-band frequency:
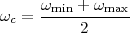
Note that the spectral support of the modulated signal is just the positive interval [ωmin,ωmax]; a complex signal with such a one-sided spectral occupancy is called an analytic signal. The signal which is fed to the D/A converter is simply the real part of the complex bandpass signal:
![{ }
s[n ] = Re c[n]](livre1470x.png) | (12.7) |
If the baseband signal b[n] is real, then (12.7) is equivalent to a standard cosine modulation as in (12.1); in the case of a complex b[n] (as in our case), the bandpass signal is the combination of a cosine and a sine modulation, which we will examine in more detail later. The spectral characteristics of the signals involved in the creation of s[n] are shown in Figure 12.9.
Baud Rate vs Bit Rate. The baud rate of a communication system is the number of symbols which can be transmitted in one second. Considering that the interpolator works at Fs samples per second and that, because of upsampling, there are exactly K samples per symbol in the signal s[n], the baud rate of the system is
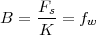 | (12.8) |
where we have assumed that the shaper G(z) is an ideal lowpass. As a general rule, the baud rate is always smaller or equal to the positive passband of the channel. Moreover, if we follow the normal processing order, we can equivalently say that a symbol sequence generated at B symbols per second gives rise to a modulated signal whose positive passband is no smaller than B Hz. The effective bandwidth fw depends on the modulation scheme and, especially, on the frequency leakage introduced by the shaper.
|
|
The total bit rate of a transmission system, on the other hand, is at most the baud rate times the log in base 2 of the number of symbols in the alphabet; for a mapper which operates on M bits per symbol, the overall bitrate is
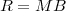 | (12.9) |
A Design Example. As a practical example, consider the case of a telephone line for which fmin = 450 Hz and fmax = 3150 Hz (we will consider the power constraints later). The baud rate can be at most 2700 symbols per second, since fw = fmax -fmin = 2700 Hz. We choose a factor β = 0.125 for the raised cosine shaper and, to compensate for the bandwidth expansion, we deliberately reduce the actual baud rate to B = 2700∕(1 + β) = 2400 symbols per second, which leaves the effective positive bandwidth equal to fw. The criteria which the interpolation frequency must fulfill are therefore the following:
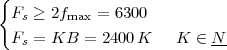
The first solution is for K = 3 and therefore Fs = 7200. With this interpolation frequency, the effective bandwidth of the discrete-time signal is ωw = 2π(2700∕7200) = 0.75π and the carrier frequency for the bandpass signal is ωc = 2π(450 + 3150)∕(2Fs) = π∕2. In order to determine the maximum attainable bitrate of this system, we need to address the second major constraint which affects the design of the transmitter, i.e. the power constraint.
The purpose of the mapper is to associate to each group of M input bits a
value α from a given alphabet 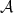 . We assume that the mapper includes a
multiplicative factor G0 which can be used to set the final gain of the
generated signal, so that we don’t need to concern ourselves with the
absolute values of the symbols in the alphabet; the symbol sequence is
therefore:
. We assume that the mapper includes a
multiplicative factor G0 which can be used to set the final gain of the
generated signal, so that we don’t need to concern ourselves with the
absolute values of the symbols in the alphabet; the symbol sequence is
therefore:
![a[n] = G0 α[n], α[n] ∈ A](livre1477x.png)
and, in general, the values α are set at integer coordinates out of convenience.
Transmitted Power. Under the above assumption of an i.i.d. uniformly distributed binary input sequence, each group of M bits is equally probable; since we consider only memoryless mappers, i.e. mappers in which no dependency between symbols is introduced, the mapper acts as the source of a random process a[n] which is also i.i.d. The power of the output sequence can be expressed as
| σa2 | = E a[n] a[n] 2 2 | ||
= G02 ∑
α  α α 2p
a(α) 2p
a(α) | (12.10) | ||
| = G02σ α2 | (12.11) |
; the
distribution over the alphabet is one of the design parameters of the
mapper, and is not necessarily uniform. The variance σα2 is the intrinsic
power of the alphabet and it depends on the alphabet size (it increases
exponentially with M), on the alphabet structure, and on the probability
distribution of the symbols in the alphabet. Note that, in order to avoid
wasting transmission energy, communication systems are designed so that
the sequence generated by the mapper is balanced, i.e. its DC value is
zero:
![∑
E [α [n ]] = αpa (α ) = 0
α ∈A](livre1482x.png)
Using (8.25), the power of the transmitted signal, after upsampling and modulation, is
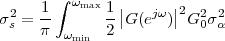 | (12.12) |
The shaper is designed so that its overall energy over the passband is G2 = 2π and we can express this as follows:
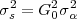 | (12.13) |
In order to respect the power constraint, we have to choose a value for G0
and design an alphabet so that:
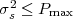 | (12.14) |
where Pmax is the maximum transmission power allowed on the channel. The goal of a data transmission system is to maximize the reliable throughput but, unfortunately, in this respect the parameters σα2 and G0 act upon conflicting priorities. If we use (12.9) and boost the transmitter’s bitrate by increasing M, then σα2 grows and we must necessarily reduce the gain G0 to fulfill the power constraint; but, in so doing, we impair the reliability of the transmission. To understand why that is, we must leap ahead and consider both a practical alphabet and the mechanics of symbol decoding at the transmitter.
QAM. The simplest mapping strategies are one-to-one correspondences
between binary values and signal values: note that in these cases the symbol
sequence is uniformly distributed with pa(α) = 2-M for all α . For
example, we can assign to each group of M bits (b0,…,bM-1) the signed
binary number b0b1b2 bM-1 which is a value between -2M-1 and 2M-1 (b0
is the sign bit). This signaling scheme is called pulse amplitude modulation
(PAM) since the amplitude of each transmitted symbol is directly
determined by the binary input value. The PAM alphabet is clearly balanced
and the inherent power of the mapper’s output is readily computed
as(4)
bM-1 which is a value between -2M-1 and 2M-1 (b0
is the sign bit). This signaling scheme is called pulse amplitude modulation
(PAM) since the amplitude of each transmitted symbol is directly
determined by the binary input value. The PAM alphabet is clearly balanced
and the inherent power of the mapper’s output is readily computed
as(4)
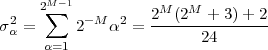
Now, a pulse-amplitude modulated signal prior to modulation is a baseband signal with positive bandwidth of, say, ω0 (see Figure 12.9, middle panel); therefore, the total spectral support of the baseband PAM signal is 2ω0. After modulation, the total spectral support of the signal actually doubles (Fig. 12.9, bottom panel); there is, therefore, some sort of redundancy in the modulated signal which causes an underutilization of the available bandwidth. The original spectral efficiency can be regained with a signaling scheme called quadrature amplitude modulation (QAM); in QAM the symbols in the alphabet are complex quantities, so that two real values are transmitted simultaneously at each symbol interval. Consider a complex symbol sequence
![( )
a[n] = G0 αI[n]+ jαQ [n ] = aI[n]+ jaQ[n]](livre1488x.png)
Since the shaper is a real-valued filter, we have that:
![( ) ( )
b[n] = aI,KU * g[n] + j aQ,KU *g [n] = bI[n]+ jbQ [n ]](livre1489x.png)
so that, finally, (12.7) becomes:
| s[n] | = Re b[n]ejωcn b[n]ejωcn | ||
| = bI[n]cos(ωcn) - bQ[n]sin(ωcn) |
Constellations. The 2M symbols in the alphabet can be represented as points in the complex plane and the geometrical arrangement of all such points is called the signaling constellation. The simplest constellations are upright square lattices with points on the odd integer coordinates; for M even, the 2M constellation points αhk form a square shape with 2M∕2 points per side:

Such square constellations are called regular and a detailed example is shown in Figure 12.10 for M = 4; other examples for M = 2,6,8 are shown in Figure 12.11. The nominal power associated to a regular, uniformly distributed constellation on the square lattice can be computed as the second moment of the points; exploiting the fourfold symmetry, we have
![2M∑∕2- 12M∑∕2-1 [( )2 ( )2] 2
σ2α = 4 2-M 2h - 1 + 2k - 1 = -(2M - 1)
h=1 k=1 3](livre1494x.png) | (12.15) |
Square-lattice constellations exist also for alphabet sizes which are not perfect squares and examples are shown in Figure 12.12 for M = 3 (8-point constellation) and M = 5 (32-point). Alternatively, constellations can be defined on other types of lattices, either irregular or regular; Figure 12.13 shows an alternative example of an 8-point constellation defined on an irregular grid and a 19-point constellation defined over a regular hexagonal lattice. We will see later how to exploit the constellation’s geometry to increase performance.
|
|
|
|
Transmission Reliability. Let us assume that the receiver has eliminated all the “fixable” distortions introduced by the channel so that an “almost exact” copy of the symbol sequence is available for decoding; call this sequence â[n]. What no receiver can do, however, is eliminate all the additive noise introduced by the channel so that:
![ˆa[n] = a[n]+ η[n]](livre1499x.png) | (12.16) |
where η[n] is a complex white Gaussian noise term. It will be clear later why the internal mechanics of the receiver make it easier to consider a complex representation for the noise; again, such complex representation is a convenient abstraction which greatly simplifies the mathematical analysis of the decoding process. The real-valued zero-mean Gaussian noise introduced by the channel, whose variance is σ02, is transformed by the receiver into complex Gaussian noise whose real and imaginary parts are independent zero-mean Gaussian variables with variance σ02∕2. Each complex noise sample η[n] is distributed according to
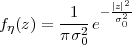 | (12.17) |
The magnitude of the noise samples introduces a shift in the complex
plane for the demodulated symbols â[n] with respect to the originally
transmitted symbols; if this displacement is too big, a decoding error takes
place. In order to quantify the effects of the noise we have to look more in
detail at the way the transmitted sequence is retrieved at the receiver. A
bound on the probability of error can be obtained analytically if we consider
a simple QAM decoding technique called hard slicing. In hard slicing, a value
â[n] is associated to the most probable symbol α by choosing the
alphabet symbol at the minimum Euclidean distance (taking the gain G0
into account):
![{ } { | |2}
D ˆa[n] = argmαi∈nA |ˆa[n]- G0 α|](livre1501x.png)
The hard slicer partitions the complex plane into decision regions centered on alphabet symbols; all the received values which fall into the decision region centered on α are mapped back onto α. Decision regions for a 16-point constellation, together with examples of correct and incorrect hard slicing are represented in Figure 12.14: when the error sample η[n] moves the received symbol outside of the right decision region, we have a decoding error. For square-lattice constellations, this happens when either the real or the imaginary part of the noise sample is larger than the minimum distance between a symbol and the closest decision region boundary. Said distance is dmin = G0, as can be easily seen from Figure 12.10, and therefore the probability of error at the receiver is
| pe | = 1 - P![[( ) ( )]
Re{η[n]} < G0 ∧ Im {η[n]} < G0](livre1502x.png) | ||
| = 1 -∫ Dfη(z)dz |
|
|
We can obtain a closed-form expression for the probability of error if we approximate the decision region D by the inscribed circle of radius dmin (Fig. 12.15), so:
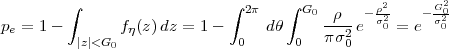 | (12.18) |
where we have used (12.17) and the change of variable z = ρejθ. The probability of error decreases exponentially with the gain and, therefore, with the power of the transmitter.
The concept of “reliability” is quantified by the probability of error that we are willing to tolerate; note that this probability can never be zero, but it can be made arbitrarily low – values on the order of pe = 10-6 are usually taken as a reference. Assume that the transmitter transmits at the maximum permissible power so that the SNR on the channel is maximized. Under these conditions it is
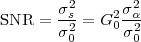
and from (12.18) we have
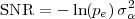 | (12.19) |
For a regular square-lattice constellation we can use (12.15) to determine the maximum number of bits per symbol which can be transmitted at the given reliability figure:
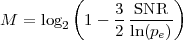 | (12.20) |
and this is how the power constraint ultimately affects the maximum achievable bitrate. Note that the above derivation has been carried out with very specific hypotheses on both the signaling alphabet and on the decoding algorithm (the hard slicing); the upper bound on the achievable rate on the channel is actually a classic result of information theory and is known under the name of Shannon’s capacity formula. Shannon’s formula reads
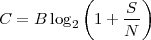 |
where C is the absolute maximum capacity in bits per second, B is the available bandwidth in Hertz and S∕N is the signal to noise ratio.
Design Example Revisited. Let us resume the example on page § by assuming that the power constraint on the telephone line limits the maximum achievable SNR to 22 dB. If the acceptable bit error probability is pe = 10-6, Equation (12.20) gives us a maximum integer value of M = 4 bits per symbol. We can therefore use a regular 16-point square constellation; recall we had designed a system with a baud rate of 2400 symbols per second and therefore the final reliable bitrate is R = 9600 bits per second. This is actually one of the operating modes of the V.32 ITU-T modem standard.(5)
The analog signal s(t) created at the transmitter is sent over the telephone channel and arrives at the receiver as a distorted and noise-corrupted signal ŝ(t). Again, since we are designing a purely digital communication system, the receiver’s input interface is an A/D converter which, for simplicity, we assume, is operating at the same frequency Fs as the transmitter’s D/A converter. The receiver tries to undo the impairments introduced by the channel and to demodulate the received signal; its output is a binary sequence which, in the absence of decoding errors, is identical to the sequence injected into the transmitter; an abstract view of the receiver is shown in Figure 12.16.
Let us assume for the time being that transmitter and receiver are connected back-to-back so that we can neglect the effects of the channel; in this case ŝ(t) = s(t) and, after the A/D module, ŝ[n] = s[n]. Demodulation of the incoming signal to a binary data stream is achieved according to the block diagram in Figure 12.17 where all the steps in the modulation process are undone, one by one.
The first operation is retrieving the complex bandpass signal ĉ[n] from the real signal ŝ[n]. An efficient way to perform this operation is by exploiting the fact that the original c[n] is an analytic signal and, therefore, its imaginary part is completely determined by its real part. To see this, consider a complex analytic signal x[n], i.e. a complex sequence for which X(ejω) = 0 over the [-π,0] interval (with the usual 2π-periodicity, obviously). We can split x[n] into real and imaginary parts:
![x[n ] = x [n]+ jx [n ]
r i](livre1512x.png)
so that we can write:
![x [n ] = x[n]+-x*[n]x [n ] = x[n]--x-*[n]
r 2 i 2j](livre1513x.png) |
In the frequency domain, these relations translate to (see (4.46)):
![[ jω * -jω ]
Xr (ejω) = -X-(e--)+-X--(e---)-
2](livre1514x.png) | (12.21) |
![[ ]
jω -X-(ejω-)--X-*(e--jω-)-
Xi (e ) = 2j](livre1515x.png) | (12.22) |
Since x[n] is analytic, by definition X(ejω) = 0 for -π ≤ ω < 0, X*(e-jω) = 0 for 0 < ω ≤ π and X(ejω) does not overlap with X*(e-jω) (Fig. 12.18). We can therefore use (12.21) to write:
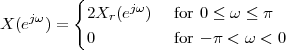 | (12.23) |
Now, xr[n] is a real sequence and therefore its Fourier transform is conjugate-symmetric, i.e. Xr(ejω) = Xr*(e-jω); as a consequence
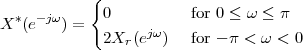 | (12.24) |
By using (12.23) and (12.24) in (12.22) we finally obtain:
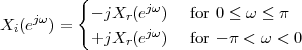 | (12.25) |
which is the product of Xr(ejω) with the frequency response of a Hilbert filter (Sect. 5.6). In the time domain this means that the imaginary part of an analytic signal can be retrieved from the real part only via the convolution:
![xi[n] = h [n]* xr[n]](livre1524x.png)
At the demodulator, ŝ[n] = s[n] is nothing but the real part of c[n] and therefore the analytic bandpass signal is simply
![ˆc[n ] = ˆs[n]+ j(h[n]*sˆ[n])](livre1525x.png)
In practice, the Hilbert filter is approximated with a causal, 2L + 1-tap type III FIR, so that the structure used in demodulation is that of Figure 12.19.
The delay in the bottom branch compensates for the delay introduced by the causal filter and puts the real and derived imaginary part back in sync to obtain:
![( )
ˆc[n ] = ˆs[n- L ]+ j h[n]*sˆ[n]](livre1527x.png)
Once the analytic bandpass signal is reconstructed, it can be brought back to baseband via a complex demodulation with a carrier with frequency -ωc:
![ˆb[n] = ˆc[n]e-jωcn](livre1528x.png)
Because of the interpolation property of the pulse shaper, the sequence of complex symbols can be retrieved by a simple downsampling-by-K operation:
![ˆa[n] = ˆb[nK ]](livre1529x.png)
Finally, the slicer (which we saw in Section 12.2.2) associates a group of M bits to each received symbol and the descrambler reconstructs the original binary stream.
If we now abandon the convenient back-to-back scenario, we have to deal with the impairments introduced by the channel and by the signal processing hardware. The telephone channels affects the received signal in three fundamental ways:
Distortion and delay are obviously both linear transformations and, as such, their description could be lumped together; still, the techniques which deal with distortion and delay are different, so that the two are customarily kept separate. Furthermore, the physical implementation of the devices introduces an unavoidable lack of absolute synchronization between transmitter and receiver, since each of them runs on an independent internal clock. Adaptive synchronization becomes a necessity in all real-world devices, and will be described in the next Section.
Noise. The effects of noise have already been described in Section 12.2.2 and can be summed up visually by the plots in Figure 12.20 in each of which successive values of â[n] are superimposed on the same axes. The analog noise is transformed into discrete-time noise by the sampler and, as such, it leaks through the demodulation chain to the reconstructed symbols sequence â[n]; as the noise level increases (or, equivalently, as the SNR decreases) the shape of the received constellation progressively loses its tightness around the nominal alphabet values. As symbols begin to cross the boundaries of the decision regions, more and more decoding errors, take place.
Equalization. We saw previously that the passband of a communication channel is determined by the frequency region over which the channel introduces only linear types of distortion. The channel can therefore be modeled as a continuous-time linear filter Dc(jΩ) whose frequency response is unknown (and potentially time-varying). The received signal (neglecting noise) is therefore Ŝ(jΩ) = Dc(jΩ)S(jΩ) and, after the sampler, we have
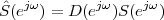
where D(ejω) represents the combined effect of the original channel and of the anti-aliasing filter at the A/D converter. To counteract the channel distortion, the receiver includes an adaptive equalizer E(z) right after the A/D converter; this is an FIR filter which is modified on the fly so that E(z) ≈ 1∕D(z). While adaptive filter theory is beyond the scope of this book, the intuition behind adaptive equalization is shown in Figure 12.21. In fact, the demodulator contains an exact copy of the modulator as well; if we assume that the symbols produced by the slicer are error-free, a perfect copy of the transmitted signal s[n] can be generated locally at the receiver. The difference between the equalized signal and the reconstructed original signal is used to adapt the taps of the equalizer so that:
![d[n] = ˆse[n]- s[n] -→ 0](livre1532x.png)
Clearly, in the absence of a good initial estimate for D(ejω), the sliced values â[n] are nothing like the original sequence; this is obviated by having the transmitter send a pre-established training sequence which is known in advance at the receiver. The training sequence, together with other synchronization signals, is sent each time a connection is established between transmitter and receiver and is part of the modem’s handshaking protocol. By using a training sequence, E(z) can quickly converge to an approximation of 1∕D(z) which is good enough for the receiver to start decoding symbols correctly and use them in driving further adaptation.
|
|
Delay. The continuous-time signal arriving at the receiver can be modeled as
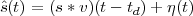 | (12.26) |
where v(t) is the continuous-time impulse response of the channel, η(t) is the continuous-time noise process and td is the propagation delay, i.e. the time it takes for the signal to travel from transmitter to receiver. After the sampler, the discrete-time signal to be demodulated is ŝ[n] = ŝ(nTs); if we neglect the noise and distortion, we can write
![( )
ˆs[n] = s(nTs - td) = s (n - nd)Ts - τ Ts](livre1535x.png) | (12.27) |
where we have split the delay as td = (nd + τ)Ts with nd N and |τ|≤ 1∕2.
The term nd is called the bulk delay and it can be estimated easily in a
full-duplex system by the following handshaking procedure:
In the end, the total round-trip delay measured by system A is
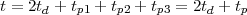
since tp is known exactly in terms of the number of samples, td can be estimated to within a sample. The bulk delay is easily dealt with at the receiver, since it translated to a simple z-nd component in the channel’s response. The fractional delay, on the other hand, is a more delicate entity which we will need to tackle with specialized machinery.
In order for the receiver to properly decode the data, the discrete-time signals inside the receiver must be synchronous with the discrete-time signals generated by the transmitter. In the back-to-back operation, we could neglect synchronization problems since we assumed ŝ[n] = s[n]. In reality, we will need to compensate for the propagation delay and for possible clock differences between the D/A at the transmitter and the A/D at the receiver, both in terms of time offsets and in terms of frequency offsets.
Carrier recovery is the modem functionality by which any phase offset
between carriers is estimated and compensated for. Phase offsets between the
transmitter’s and receiver’s carriers are due to the propagation delay and to
the general lack of a reference clock between the two devices. Assume that
the oscillator in the receiver has a phase offset of θ with respect to the
transmitter; when we retrieve the baseband signal  [n] from ĉ[n] we
have
[n] from ĉ[n] we
have
![ˆ -j(ωcn-θ) - j(ωcn-θ) jθ
b[n] = ˆc[n]e = c[n ]e = b[n]e](livre1538x.png)
where we have neglected both distortion and noise and assumed ĉ[n] = c[n]. Such a phase offset translates to a rotation of the constellation points in the complex plane since, after downsampling, we have â[n] = a[n]ejθ. Visually, the received constellation looks like in Figure 12.22, where θ = π∕20 = 9∘. If we look at the decision regions plotted in Figure 12.22, it is clear that in the rotated constellation some points are shifted closer to the decision boundaries; for these, a smaller amount of noise is sufficient to cause slicing errors. An even worse situation happens when the receiver’s carrier frequency is slightly different than the transmitter’s carrier frequency; in this case the phase offset changes over time and the points in the constellation start to rotate with an angular speed equal to the difference between frequencies. In both cases, data transmission becomes highly unreliable: carrier recovery is then a fundamental part of modem design.
The most common technique for QAM carrier recovery over well-behaved
channels is a decision directed loop; just as in the case of the adaptive
equalizer, this works when the overall SNR is sufficiently high and the
distortion is mild so that the slicer’s output is an almost error-free sequence
of symbols. Consider a system with a phase offset of θ; in Figure 12.23 the
rotated symbol  (indicated by a star) is sufficiently close to the
transmitted value α (indicated by a dot) to be decoded correctly. In the z
plane, consider the two vectors
(indicated by a star) is sufficiently close to the
transmitted value α (indicated by a dot) to be decoded correctly. In the z
plane, consider the two vectors  1 and
1 and  2, from the origin to
2, from the origin to 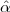 and α
respectively; the magnitude of their vector product can be expressed
as
and α
respectively; the magnitude of their vector product can be expressed
as
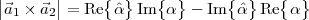 | (12.28) |
Moreover, the angle between the vectors is θ and it can be computed as
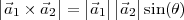 | (12.29) |
We can therefore obtain an estimate for the phase offset:
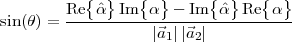 | (12.30) |
For small angles, we can invoke the approximation sin(θ) ≈ θ and obtain a quick estimate of the phase offset. In digital systems, oscillators are realized using the algorithm we saw in Section 2.1.3; it is easy to modify such a routine to include a time-varying corrective term derived from the estimate of θ above so that the resulting phase offset is close to zero. This works also in the case of a slight frequency offset, with θ converging in this case to a nonzero constant. The carrier recovery block diagram is shown in Figure 12.24.
This decision-directed feedback method is almost always able to “lock” the constellation in place; due to the fourfold symmetry of regular square constellations, however, there is no guarantee that the final orientation of the locked pattern be the same as the original. This difficulty is overcome by a mapping technique called differential encoding; in differential encoding the first two bits of each symbol actually encode the quadrant offset of the symbol with respect to the previous one, while the remaining bits indicate the actual point within the quadrant. In so doing, the encoded symbol sequence becomes independent of the constellation’s absolute orientation.
Timing recovery is the ensemble of strategies which are put in place to recover the synchronism between transmitter and receiver at the level of discrete-time samples. This synchronism, which was one of the assumptions of back-to-back operation, is lost in real-world situations because of propagation delays and because of slight hardware differences between devices. The D/A and A/D, being physically separate, run on independent clocks which may exhibit small frequency differences and a slow drift. The purpose of timing recovery is to offset such hardware discrepancies in the discrete-time domain.
A Digital PLL. Traditionally, a Phase-Locked-Loop (PLL) is an analog circuit which, using a negative feedback loop, manages to keep an internal oscillator “locked in phase” with an external oscillatory input. Since the internal oscillator’s parameters can be easily retrieved, PLLs are used to accurately measure the frequency and the phase of an external signal with respect to an internal reference.
In timing recovery, we use a PLL-like structure as in Figure 12.25 to compensate for sampling offsets. To see how this PLL works, assume that the discrete-time samples ŝ[n] are obtained by the A/D converter as
![ˆs[n] = ˆs(t)
n](livre1549x.png) | (12.31) |
where the sequence of sampling instants tn is generated as
![tn+1 = tn + T [n]](livre1550x.png) | (12.32) |
Normally, the sampling period is a constant and T[n] = Ts = 1∕Fs but
here we will assume that we have a special A/D converter for which the
sampling period can be dynamically changed at each sampling cycle. Assume
the input to the sampler is a zero-phase sinusoid of known frequency
f0 = Fs∕N for N N and N ≥ 2:
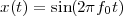
If the sampling period is constant and equal to Ts and if the A/D is synchronous to the sinusoid, the sampled signal are simply:
![( 2π )
x[n ] = sin --n
N](livre1553x.png)
We can test such synchronicity by downsampling x[n] by N and we should have xND[n] = 0 for all n; this situation is shown at the top of Figure 12.26 and we can say that the A/D is locked to the reference signal x(t).
If the local clock has a time lag τ with respect to the reference time of the incoming sinusoid (or, alternatively, if the incoming sinusoid is delayed by τ), then the discrete-time, downsampled signal is the constant:
![xND [n] = sin(2πf0τ )](livre1554x.png) | (12.33) |
Note, the A/D is still locked to the reference signal x(t), but it exhibits a phase offset, as shown in Figure 12.26, middle panel. If this offset is sufficiently small then the small angle approximation for the sine holds and xND[n] provides a direct estimate of the corrective factor which needs to be injected into the A/D block. If the offset is estimated at time n0, it will suffice to set
![{
Ts - τ for n = n0
T[n] =
Ts for n > n0](livre1555x.png) | (12.34) |
for the A/D to be locked to the input sinusoid.
|
|
Suppose now that the the A/D converter runs slightly slower than its nominal speed or, in other words, that the effective sampling frequency is Fs′ = βFs, with β < 1. As a consequence the sampling period is T′s = Ts∕β > Ts and the discrete-time, downsampled signal becomes
![( )
xND [n ] = sin (2π β)n](livre1559x.png) | (12.35) |
i.e. it is a sinusoid of frequency 2πβ; this situation is shown in the bottom panel of Figure 12.26. We can use the downsampled signal to estimate β and we can re-establish a locked PLL by setting
![T [n ] = Ts
β](livre1560x.png) | (12.36) |
The same strategy can be employed if the A/D runs faster than normal, in which case the only difference is that β > 1.
A Variable Fractional Delay. In practice, A/D converters with “tunable” sampling instants are rare and expensive because of their design complexity; furthermore, a data path from the discrete-time estimators to the analog sampler would violate the digital processing paradigm in which all of the receiver works in discrete time and the one-way interface from the analog world is the A/D converter. In other words: the structure in Figure 12.25 is not a truly digital PLL loop; to implement a completely digital PLL structure, the adjustment of the sampling instants must be performed in discrete time via the use of a programmable fractional delay.
Let us start with the case of a simple time-lag compensation for a continuous-time signal x(t). Of the total delay td, we assume that the bulk delay has been correctly estimated so that the only necessary compensation is that of a fractional delay τ, with |τ|≤ 1∕2. From the available sampled signal x[n] = x(nTs) we want to obtain the signal
![xτ[n] = x (nTs + τ Ts)](livre1561x.png) | (12.37) |
using discrete-time processing only. Since we will be operating in discrete time, we can assume Ts = 1 with no loss of generality and so we can write simply:
![x τ[n] = x(n+ τ )](livre1562x.png)
We know from Section ?? that the “ideal” way to obtain xτ[n] from x[n] is to use a fractional delay filter:
![xτ[n] = dτ[n]* x[n]](livre1563x.png)
where Dτ(ejω) = ejωτ. We have seen that the problem with this approach is that Dτ(ejω) is an ideal filter, and that its impulse response is a sinc, whose slow decay leads to very poor FIR approximations. An alternative approach relies on the local interpolation techniques we saw in Section 9.4.2. Suppose 2N + 1 samples of x[n] are available around the index n = n0; we could easily build a local continuous-time interpolation around n0 as
![∑N (N )
ˆx(n0;t) = x[n0 - k]L k (t)
k= -N](livre1564x.png) | (12.38) |
where Lk(N)(t) is the k-th Lagrange polynomial of order 2N defined in (9.14). The approximation
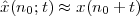
is good, at least, over a unit-size interval centered around n0, i.e. for |t|≤ 1∕2 and therefore we can obtain the fractionally delayed signal as
![xτ[n0 ] = ˆxτ(n0;τ)](livre1566x.png) | (12.39) |
as shown in Figure 12.27 for N = 1 (i.e. for a three-point local interpolation).
|
|
Equation (12.39) can be rewritten in general as
![N
∑ (N ) ˆ
xτ[n] = x [n - k]L k (τ) = dτ[n]*x [n]
k=- N](livre1568x.png) | (12.40) |
which is the convolution of the input signal with a (2N + 1)-tap FIR whose coefficients are the values of the 2N + 1 Lagrange polynomials of order 2N computed in t = τ. For instance, for the above three-point interpolator, we have
 τ[-1] τ[-1] | = τ | ||
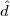 τ[0] τ[0] | = -(τ + 1)(τ - 1) | ||
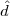 τ[1] τ[1] | = τ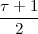 |
The fact that the coefficients 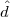 τ[n] are expressed in closed form as a
polynomial function of τ makes it possible to efficiently compensate for a
time-varying delay by recomputing the FIR taps on the fly. This is actually
the case when we need to compensate for a frequency drift between
transmitter and receiver, i.e. we need to resample the input signal. Suppose
that, by using the techniques in the previous Section, we have estimated
that the actual sampling frequency is either higher or lower than the
nominal sampling frequency by a factor β which is very close to 1.
From the available samples x[n] = x(nTs) we want to obtain the
signal
τ[n] are expressed in closed form as a
polynomial function of τ makes it possible to efficiently compensate for a
time-varying delay by recomputing the FIR taps on the fly. This is actually
the case when we need to compensate for a frequency drift between
transmitter and receiver, i.e. we need to resample the input signal. Suppose
that, by using the techniques in the previous Section, we have estimated
that the actual sampling frequency is either higher or lower than the
nominal sampling frequency by a factor β which is very close to 1.
From the available samples x[n] = x(nTs) we want to obtain the
signal
![( )
xβ[n] = x nTs-
β](livre1575x.png)
using discrete-time processing only. With a simple algebraic manipulation we can write
![( 1 - β )
xβ [n] = x nTs - n----- Ts = x (nTs - nτ Ts)
β](livre1576x.png) | (12.41) |
Here, we are in a situation similar to that of Equation (12.37) but in this case the delay term is linearly increasing with n. Again, we can assume Ts = 1 with no loss of generality and remark that, in general, β is very close to one so that it is
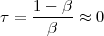
Nonetheless, regardless of how small τ is, at one point the delay term nτ will fall outside of the good approximation interval provided by the local interpolation scheme. For this, a more elaborate strategy is put in place, which we can describe with the help of Figure 12.28 in which β = 0.82 and therefore τ ≈ 0.22:
|
|
In general the resampled signal can be computed for all n using (12.40) as
![xβ[n] = xτn [n + γn]](livre1579x.png) | (12.42) |
where
| τn | = frac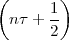 - - | (12.43) |
| γn | = 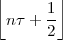 | (12.44) |
Figure 12.29 shows an example in which the sampling frequency is too slow and the discrete-time signal must be resampled at a higher rate. In the figure, β = 1.28 so that τ ≈-0.22; the first resampling steps are:
|
|
In general the resampled signal can be computed for all n using (12.40) as
![xβ[n] = xτn [n - γn]](livre1584x.png) | (12.45) |
where τn and γn are as in (12.43) and (12.44).
Nonlinearity. The programmable delay is inserted in a PLL-like
loop as in Figure 12.30 where { ⋅ } is a processing block which
extracts a suitable sinusoidal component from the baseband
signal.(7)
Hypothetically, if the transmitter inserted an explicit sinusoidal component
p[n] in the baseband with a frequency equal to the baud rate and with zero
phase offset with respect to the symbol times, then this signal could be used
for synchronism; indeed, from
![( 2πfb ) ( 2π )
p[n] = sin -F---n = sin K--n
s](livre1585x.png)
we would have pKD[n] = 0. If this component was present in the signal, then
the block { ⋅ } would be a simple resonator with peak frequencies at
ω = ±2π∕K, as described in Section 7.3.1.
Now, consider more in detail the baseband signal b[n] in (12.4); if we always transmitted the same symbol a, then b[n] = a∑ ig[n-iK] would be a periodic signal with period K and, therefore, it would contain a strong spectral line at 2π∕K which we could use for synchronism. Unfortunately, since the symbol sequence a[n] is a balanced stochastic sequence we have that:
![[ ] ∑
E b[n] = E [a[n]] g[n - iK ] = 0
i](livre1587x.png) | (12.46) |
and so, even on average, no periodic pattern emerges.(8) The way around this impasse is to use a fantastic “trick” which dates back to the old days of analog radio receivers, i.e. we process the signal through a nonlinearity which acts like a diode. We can use, for instance, the square magnitude operator; if we process b[n] with this nonlinearity, it will be
![[| |2] ∑ ∑ [ ]
E |b[n]| = E a[h]a*[i]g [n - hK ]g[n - iK ]
h i](livre1588x.png) | (12.47) |
Since we have assumed that a[n] is an uncorrelated i.i.d. sequence,
![[ ]
E a[h]a *[i] = σ2aδ[h - i]](livre1589x.png)
and, therefore,
![[ { }] ∑ ( )
E S b[n] = σ2a g[n - iK ]2
i](livre1590x.png) | (12.48) |
The last term in the above equation is periodic with period K and this
means that, on average, the squared signal contains a periodic component at
the frequency we need. By filtering the squared signal through the resonator
above (i.e. by setting  x[n]
x[n] =
= 
 x[n]
x[n] 2
2 ), we obtain a sinusoidal
component suitable for use by the PLL.
), we obtain a sinusoidal
component suitable for use by the PLL.
Of course there are a good number of books on communications, which cover the material necessary for analyzing and designing a communication system like the modem studied in this Chapter. A classic book providing both insight and tools is J. M. Wozencraff and I. M. Jacobs’s Principles of Communication Engineering (Waveland Press, 1990); despite its age, it is still relevant. More recent books include Digital Communications (McGraw Hill, 2000) by J. G. Proakis; Digital Communications: Fundamentals and Applications (Prentice Hall, 2001) by B. Sklar, and Digital Communication (Kluwer, 2004) by E. A. Lee and D. G. Messerschmitt.
Exercise 12.1: Raised cosine. Why is the raised cosine an ideal filter? What type of linear phase FIR would you use for its approximation?
Exercise 12.2: Digital resampling. Use the programmable digital delay of Section 12.4.2 to design an exact sampling rate converter from CD to DVD audio (Sect. 11.3). How many different filters hτ[n] are needed in total? Does this number depend on the length of the local interpolator?
Exercise 12.3: A quick design. Assume the specifications for a given telephone line are fmin = 300 Hz, fmax = 3600 Hz, and a SNR of at least 28 dB. Design a set of operational parameters for a modem transmitting on this line (baud rate, carrier frequency, constallation size). How many bits per second can you transmit?
Exercise 12.4: The shape of a constellation. One of the reasons for designing non-regular constellations, or constellation on lattices, different than the upright square grid, is that the energy of the transmitted signal is directly proportional to the parameter σα2 as in (12.10). By arranging the same number of alphabet symbols in a different manner, we can sometimes reduce σα2 and therefore use a larger amplification gain while keeping the total output power constant, which in turn lowers the probability of error. Consider the two 8-point constellations in the Figure 12.12 and Figure 12.13 and compute their intrinsic power σα2 for uniform symbol distributions. What do you notice?
| © Presses polytechniques et universitaires romandes, 2008 All rights reserved |
B
bandlimited signal, 15
bandlimited signal, 16
bandpass
filter, 17, 18
signal, 19, 20
bandwidth, 21, 22
constraint, 23
of telephone channel, 24
base-12, 25
baseband spectrum, 26
basis
sinc, 27
basis (vector space), 28, 29, 30–31
Fourier, 32
orthonormal, 33, 34–35
span, 36
subspace, 37
Baud rate, 38
Bessel’s inequality, 39
BIBO, 40
Blackman window, 41
C
carrier, 42, 43
recovery, 44
cascade structure, 45
causal
CCDE, 46
filter, 47
CCDE, 48–49
solving, 50
CCDE, 51
CD, 52, 53, 54, 55
SNR, 56
CD to DVD conversion, 57
Chebyshev polynomials, 58
circulant matrix, 59
compander, 60
complex exponential, 61, 62
aliasing, 63, 64
Constant-Coefficient Difference Equation, see CCDE
constellation, 66
continuous time
vs. discrete time, 67–68
convolution
as inner product, 69
associativity, 70
circular, 71
in continuous time, 72
of DTFTs, 73, 74
theorem, 75
theorem, 76
convolution, 77
covariance, 78
critical sampling, 79
cross-correlation, 80
D
DAT (Digital Audio Tape), 81
data compression rates, 82
decimation, 83
decision-directed loop, 84
delay, 85, 86, 87
fractional, 88
delay, 89
demodulation, 90
DFS, 91–92
properties, 93
DFT, 94–95
matrix form, 96
properties, 97
zero padding, 98
DFT, 99
dichotomy paradox, see Zeno
differentiator
approximate, 101
digital
computer, 102
etymology of, 103
revolution, 104
digital frequency, 105–106
digital frequency, 107
Dirac delta
DTFT of, 108
pulse train, 109
Dirac delta, 110
direct form, 111
Discrete Fourier Series, see DFS
Discrete Fourier Transform, see DFT
discrete time
vs. continuous time, 114–115
discrete time, 116
discrete-time
vs. digital, 117
Discrete-Time Fourier Transform, see DTFT
discrete-time signal
finite-length, 119
finite-support, 120
infinite-length, 121
periodic, 122
discrete-time signal, 123
distortion
nonlinear, 124
downsampling, 125–126
downsampling, 127
DTFT, 128–129
from DFS, 130
from DFT, 131
of unit step, 132
plotting, 133–134
properties, 135, 136
DTFT, 137
DVD, 138, 139, 140, 141
E
eigenfunctions, 142
energy
of a signal, 143
equiripple filter, 144
error correcting codes, 145
F
FFT, 146
complexity, 147
zero padding, 148
filter
allpass, 149
computational cost, 150
delay, 151
frequency response, 152
filter design, 153–154
FIR, 155–156
minimax, 157–158
window method, 159–160
specifications, 161
filter structures, 162–163
cascade, 164
direct forms, 165
parallel, 166
filter, 167
finite-length signal, 168, 169
filtering, 170
finite-support signal, 171
FIR
linear phase, 172
types, 173
vs. IIR, 174
zero locations, 175
FIR, 176
first-order hold, 177
(discrete-time), 178
Fourier basis, 179, 180
Fourier series, 181
Fourier transform (continuous time), 182
fractional delay, 183
variable, 184
frequency domain, 185
frequency response, 186
magnitude, 187
phase, 188
G
galena, 189
Gibbs phenomenon, 190
Goertzel filter, 191
group delay
negative, 192
group delay, 193
H
half- band filter, 194
half-band filter, 195, 196, 197
half-band filter, 198
Hamming window, 199
highpass
filter, 200, 201
signal, 202
Hilbert
demodulation, 203
Hilbert filter, 204
Hilbert space, 205–206
completeness, 207
I
ideal filter, 208
bandpass, 209
highpass, 210
Hilbert, 211
lowpass, 212
IIR
vs. FIR, 213
IIR, 214
impulse, 215
impulse response, 216–217
infinite-length signal, 218, 219
inner product
approximation by, 220
Euclidean distance, 221
for functions, 222
inner product, 223
integrator
discrete-time, 224
leaky, 225
planimeter, 226
RC network, 227
interpolation, 228, 229–230
in multirate, 231
local, 232
first-order, 233
Lagrange, 234
zero-order, 235
sinc, 236
K
Kaiser formula, 237
Karplus-Strong, 238
L
Lagrange interpolation, 239, 240
Lagrange interpolation, 241
Lagrange polynomials, 242
leaky integrator, 243–244, 245, 246, 247
Leibnitz, 248
linear phase
generalized, 249
linear phase, 250
linearity, 251
Lloyd-Max, 252
lowpass
filter, 253, 254
signal, 255
M
magnitude response, 256
mapper, 257
Matlab, 258
modem, 259
modulation
AM, 260
AM radio, 261
theorem, 262
moving average, 263–264, 265, 266, 267
μ-law, 268
N
negative frequency, 269
Nile floods, 270
noise
amplification, 271
complex Gaussian, 272
floor, 273
thresholding, 274
nonlinear processing, 275, 276
notch, 277
O
optimal filter design, see filter design, FIR, minimax
orthonormal basis, 279
oversampling, 280
in A/D conversion, 281
in D/A conversion, 282
P
parallel structure, 283
Parks-McClellan, see filter design, FIR, minimax
Parseval’s identity, 285
for the DFS, 286
for the DFT, 287
for the DTFT, 288
passband, 289
passband, 290
periodic extension, 291
periodic signal, 292
filtering, 293
periodization, 294, 295, 296
periodization, 297
phase
linear, 298
zero, 299
phase response, 300
phonograph, 301
planimeter, see integrator
PLL (phase locked loop), 303
Poisson sum formula, 304
pole-zero plot, 305
power
constraint, 306, 307
of a signal, 308
power spectral density, 309
product
of signals, 310
programmable delay, 311
PSD, see power spectral density
Pythagoras, 313
Q
QAM
constellation, 314
quadrature amplitude modulation, see QAM
quantization, 316–317, 318–319
nonuniform, 320
reconstruction, 321
uniform, 322–323
quantization, 324
R
raised cosine, 325
random
variable, 326–327
vector, 328–329
Gaussian, 330
random process, 331–332
covariance, 333
cross-correlation, 334
ergodic, 335
filtered, 336
Gaussian, 337
power spectral density, 338–339
stationary, 340
white noise, 341
rational sampling rate change, 342
rect, 343
rect, 344
rectangular window, 345
region of convergence, see ROC
reproducing formula, 347
resonator, 348
ROC, 349
roots
of complex polynomial, 350, 351
of transfer function, 352
of unity, 353
S
sampling, 354
frequency, 355, 356
theorem, 357
sampling theorem, 358
sampling theorem, 359
scaling, 360
sequence, see discrete-time signal
shift, 362
sinc, 363, 364
sinc interpolation, 365–366
(discrete-time), 367
sinc, 368
slicer, 369
SNR, 370, 371, 372
of a CD, 373
of a telephone channel, 374
spectrogram, 375
spectrum
magnitude, 376
overlap, 377
periodicity, 378
phase, 379
stability, 380
stability criteria, 381, 382
stationary process, 383
stopband, 384
stopband, 385
sum
of signals, 386
system
LTI, 387–388
T
telephone channel, 389
bandwidth, 390, 391
SNR, 392, 393
thermograph, 394
time domain, 395
time-invariance, 396
timing recovery, 397–398
Toeplitz matrix, 399
transatlantic cable, 400
transfer function, 401
ROC and stability, 402
roots, 403
sketching, 404
transfer function, 405
transmission reliability, 406
triangular window, 407
U
unit step, 408
DTFT, 409
upsampling, 410–411
V
vector
distance, 412
norm, 413
orthogonality, 414
vector space, 415–416
basis, 417
vector, 418
vinyl, 419, 420, 421
W
wagon wheel effect, 422
white noise, 423
Wiener filter, 424
Z
Zeno, 425
zero initial conditions, 426, 427
zero-order hold, 428
(discrete-time), 429
z-transform, 430–431
of periodic signals, 432
ROC, 433
z-transform, 434


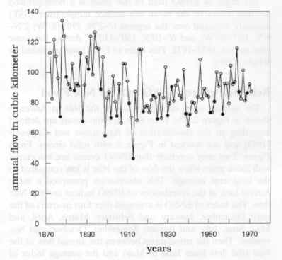

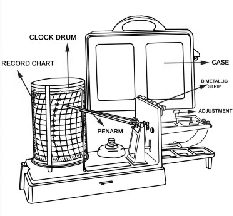
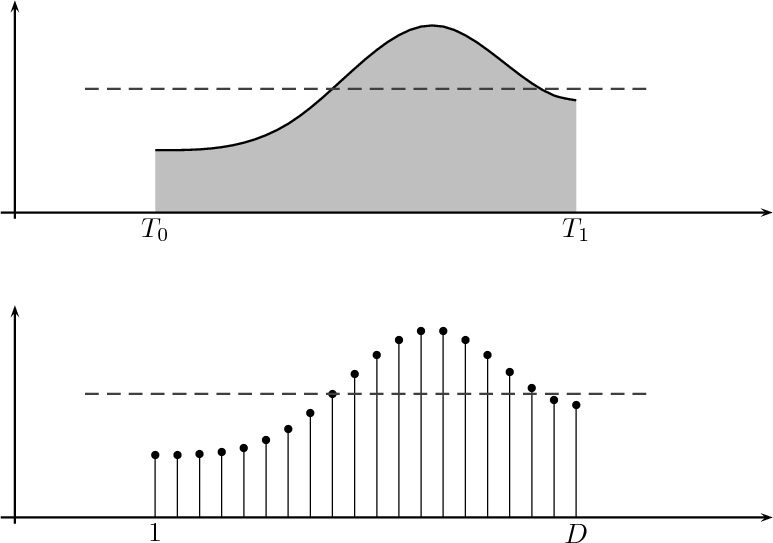

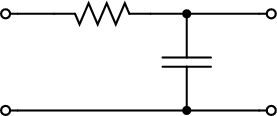

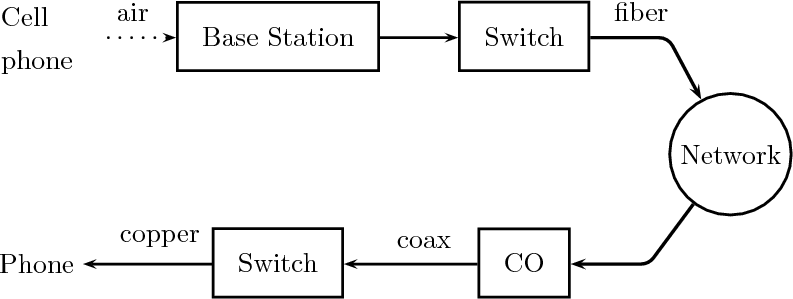
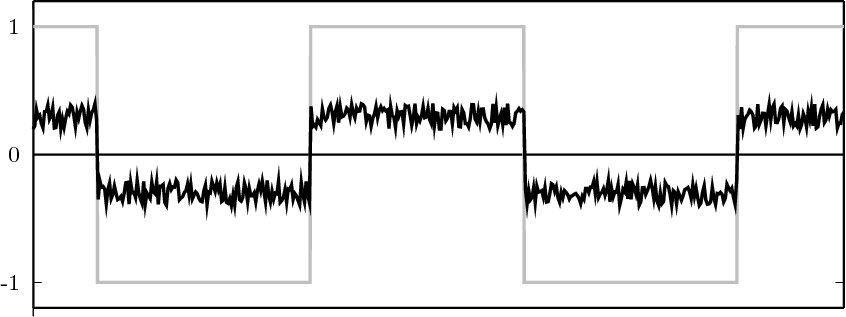




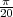
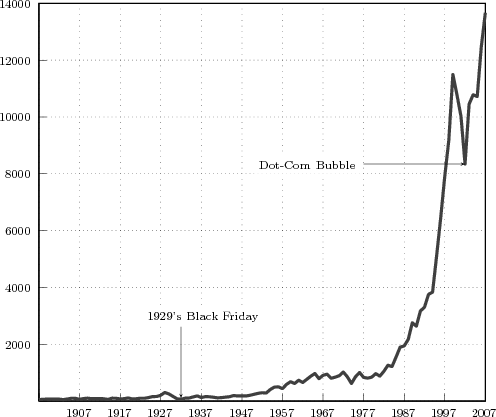



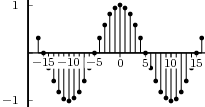
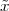 [
[
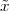 [
[
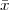 [
[
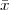 [
[
![|--------------|-----------------------|-------------|---------|
|Signal-Type---|-------Notation--------|---Energy----|-Power---|
| | | N∑-1| | | |
|Finite- Length |x[n], n = 0,1,...N,N - 1 | |x[n]|2 | undef. |
----------------------x,--x-∈ C-----------n=0-------------------
| | | | |
|Infinite- Length|------x[n],--n ∈-Z------|--eq. (2.19)--|eq. (2.20)|
| | ˜x[n], n ∈ Z | | |
|N -Periodic | ˜x[n] = ˜x[n + kN ] | ∞ |eq. (2.21)|
|--------------|-----------------------|-------------|---------|
| | ¯x[n], n ∈ Z |M+N∑ - 1 2 | |
|Finite- Support| ¯x[n] ⁄= 0 for | |x[n]| | 0 |
------------------M--≤-n ≤-M-+-N---1------n=M--------------------](livre74x.png)






 )
)
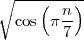

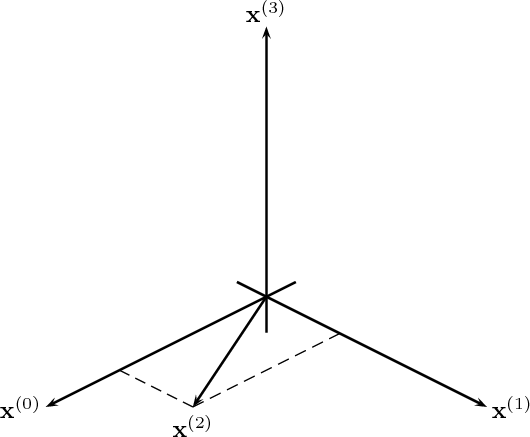
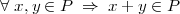
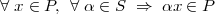

 . This
approximation minimizes the square norm
. This
approximation minimizes the square norm 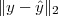 among all
approximations belonging to
among all
approximations belonging to 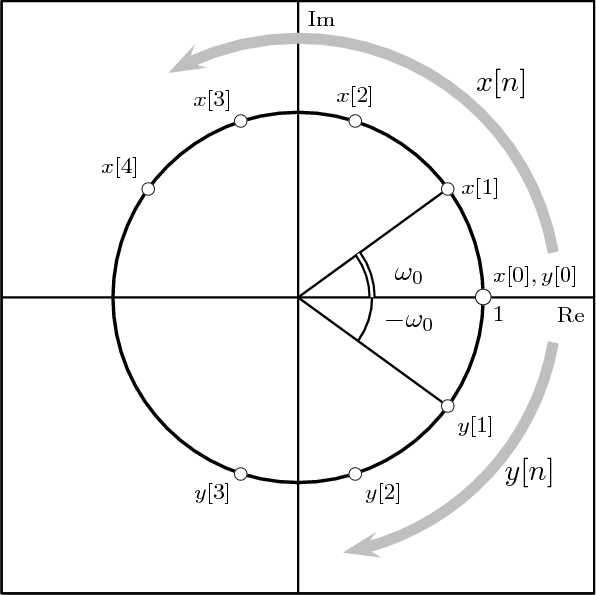









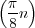











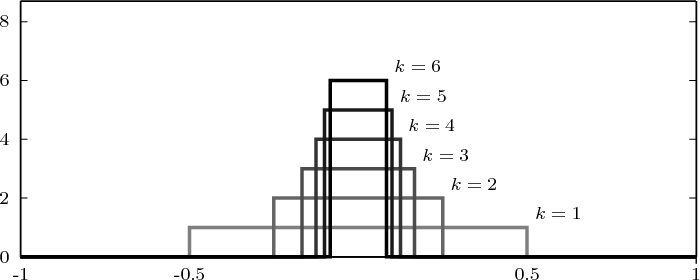
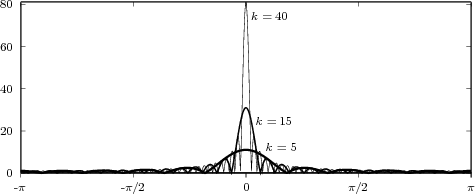


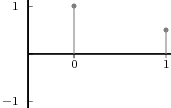
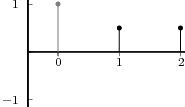
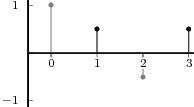
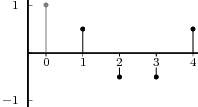
![---------------------------------------------------------------------
Discre te-Tim e Fourie r Transform (DTFT)
---------------------------------------------------------------------
used for: infinite, two sided signals (x[n] ∈ ℓ2(Z-))
∑∞
analysis formula: X (ejω) = x[n]e-jωn
n=- ∞
1-∫ π jω jωn
synthesis formula: x[n ] = 2π -πX (e )e dω
DTFT
symmetries: x[- n] ← → X (e- jω)
DTFT
x*[n] ← → X *(e-jω)
DTFT
shifts: x[n - n0] ←→ e-jωn0X (ejω )
DTFT ( )
ejω0nx[n] ←→ X ej(ω-ω0)
∞∑ | |2 1 ∫ π | |2
Parseval: |x[n]| = 2π- |X (ejω )| dω
-----------------------------n=-∞--------------π---------------------
Som e DTFT pa irs
---------------------------------------------------------------------
x[n] = δ[n - k] X (ejω) = e-jωk
x[n] = 1 X (ejω) = ˜δ(ω)
x[n] = u[n ] X (ejω) =----1---+ 1 ˜δ(ω)
1 - e-jω 2
x[n] = anu[n ], |a| < 1 X (ejω) =----1----
1 - ae-jω
jω0n jω ˜
x[n] = e X (e ) = δ(ω - ω0 )
jω 1 [ jφ ˜ -jφ ˜ ]
x[n] = cos(ω0n + φ) X (e ) = 2 e δ(ω - ω0)+ e δ(ω+ ω0)
jω --j[ jφ ˜ - jφ ˜ ]
x[n] = s{in(ω0n+ φ) X (e ) = 2 e δ(ω- ω0) - e δ(ω + ω0)
1 for 0 ≤ n ≤ N - 1 jω sin((N-∕2)ω) -jN-21ω
x[n] = 0 otherwise X (e ) = sin(ω∕2) e
---------------------------------------------------------------------
Discre te Fourie r Series (D FS)
---------------------------------------------------------------------
used for: periodic signals (˜x[n] ∈ ˜CN )
N∑ -1
analysis formula: ˜X [k] = ˜x[n ]W nNk, k = 0,...,N - 1
n=0
1 N∑- 1 -nk
synthesis formula: ˜x[n ] = N ˜X[k]WN , n = 0,...,N - 1
k=0
symmetries: ˜x[- n] D←F→S X˜[- k]
˜x*[n] D←FS→ ˜X*[- k]
shifts: ˜x[(n - n0)]←DF→S W kn0˜X[k]
N
W -nk0˜x[n] D←FS→ ˜X[(k- k0)]
N-N1 N-1
Parseval: ∑ ||˜x[n]||2 =-1 ∑ ||X ˜[k]||2
n=0 N k=0
---------------------------------------------------------------------
-Discre-te-Fourie-r Transform-(DFT)--------------------------------------
N
used for: finite support signals (x[n] ∈ C )
N∑ -1 nk
analysis formula: X [k] = x[n ]W N , k = 0,...,N - 1
n=0N- 1
synthesis formula: x[n ] = 1-∑ X[k]W -nk, n = 0,...,N - 1
N k=0 N
DFT
symmetries: x[- n mod N] ←→ X [- k mod N ]
DFT
x*[n] ← → X*[- k mod N ]
[ ] DFT
shifts: x (n - n0) mod N ←→ W kNn0X [k]
DFT [ ]
W -Nnk0x[n] ← → X (k- k0) mod N
N∑-1| | 1 N∑-1| |
Parseval: |x[n]|2 =-- |X [k]|2
-----------------------------n=0--------N--k=0-----------------------
Som e DFT p airs for length-N sig nals (n,k = 0,1,...,N - 1)
---------------------------------------------------------------------
x[n] = δ[n - k] X [k] = e-j2Nπk
x[n] = 1 X [k] = N δ[k]
x[n] = ej2πN L X [k] = N δ[k - L]
( )
x[n] = cos 2π-Ln + φ X [k] = N [ejφδ[k- L ]+ e-jφδ[k- N + L )]]
( N ) 2
x[n] = sin 2π-Ln +φ X [k] = --jN-[ejφ δ[k - L]- e-jφδ[k - N + L]]
{ N 2( )
1 for n ≤ M - 1 sin-(π∕N-)M-k- -j-π(M -1)k
x[n] = 0 for M ≤ n ≤ N - 1 X [k] = sin((π ∕N )k) e N
---------------------------------------------------------------------](livre457x.png)

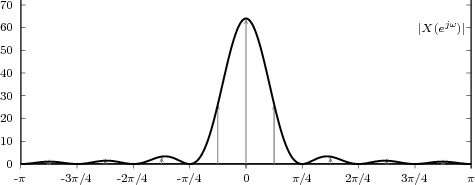





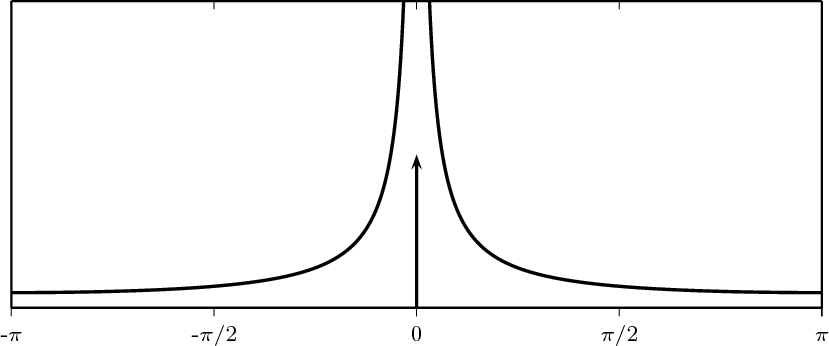
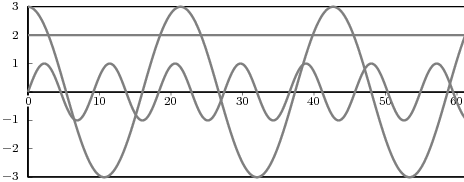












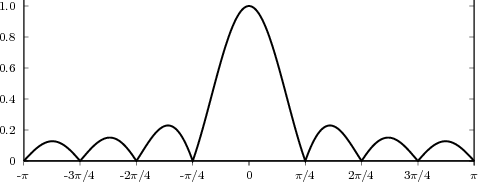
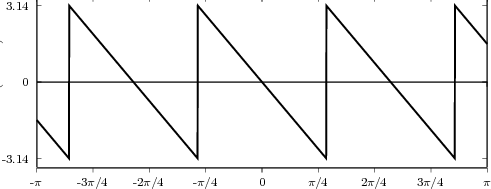
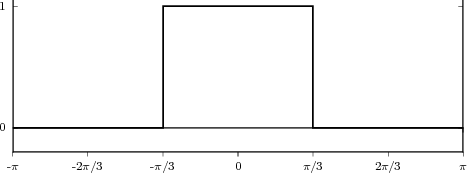


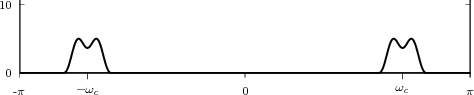

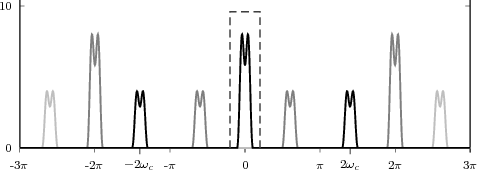
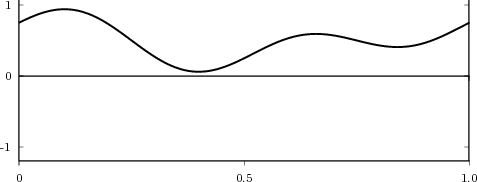
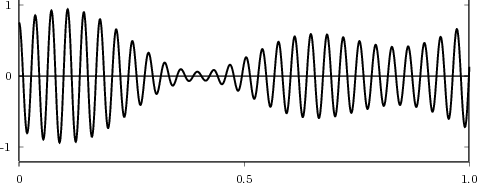
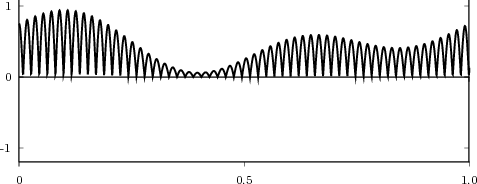
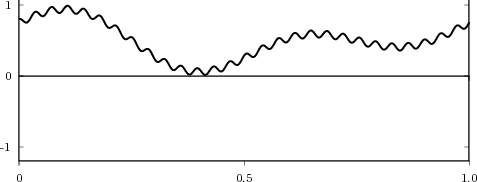
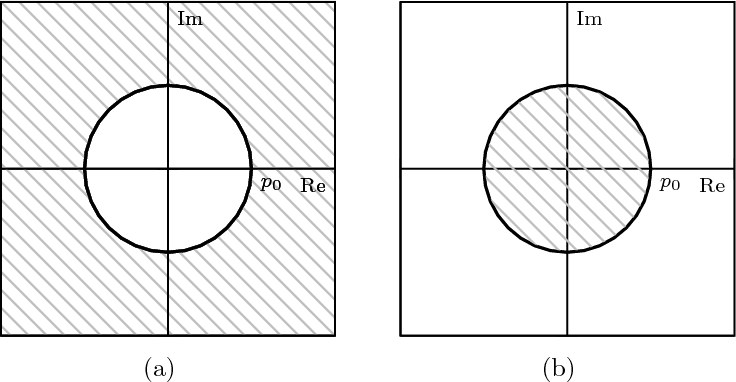
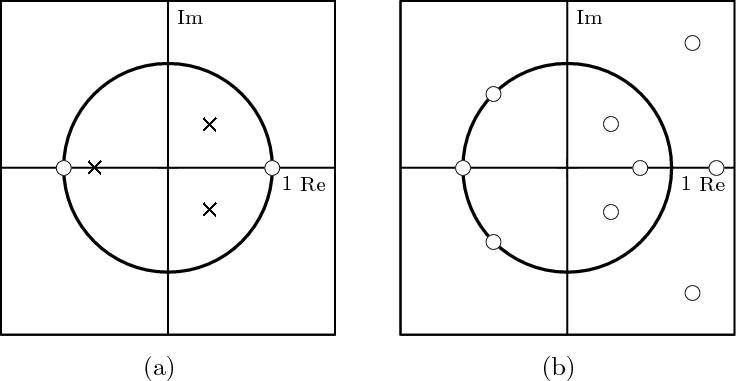
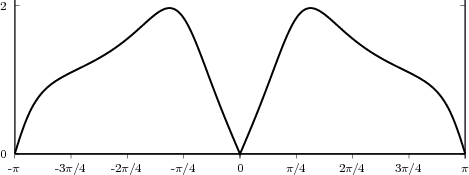
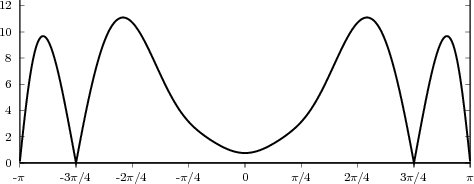
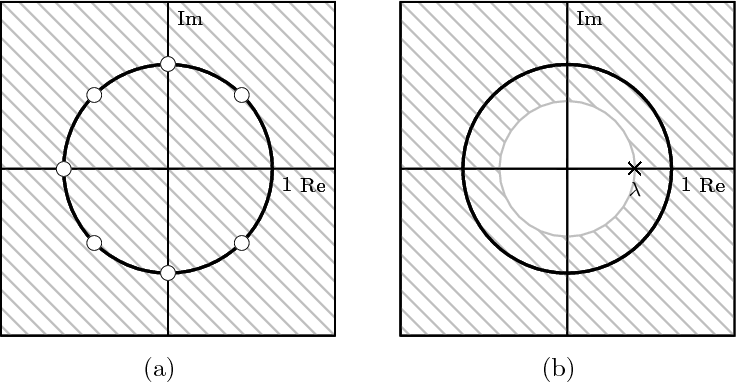













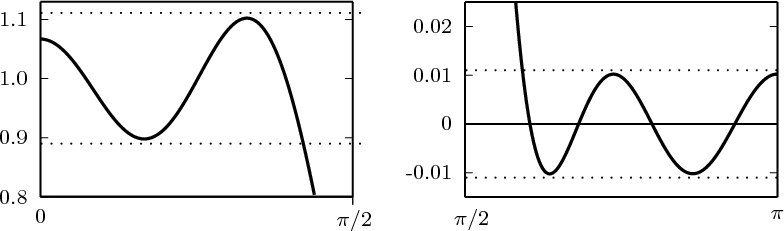

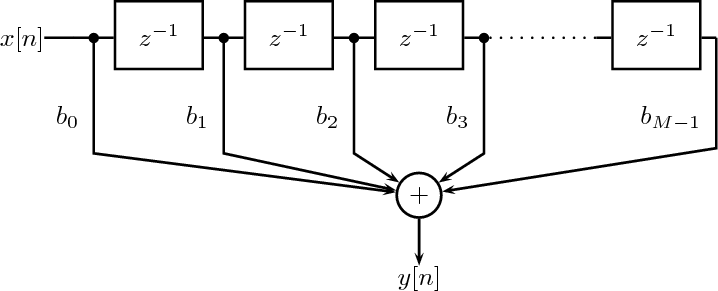

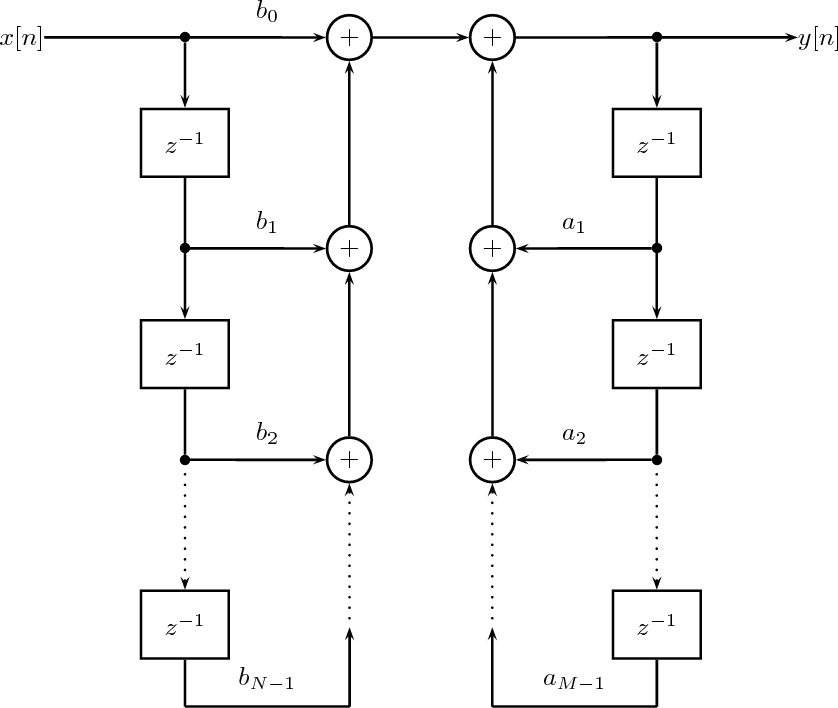
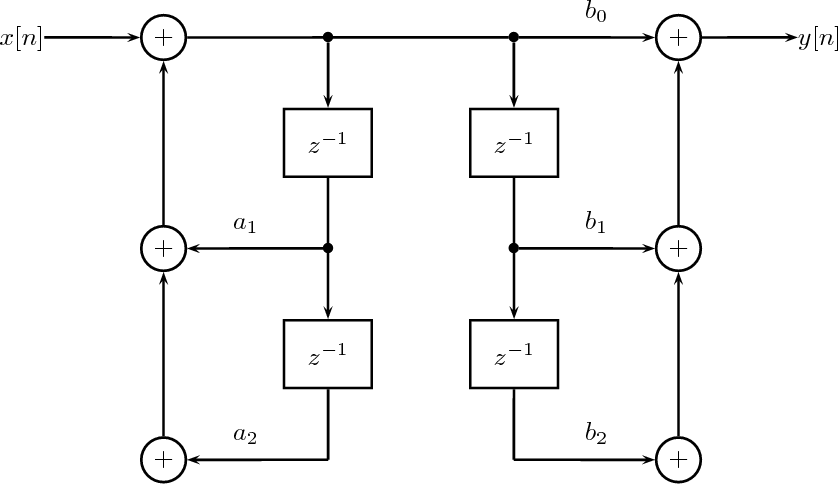
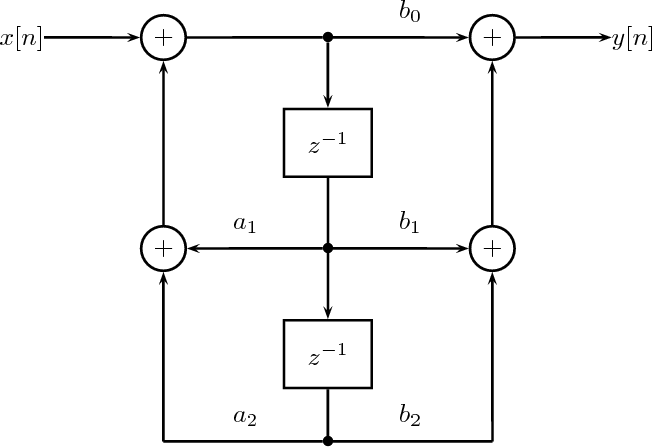
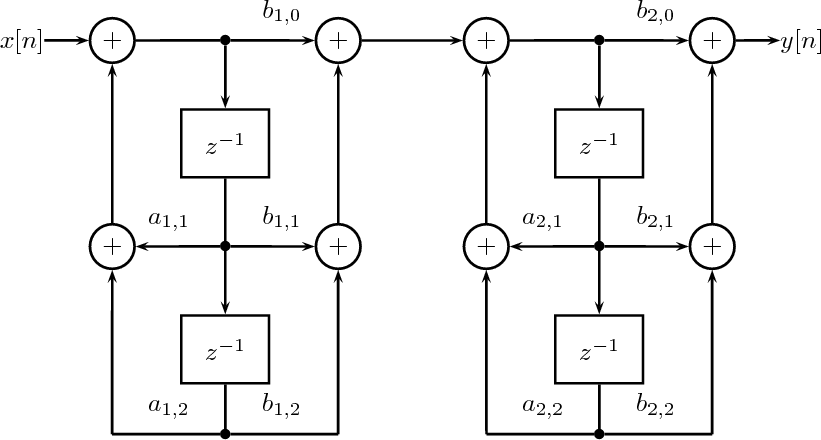
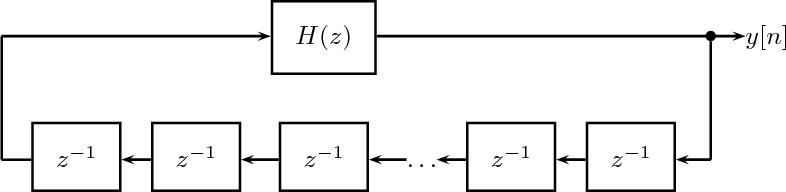
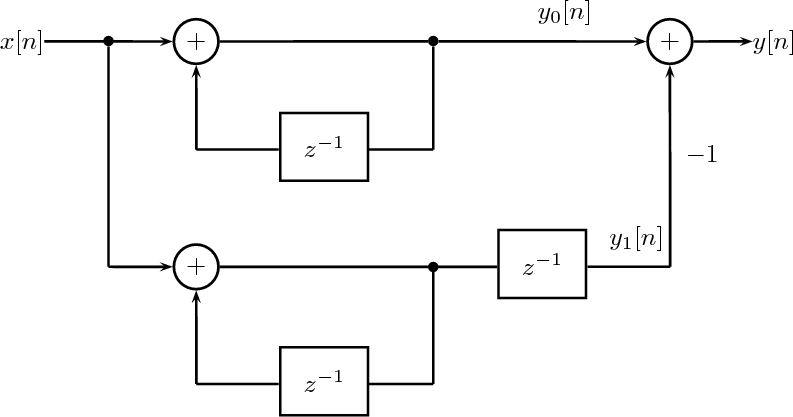
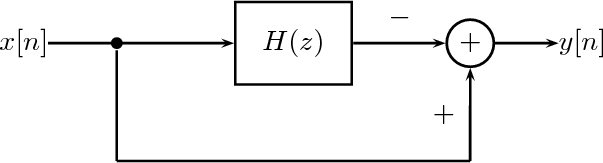
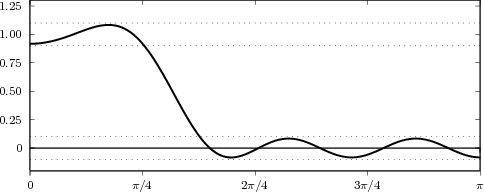



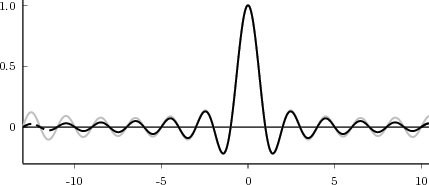
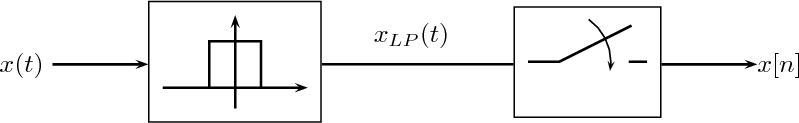

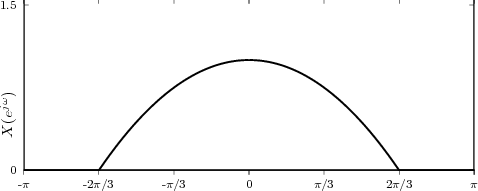
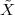

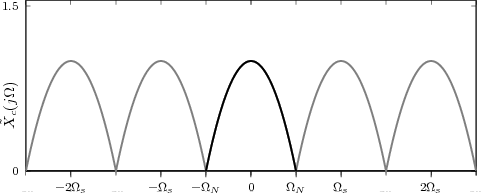

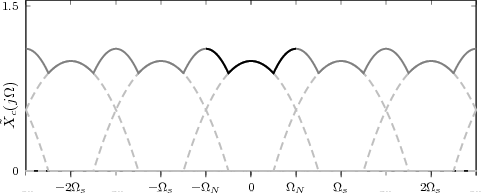
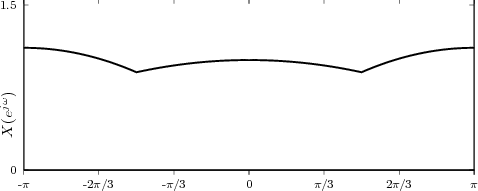
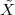

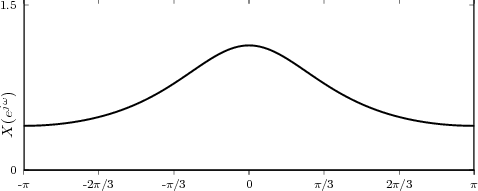
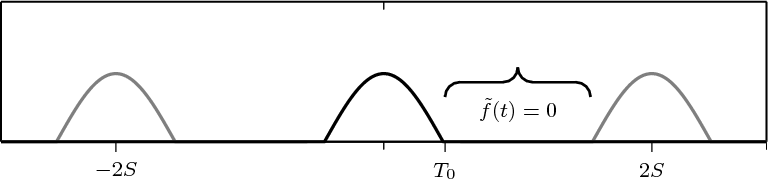
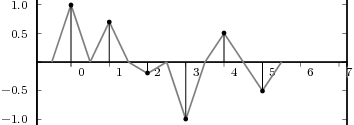



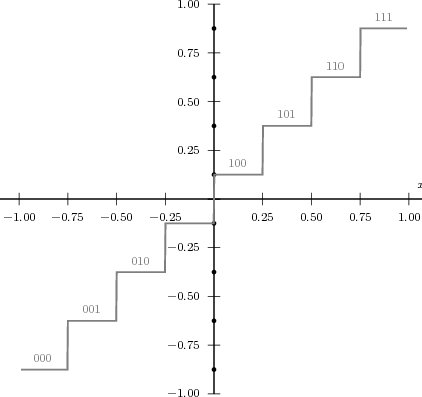
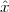 [
[
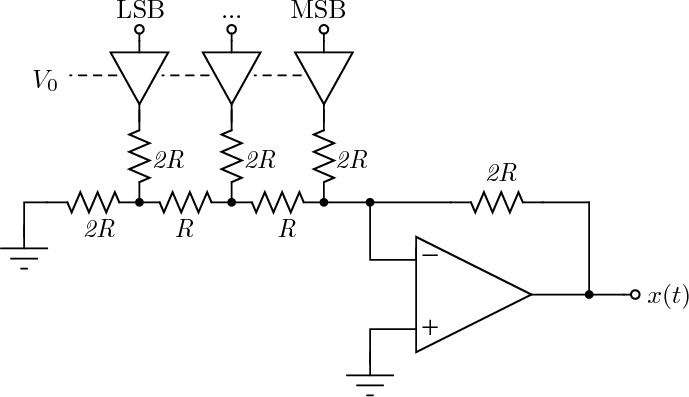
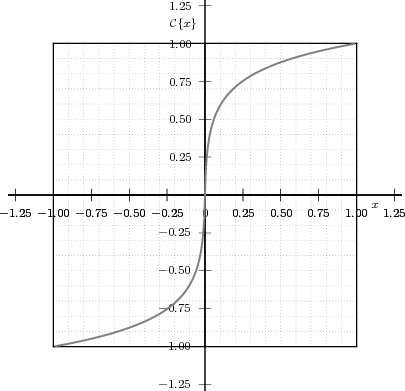

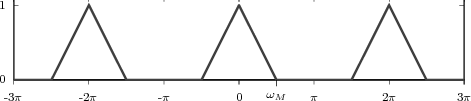
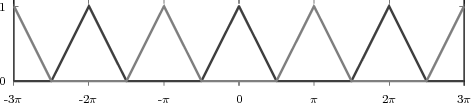


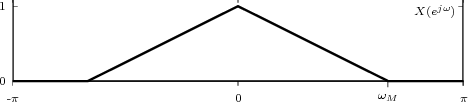

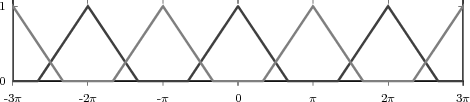
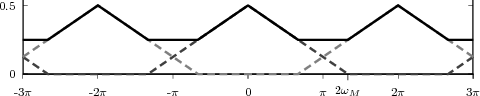



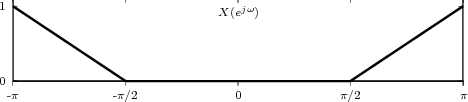
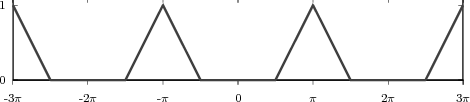
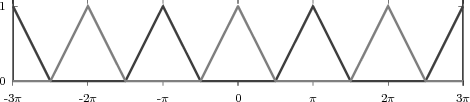
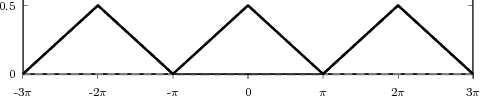
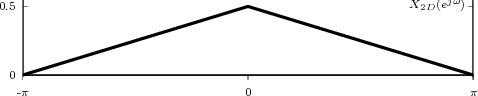
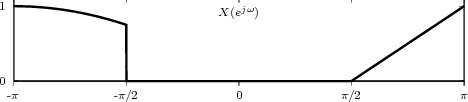

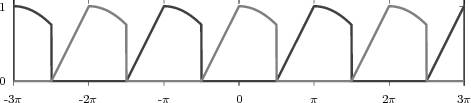








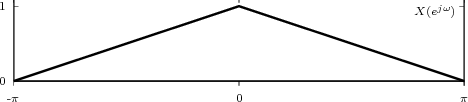
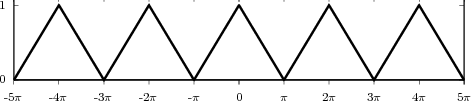
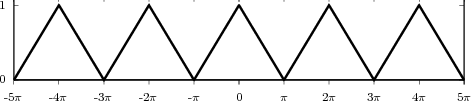
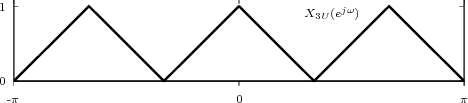

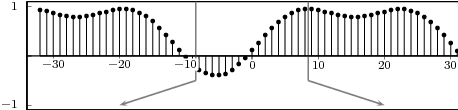
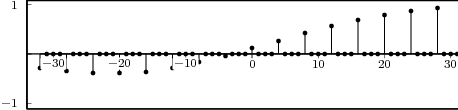

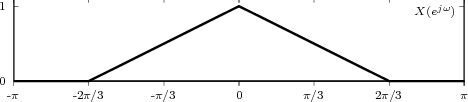
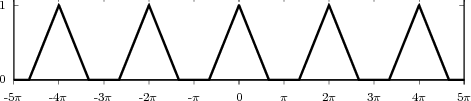

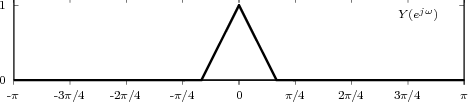
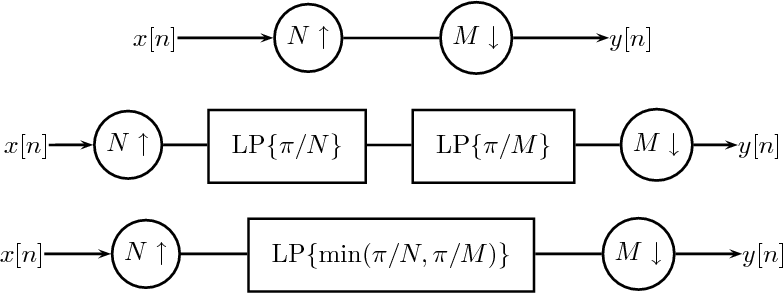
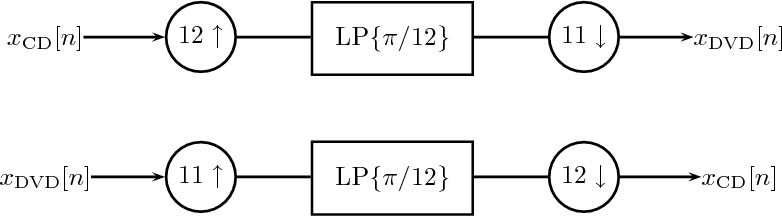





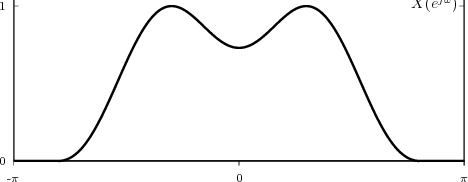
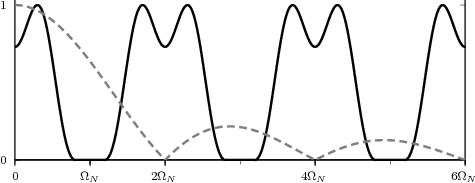

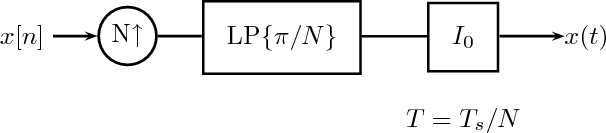
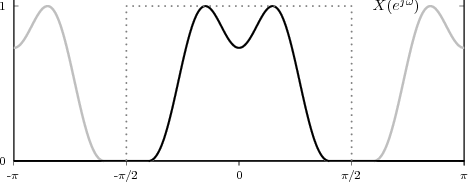
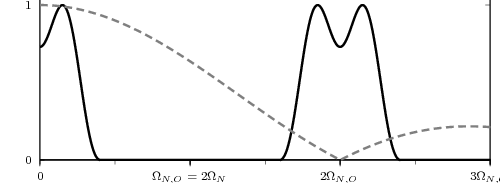

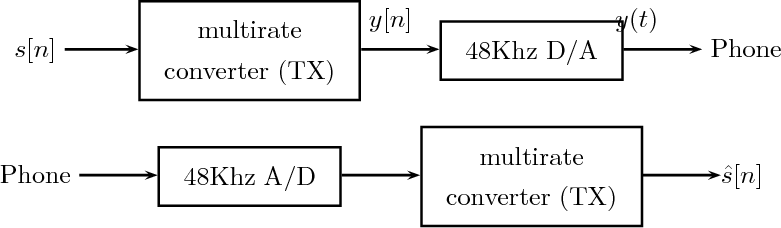
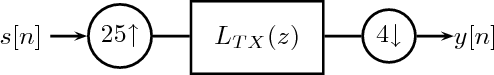
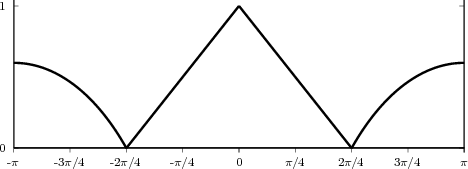
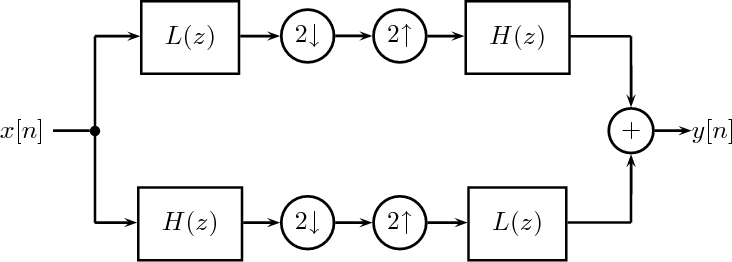
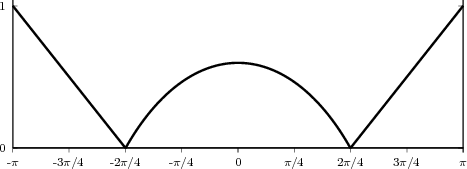
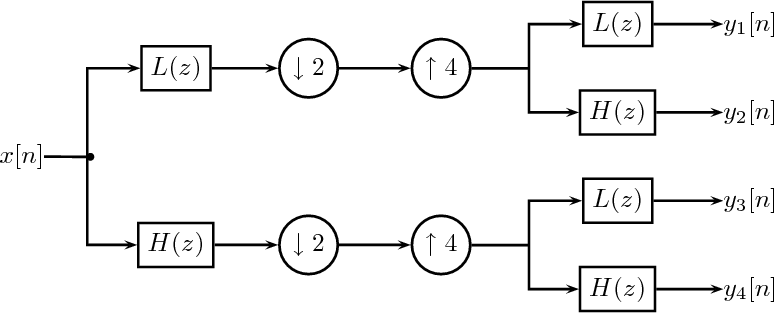
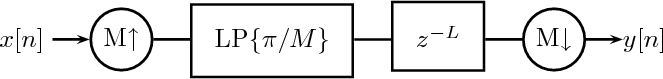
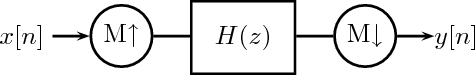
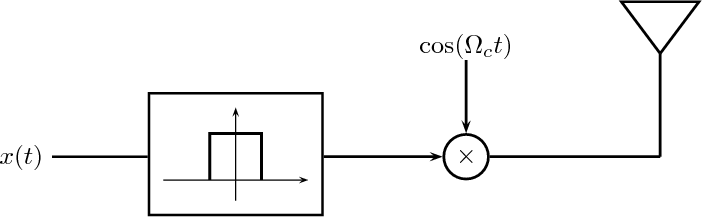
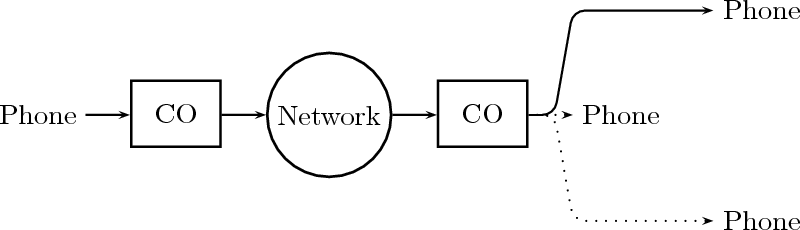



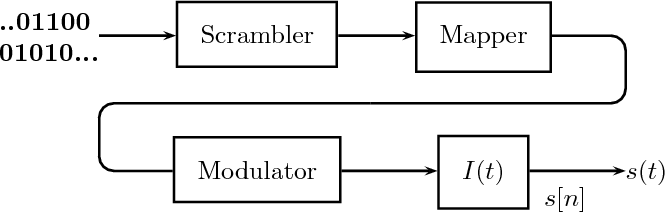
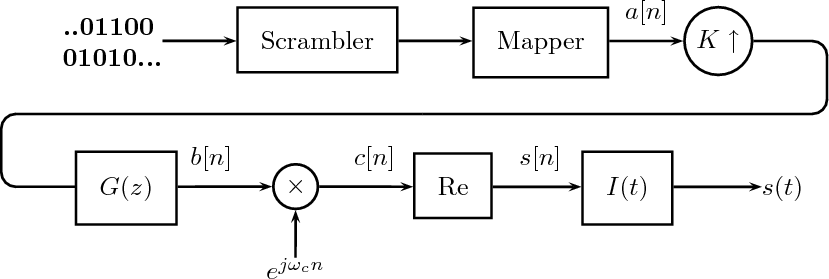

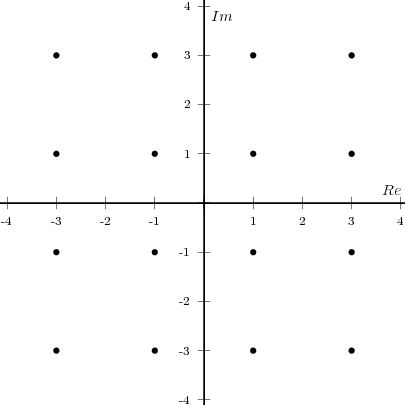
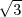 from the origin ; regular 19-point hexagonal-lattice constellation
(right panel).
from the origin ; regular 19-point hexagonal-lattice constellation
(right panel).